
File System
- 데이터를 파일로 저장하고 조직화하는 방법과 구조를 정의하는 시스템
파일
- 연속된 바이트의 집합으로 표현되며,데이터를 영구적으로 저장하기 위한 논리적 단위이다.
- 컴퓨터에서 사용하는 모든 정보(문서, 프로그램, 이미지, 동영상)는 파일로 저장된다.
파일 작업
- 파일에 수행할 수 있는 다양한 동작을 의미한다.
- 생성(create), 삭제(delete), 읽기(read), 쓰기(write), 재명명(rename), 이동(move), 수정(modify) 등이 있다.
파일 열기
- 파일을 사용하기 위한 여는 동작은 해당 파일의 정보와 내용에 접근하기 위한 준비과정이다.
파일 포인터
- 현재 파일에서의 위치(Offset)를 나타낸다.
- 파일을 순차적으로 읽거나 쓸 때마다 파일 포인터는 그 위치를 업데이트하여 다음에 접근할 위치를 나타낸다.
파일 오픈 횟수
- 특정 파일이 몇 번 열렸는지를 나타내는 카운터이다.
- 파일을 여러 프로세스나 스레드에서 동시에 열 수 있기 때문에 일부 운영체제는 파일을 동시에 여는 것을 제한한다.
디스크 위치
- 파일이 실제로 저장되어 있는 디스크의 물리적 위치를 나타내며, 운영체제와 파일 시스템은 이 정보를 통해 파일의 데이터 블록에 접근한다.
- 디스크 위치는 일반적으로 사용자나 애플리케이션에 직접 노출되지 않는다.
접근 권한
- 파일을 열 때 해당 파일에 대한 권한을 검사한다.
- 권한은 일반적으로 읽기, 쓰기, 실행 등의 형태로 제공되며, 사용자 별로 다른 접근 권한을 설정할 수 있다.
파일 유형
- 파일은 그 용도와 특성에 따라 다양한 유형이 있으며, 특정 유형의 파일을 처리하기 위한 다양한 프로그램이 있다.
실행 가능한 오브젝트
- 실행 가능한 프로그램 또는 커맨드로 변환된 소스 코드를 포함한다.
소스 코드
- 프로그램의 원시 코드를 포함하며, 일반적으로 텍스트 형식이다.
아카이브
- 여러 개의 파일이나 디렉터리를 하나의 파일로 묶은 것이다.
이미지
- 그래픽 데이터를 포함하며, 디지털 사진, 아트워크, 그래픽 디자인 등 다양한 형태의 시각적 정보를 저장한다
파일 접근
- 파일 내의 데이터에 접근하는 방식으로, 사용하는 파일의 유형이나 목적에 따라 적절한 접근 방법을 선택해야 한다.
순차적 접근
- 파일의 시작부터 끝까지 데이터를 순서대로 읽거나 쓰는 방식이다.
- 특정 위치에 접근하려면 그 위치에 도달할 때까지 파일을 순차적으로 읽거나 건너뛰어야 한다.
직접 접근
- 파일의 특정 위치에 즉시 접근하여 데이터를 읽거나 쓰는 방식이다.
- 파일 내의 임의의 위치에 빠르게 접근할 수 있기 때문에 효율적인 데이터 검색이 가능하다.
디스크
- 데이터를 저장하는 물리적 장치로, 보통 HDD(Hard Disk Drive)나 SSD(Solid State Drive)와 같은 형태이다.
- 운영체제에 따라 다양한 파일 시스템(NTFS, ext4, APFS)으로 포맷될 수 있다.
HDD(Hard Disk Drive)
- 회전하는 플래터에 데이터를 저장하며, 헤드를 사용하여 데이터에 접근한다.
- 움직이는 부품이 있는 물리적인 구조 때문에 SSD에 비해 상대적으로 느리며 충격에 민감할 수 있다.
SSD(Solid State Drive)
- 플래시 메모리를 사용하여 데이터를 저장하는 방식이다.
- 움직이는 부품이 없어 HDD보다 상대적으로 속도가 빠르며 물리적인 충격에 덜 민감하다.

파티션
- 단일 물리적 디스크를 여러 개의 독립적인 부분으로 분할하는 것으로, 각 파티션은 마치 독립된 디스크처럼 동작한다.
파일 시스템
- 파티션을 포맷할 때 특정 파일 시스템으로 설정하게 되며, 이를 통해 운영체제는 해당 파티션에 데이터를 저장하거나 접근할 수 있다.
데이터 영역
- 사용자 데이터(파일, 디렉터리)와 파일 시스템의 메타데이터가 저장되는 부분으로, 파일 시스템의 유형에 따라 내부 구조와 관리 방식이 다를 수 있다.
스왑 영역
- 컴퓨터의 RAM이 가득 찼을 때 사용되는 디스크의 일부 영역으로, RAM에서 사용되지 않는 데이터나 프로세스를 임시로 저장하여 RAM을 확보하는 역할을 한다.
원시 모드 데이터 장치
- 파일 시스템 없이 디스크나 파티션에 직접 데이터를 읽거나 쓸 수 있도록 하는 인터페이스이다.
파일 시스템
- 데이터를 구조화하고, 물리적인 저장 공간을 관리하며, 사용자와 프로그램 간의 인터페이스 역할을 한다.
- 특정 운영 체제에 최적화되어 있는 여러 유형의 파일 시스템이 있으며, NTFS(Windows), ext4(Linux), APFS(macOS), FAT32, exFAT 등이 있다.
파일 시스템 구조
- 다양한 파일 시스템마다 구조와 구현 방식이 조금씩 다를 수 있지만, 대부분의 파일 시스템은 일련의 공통된 기본 구성 요소를 가지고 있다.
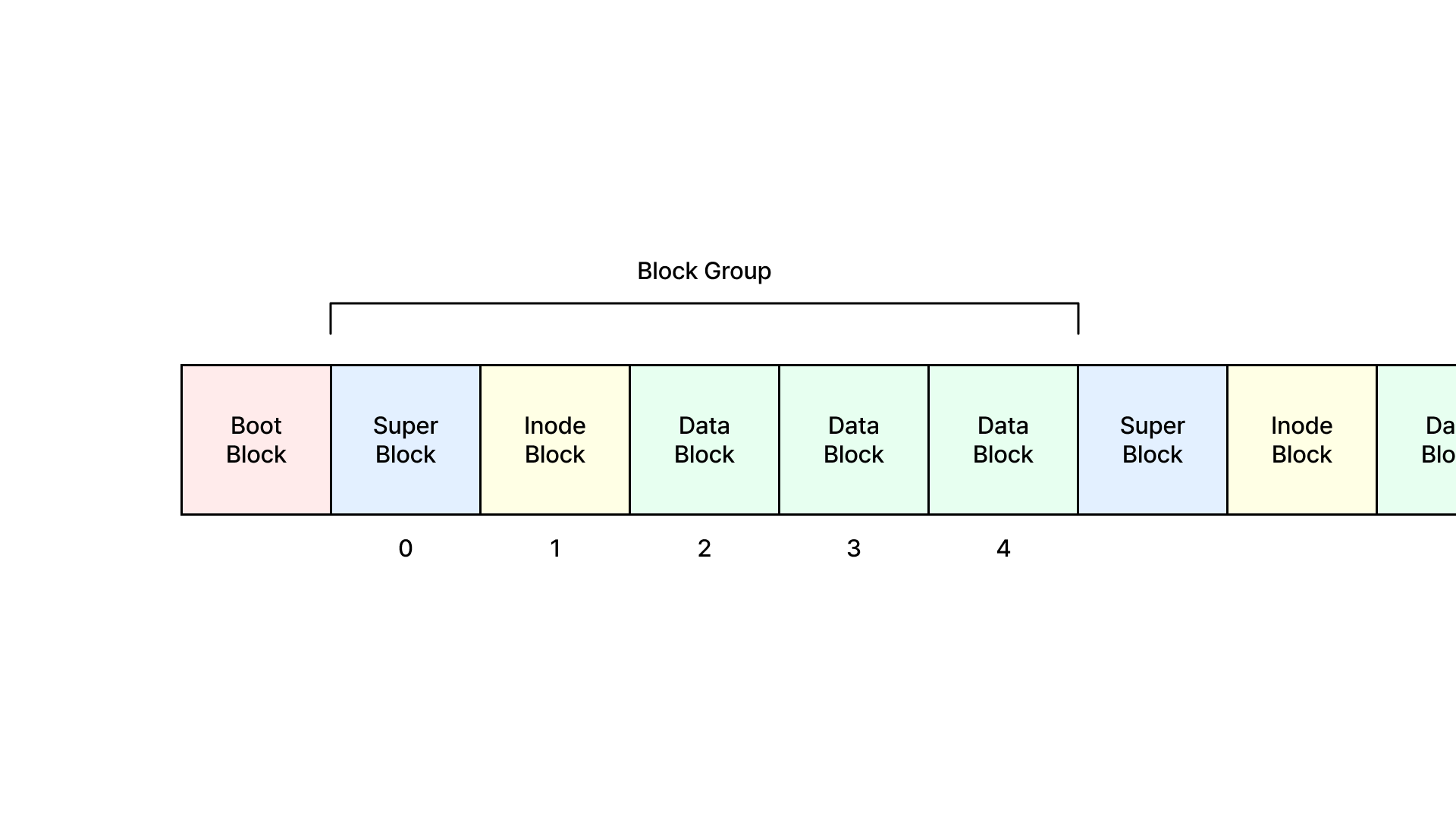
부트 블록(Bood Block)
- 파일 시스템의 가장 처음 영역에 위치하여 운영체제를 로드하기 위해 실행되는 첫 번째 코드를 저장한다.
- 시스템 부팅 시 필요한 초기화 코드, 부트로더 코드를 포함한다.
슈퍼 블록(Super Block)
- 파일 시스템의 전반적인 정보를 담고 있는 구조이다.
- 파일 시스템의 크기, 블록의 크기, 사용 가능한 블록의 수, 사용 중인 블록의 수, 파일 시스템의 마운트 상태 등의 정보를 포함한다.
인덱스 노드(Inode)
- 파일이나 디렉터리의 메타데이터를 저장하는 데이터 구조이다.
- 메타데이터에는 파일의 크기, 타임스탬프(생성일, 수정일), 권한, 파일의 데이터 블록 위치 등의 정보가 포함된다.
데이터 블록(Data Block)
- 실제 파일 데이터는 데이터 블록에 저장된다.
- 파일 시스템은 이 블록들을 관리하여 파일 데이터를 저장하거나 검색한다.
저널링(Journaling)
예기치 않은 시스템 중단이 발생할 경우, 저널을 사용하여 파일 시스템을 빠르게 복구할 수 있는 기능이다.
파일 시스템 마운팅과 구현
- 저장 장치나 파티션의 파일 시스템을 운영 체제에 연결하여 사용 가능하게 만드는 과정이다.
마운트 포인트
- 마운트는 특정 디렉터리에 연결되며, 이 디렉터리를 마운트 포인트라고 한다.
- 사용자는 이 디렉터리를 통해 마운트된 파일 시스템에 접근한다.
파일 시스템 구현
- 주로 커널 내부에서 이루어지며 데이터의 영구 저장과 효율적인 접근 방법들을 제공한다.
파일 제어 블록(File Control Block, FCB)
- Inode라고도 불리며, 파일의 여러 가지 속성과 메타데이터를 저장하는 중요한 구조체이다.
- 이러한 정보는 파일을 관리하고, 접근 제어, 데이터 블록 위치 조회, 파일 연산 수행 등의 작업을 수행할 때 필요하다.
파일 식별자
- 파일을 식별하기 위한 인덱스로, UNIX 시스템에서는 이를 Inode 번호로 참조한다.
파일의 크기
- 파일에 저장된 데이터의 총 바이트 수이다.
파일의 위치
- 파일 데이터 블록의 위치나, 데이터 블록에 대한 포인터를 포함한다.
접근 권한
- 파일에 대한 읽기, 쓰기, 실행 권한 등의 정보로, UNIX 시스템에서는 사용자, 그룹, 기타 세 가지 카테고리로 나누어 권한을 관리한다.
타임스탬프
파일의 생성 시간, 최종 수정 시간, 마지막 접근 시간 등의 시간 관련 정보이다.
소유자 및 그룹 정보
- 파일의 소유자와 관련 그룹을 나타내는 정보이다.
링크 수
- UNIX 시스템에서, 하나의 파일을 참조하는 하드 링크의 수를 나타낸다.
파일 사용
- 읽기, 쓰기와 같이 디스크에 저장된 데이터에 접근하고 수정하는 주요 동작들이 있다.
파일 열기
- FCB와 같은 파일의 메타데이터를 조회하여 파일을 열고 파일 사용을 시작한다.
파일 읽기
- 파일에서 데이터를 가져와 메모리에 로드하는 과정으로, 파일 디스크립터를 사용하여 파일의 현재 위치에서 읽기를 시작하고 읽은 데이터는 버퍼에 저장된다.
- 읽기가 완료된 후, 파일의 포인터는 읽은 바이트 수만큼 이동하고, 파일의 끝에 도달하거나 요청된 바이트 수를 읽을 때까지 계속된다.
파일 쓰기
- 메모리의 데이터를 파일에 기록하는 과정으로, 파일의 현재 위치에 쓰기 시작하며 파일의 포인터는 기록된 바이트 수만큼 이동한다.
- 파일이 일정 크기로 제한되어 있지 않은 경우, 쓰기 연산은 파일의 크기를 늘릴 수 있다.
파일 닫기
- 작업이 끝나면 파일이 닫혀야 하며, 이 과정에서 파일에 대한 모든 리소스를 해제하고 열려있는 파일 목록에서 해당 파일을 제거한다.
디렉터리
- 디렉터리는 파일과 다른 디렉터리의 이름 및 위치 정보를 저장하는 데이터 구조로, 파일과 폴더를 조직화한다.
디렉터리 구성
- 디렉터리는 '이름-값' 쌍의 몰록 형태로 구성되어 있다.
- '이름'은 파일 또는 하위 디렉터리의 이름이며, '값'은 파일의 메타데이터를 가리키는 포인터나 Inode 번호와 같은 식별자이다.
디렉터리 검색
- 디렉터리 항목을 처음부터 끝까지 순차적으로 검색하는 '선행 검색' 방법이 있다.
- 파일 이름을 해싱하여 디렉터리 내의 특정 위치를 직접 찾는 '해시 검색' 방법이 있다.
경로명 해석
- 운영체제는 디렉터리 경로를 사용하여 파일을 찾는다.
- 루트 디렉터리부터 시작하는 절대 경로(
/home/user/documents/file.txt)와 현재 위치를 기준으로 한 상대 경로가(./documents/file.txt)가 있다.
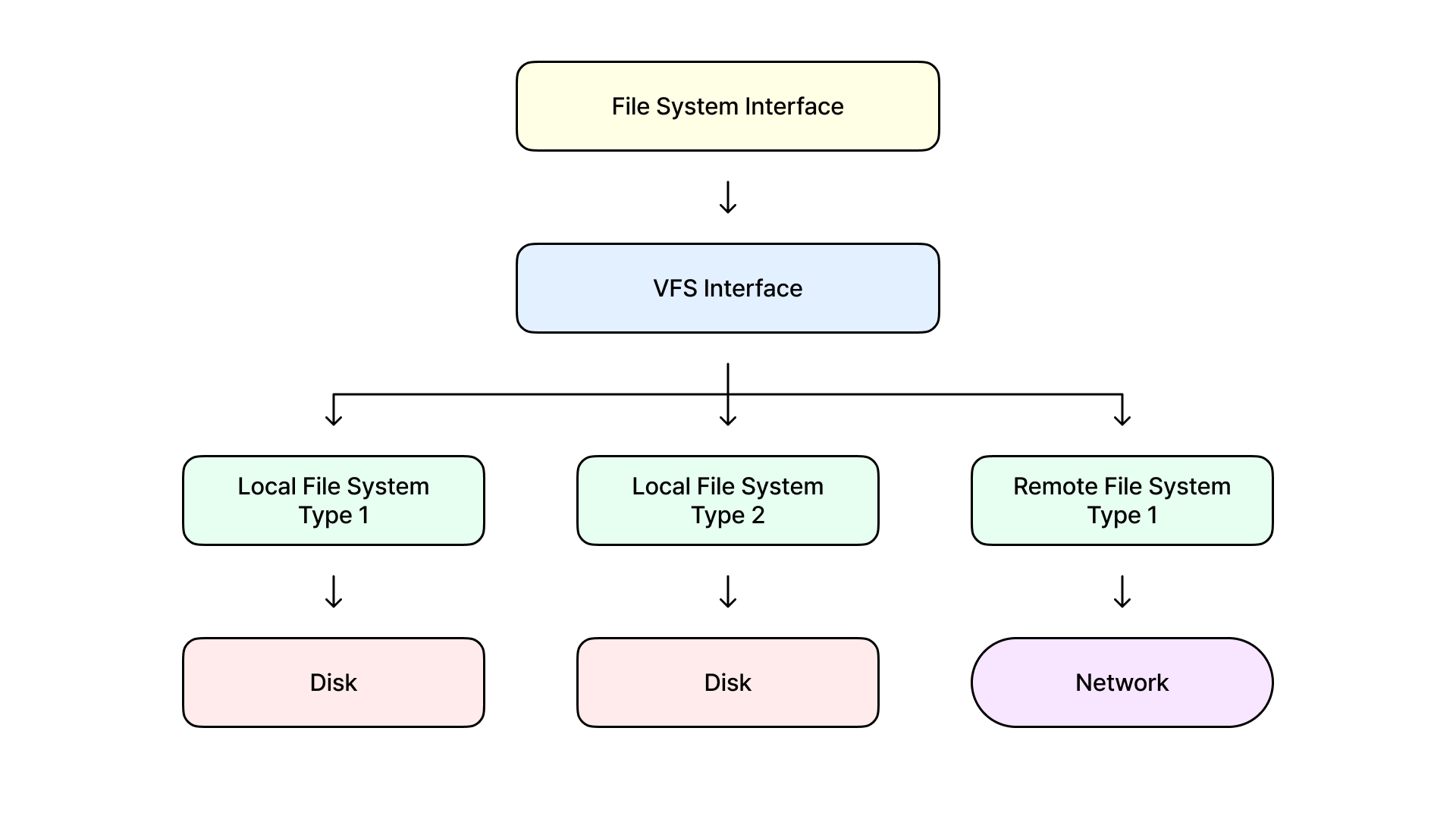
가상 파일 시스템(Virtual File System, VFS)
- 커널에 포함된 추상화 레이어로서 다양한 종류의 파일 시스템을 단일 인터페이스 아래에 통합한다.
- 사용자와 프로그램은 실제 파일 시스템의 종류나 특성에 관계없이 일관된 방식으로 파일과 디렉터리에 접근할 수 있다.
추상화
- 다양한 파일 시스템에 대해 일반적인 인터페이스를 제공하여 운영 체제가 동일한 방식으로 처리할 수 있다.
동적 마운팅
- VFS를 통해 운영 체제는 새로운 파일 시스템을 동적으로 인식하고 마운트할 수 있다.
파일 할당 방법
- 데이터의 효율성, 성능, 디스크 공간 활용 등의 측면을 고려하여, 디스크에 파일을 어떻게 저장할 것인지 결정하는 방식이다.
연속 할당(Contiguous Allocation)
- 각 파일을 디스크의 연속적인 블록들에 할당한다.
- 빠른 접근 속도와 간단한 구현과 같은 장점들이 있지만 디스크 조각화가 발생할 수 있고 파일 크기 변경에 어려움이 있다.
연결 할당(Linked Allocation)
- 파일을 여러 개의 블록으로 나누고 각 블록은 다음 블록을 가리키는 링크 정보를 포함한다.
- 디스크 공간을 효율적으로 활용할 수 있고 파일 크기를 변경하기 용이하지만, 접근 속도가 저하되고 링크의 손상 가능성이 있다.
인덱스 할당 (Indexed Allocation)
- '인덱스 블록'을 사용하여 파일의 각 데이터 블록에 대한 포인터를 저장한다.
- 접근 속도가 향상하고 디스크 공간을 효율적을 활용할 수 있지만, 작은 파일에 대한 오버헤드와 인덱스 블록 크기의 제한으로 큰 파일에 대한 제약이 있다.
- 더 큰 파일을 효과적으로 관리하기 위해, 인덱스 블록이 다른 인덱스 블록을 가리킬 수 있는 다중 인덱스 할당(Multilevel Index Allocation) 방식이 있다.
연결-인덱스 혼합 할당(Combined Allocation)
- 연결 할당과 인덱스 할당의 장점을 결합한 방식으로 UNIX의 Inode 구조가 이 방식을 사용한다.
- 일정 크기 이하의 파일은 직접 블록 포인터로 관리되며, 더 큰 파일은 간접 블록 포인터를 통해 관리됩니다.
자유 공간 관리
- 파일 시스템 내에서 사용되지 않는 디스크 공간을 효과적으로 추적하고 관리하는 메커니즘이다.
비트맵(Bitmap)
- 디스크의 각 블록에 대해 비트 하나를 사용하여 블록의 상태를 나타낸다.
- 직접적이며 원하는 크기의 연속된 블록을 찾기 쉽지만, 비트맵 자체가 크기가 크면 메모리 소모가 크며 디스크 전체를 스캔해야 할 수도 있다.
연결 목록(Linked List)
- 사용되지 않는 블록을 연결 목록으로 관리하여 각 블록은 다음 빈 블록을 가리키는 포인터를 포함한다.
- 간단하게 구견할 수 있지만, 무작위로 빈 블록을 찾는 것이 느릴 수 있다.
그룹화(Grouping)
- 첫 번째 블록이 여러 개의 빈 블록을 가리키는 '자유 블록 그룹'을 형성한다.
- 연속적인 공간을 빠르게 찾을 수 있지만, 초기 할당 또는 빈 블록 그룹 재구성에 시간이 걸릴 수 있다.
카운팅(Counting)
- 연속된 여러 블록의 자유 공간을 나타내기 위해 시작 블록과 연속된 블록의 수를 함께 저장한다.
- 연속된 블록을 효율적으로 표현할 수 있지만, 비연속적인 블록의 관리가 복잡해질 수 있다.
디크스 스케줄링
- 디스크 I/O 요청을 처리하기 위한 전략이나 알고리즘으로, 디스크 헤드의 움직임을 최소화하고 I/O 연산의 전반적인 효율성과 반응 시간을 개선한다.
FCFS (First Come, First Served)
- 요청이 도착한 순서대로 처리된다.
- 불필요한 헤드 움직임이 많이 발생할 수 있다.
SSTF (Shortest Seek Time First)
- 현재 헤드 위치에서 가장 가까운 요청을 먼저 처리한다.
- 주변의 요청만 계속 처리되어 멀리 있는 요청이 오랫동안 대기하는 '기아' 현상이 발생할 수 있다.
SCAN (Elevator Algorithm)
- 헤드는 한 방향으로 움직이면서 요청을 처리하고, 끝에 도달하면 반대 방향으로 움직인다.
- 헤드의 움직임이 엘리베이터의 움직임과 유사하기 때문에 '엘리베이터 알고리즘'이라고도 불린다.
C-SCAN (Circular SCAN)
- SCAN과 유사하지만, 한쪽 끝에 도달하면 헤드는 반대쪽 끝으로 빠르게 이동하고 다시 스캔을 시작한다.
- 모든 요청에 대해 더 공평한 대기 시간을 제공한다.
LOOK & C-LOOK
- SCAN 및 C-SCAN과 유사하지만, 헤드는 대기 중인 요청이 더 이상 없을 때만 방향을 변경하거나 반대쪽 끝으로 빠르게 이동한다.

iOS Developer | Product Designer @snacknam