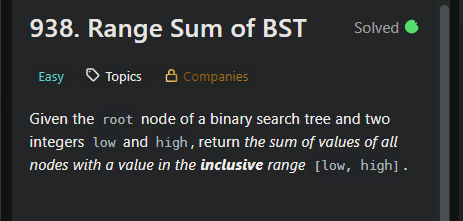
이진 탐색 트리가 주어졌을 때 low 이상 high 이하의 값을 지닌 노드의 합을 구하라.
1️⃣ 내 코드
// Runtime 0ms, Beats 100.00% / Memory 51.18MB, Beats 75.71%
class Solution {
int sum;
boolean end;
public int rangeSumBST(TreeNode root, int low, int high) {
if (root.left != null) rangeSumBST(root.left, low, high);
if (root.val >= low && root.val <= high) sum += root.val;
if (end == true) return sum;
if (root.val > high) {
end = true;
return sum;
}
if (root.right != null) rangeSumBST(root.right, low, high);
return sum;
}
}중위 순회를 하면서 노드 값이 high보다 커지면 end 플래그로 전역 조기 종료를 건다. 다만, 비효율적인 점은 node.val < low일 때도 왼쪽 서브트리를 무조건 먼저 순회해서 불필요한 순회가 발생한다는 것이다.
2️⃣ 책 코드
🟧 A
재귀 구조 DFS로 브루트 포스 탐색DFS로 전체를 탐색한 다음, 노드의 값이 low와 high 사이일 때만 값을 부여하고 아닐 경우에는 0을 취해 계속 더해나간다.
// Runtime 1ms, Beats 45.62% / Memory 51.66MB, Beats 16.01%
class Solution {
public int rangeSumBST(TreeNode root, int low, int high) {
if (root == null) return 0;
int result = 0;
if (low <= root.val && root.val <= high) result = root.val;
//자식 노드 재귀 DFS 진행
result += rangeSumBST(root.left, low, high);
result += rangeSumBST(root.right, low, high);
return result;
}
}이 방식은 모든 노드를 탐색하는 브루트 포스 풀이다.
전위 순회(Pre-order Traversal)한다.
내 풀이는 중위 순회이지만 브루트 포스 DFS라는 점에서 이 풀이와 비슷한 방식이다.
🟨 B
DFS 가지치기로 필요한 노드 탐색DFS로 탐색하되 low, high의 조건에 해당하지 않는 가지(branch)는 쳐내는(Pruning) 형태로 탐색에서 배제하도록 구현한다.
// Runtime 0ms, Beats 100.00% / Memory 51.82MB, Beats 9.19%
class Solution {
public int rangeSumBST(TreeNode root, int low, int high) {
if (root == null) return 0;
// 어차피 low 미만이면 왼쪽은 전부 더 작아서 오른쪽만 순회
if (root.val < low) return rangeSumBST(root.right, low, high);
if (root.val > high) return rangeSumBST(root.left, low, high);
return root.val
+ rangeSumBST(root.left, low, high)
+ rangeSumBST(root.right, low, high);
}
}
low <= root.val <= high이면 return에 그 노드를 포함하며 왼쪽 자식, 오른쪽 자식 모두 순회한다. 그 범위가 아니면 그 범위에 가까운 한쪽 자식만 순회할 수 있게 리턴한다.
위 트리를 예로 들었을 때 3이 쓰여진 노드는 아예 들르지 않는다.
결국, 전위 순회를 하되 조건에 따라 일부 서브트리를 아예 방문하지 않는 방식으로 순회한다.
🟩 C
반복 구조 DFS로 필요한 노드 탐색직관적으로 이해하기에 더 쉬운 반복구조로 풀어 보자.
// Runtime 2ms, Beats 13.36% / Memory 51.62MB, Beats 16.01%
class Solution {
public int rangeSumBST(TreeNode root, int low, int high) {
// 반복 구조 DFS 구현을 위한 스택 선언
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root); // 스택에 루트부터 삽입
int result = 0;
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
// 노드 값이 low보다 크면 더 작아도 되므로 왼쪽 자식 노드 스택에 삽입
if (node.val > low)
if (node.left != null) stack.push(node.left);
if (node.val < high)
if (node.right != null) stack.push(node.right);
if (low <= node.val && node.val <= high)
result += node.val;
}
return result;
}
}노드 값을 low 또는 high와 비교해 유효한 노드만 스택에 집어 넣는다. 유효한 노드만 삽입하는 형태이기 때문에 B 풀이에서의 가지치기와 탐색 범위가 유사하다.
B 풀이는 유효하지 않은 노드일 때 유효한 노드를 찾아 나서서 확인하는 형태이고,
C 풀이는 유효할 가능성이 있는 노드를 스택에 삽입하면서 확인하는 형태다.
🟪 D
반복 구조 BFS로 필요한 노드 탐색// Runtime 2ms, Beats 13.21% / Memory 50.46 MB, Beats 98.10%
class Solution {
public int rangeSumBST(TreeNode root, int low, int high) {
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int result = 0;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node.val > low)
if (node.left != null) queue.add(node.left);
if (node.val < high)
if (node.right != null) queue.add(node.right);
if (low <= node.val && node.val <= high)
result += node.val;
}
return result;
}
} ArrayDeque와 LinkedList 크기별 메모리 효율 비교
➕ 큐로 LinkedList 대신에 ArrayDeque를 썼을 때
Runtime 2ms, Beats 13.21%, Memory 51.29MB, Beats 59.42%가 나왔다.
LinkedList일 때 메모리 측면에서 결과가 더 잘 나온 이유는 뭘까?
🗄️ ArrayDeque는 내부적으로 2의 거듭제곱 크기의 배열을 사용하고 꽉 차면 2배로 확장한다.
🪢 LinkedList는 요소 수만큼 Node 객체를 만들고, 각 노드는 3개의 참조 필드(본인, 이전, 다음)를 가진다.
노드 수가 많아질수록 객체 수가 늘어나고, 참조 오버헤드 때문에 ArrayDeque보다 불리해질 수 있다.
그러므로,
큐 길이가 적을 때 : LinkedList가 초기 고정 배열 오버헤드가 없으니 유리할 수 있음
큐 길이가 커질 때 : ArrayDeque가 객체 오버헤드 없이 연속 배열만 쓰기 때문에 더 유리해짐
이 문제에서 rangeSumBST()는 node.val 비교로 좌우 자식 중 필요한 쪽만 탐색하기 때문에 큐에 쌓이는 노드 수가 대부분 작게 유지된다.
그 경우 ArrayDeque의 초기 용량이 상대적으로 낭비로 잡히고, LinkedList는 필요한 만큼만 Node를 생성하니 측정상 메모리가 더 적게 나올 수 있다.
