
Leetcode 104. Maximum Depth of Binary Tree
1️⃣ 내 풀이 ver. 1
풀이만을 참고하자면 2번, 3번을 참고하는 것이 좋다.
내가 푼 풀이가 모범 풀이는 아니지만,
나름대로 코드를 설계하고 코드의 동작 및 부족한 점을 탐구하여 리팩토링한 과정을 담았다.
class Solution {
public int maxDepth(TreeNode root) {
int depth = 0;
int[] result = new int[1];
result[0] = 0;
dfs(root, depth, result);
return result[0];
}
private void dfs(TreeNode node, int depth, int[] result) {
if (node == null) {
if (result[0] < depth) result[0] = depth;
return;
}
depth += 1;
dfs(node.left, depth, result);
dfs(node.right, depth, result);
}
}
🔍 코드 설명
🔹 로직
📌 비교를 통해 지금까지의 최대 깊이를 저장한다.
이 방식으로 누적 최대 깊이를 반환한다.dfs()에서 매개변수로 받은 node가 null이면 아직 depth++;하기 전이므로 그 시점의 depth를 결과를 담는 int[] result에 넣는다.
이 동작은 리프노드의 자식에 다다랐을 때마다 행해진다.
depth를 세아려서 리프노드의 자식까지 갔을 때 지금까지 중 가장 깊은 depth를 result[]에 남긴다.
왼쪽 가지를 dfs()한다.
가장 깊은 왼쪽 가지가 끝나면 그 오른쪽 가지도 들른다.
즉, 전체적으로 트리를 💫전위 순회(pre-order traversal)하게 된다.
🔹 혹시 NullPointerException이 발생하지 않을까?
<Input: root = [3,9,20,null,null,15,7]
Output: 3
문제에서 입출력 예시를 보면 위처럼 쓰여 있으므로
Input에서 맨 뒷부분에 null이 없는 점이 의아했다.
그래서 null은 자리 차지하기 위한 용도로만 있고 어떤 리프 노드의 자식은 null이 아닐 수도 있는 건가라고 헷갈렸다. (node.left나 node.right가 존재하지 않는 필드일 수도 있지 않을까) 하지만 그렇지 않다.
// Definition for a binary tree node.
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
문제에서 주어진 TreeNode class를 보면 인스턴스 변수로 left와 right가 있다.
Java의 특성 상 리프노드가 선언되면 left, right가 명시적으로 초기화되지 않아도 null로 자동 초기화된다.
즉, node에 null이 아닌 값이 있으면 node.left나 node.right는 null로라도 존재한다.
이러한 특성 때문에 node.left나 node.right를 접근했을 때 NullPointerException이 뜨지 않고 정상 작동한다.
하지만 JavaScript나 Python에서는 그렇지 않기 때문에 내가 쓴 코드 같은 방식으로 작성하면 NPE에 해당하는 에러가 뜬다. (JS의 경우 TypeError, Python의 경우 AttributeError)
🔹 결과는 그냥 정수인데 왜 int 배열로 만들었나?
🗣️ Question "이 코드는 result[0]을 리턴한다.
result 배열이라 해봤자 length가 1인데 그냥 int형으로 만들면 됐던 거 아니냐?"
💬 Answer
int는 primitive type이라 메서드에 넘겨줄 때 값 자체가 복사되고 int[]형 변수의 경우 참조 변수라 참조값이 복사된다는 차이가 있다.
Java는 변수를 매개 변수로 넘겨줄 때 항상 pass-by-value로 함수에 전달된다.
즉, int 같은 primitive type의 경우 전달될 때 값 자체가 복사되고 참조 변수의 경우 참조값 자체가 복사된다.
int[] result 대신에 int result로 했다면
private void dfs(TreeNode node, int depth, int result) { ... } 에서 값이 복사되므로 dfs()안에서 result = depth;를 해도 메서드 밖에서 변화가 없다. 따라서 원본인 result는 계속 0이다.
하지만 배열은 참조 변수에 담기므로 int[] result를 전달하면 참조값이 복사된다.
⚠️ 근데 이처럼 참조값을 통해 외부의 result 배열을 수정하면 side-effect가 발생할 수 있으며, 외부 상태 의존하는 코드는 디버깅, 테스트, 확장에 있어서 불리하다.
그리고 그렇게 쓰느니 그냥 아래처럼 클래스 필드를 만들어 쓰는 게 낫다.
1️⃣-2️⃣ 내 풀이 ver. 2
class Solution {
private int maxSoFar; // 지금까지의 최대 깊이
public int maxDepth(TreeNode root) {
maxSoFar = 0;
dfs(root, 0); // 현재 깊이 0에서 시작
return maxSoFar; // 누적된 최대 깊이 반환
}
private void dfs(TreeNode node, int depth) {
if (node == null) {
if (maxSoFar < depth) maxSoFar = depth; // 갱신
return;
}
depth += 1;
dfs(node.left, depth);
dfs(node.right, depth);
}
}물론 이 방식도 side-effect 우려가 있다. 특히 멀티스레드 상황이라면 이렇게 클래스 필드를 상태 저장에 쓰는 방식은 thread-unsafe하다.
그러므로 return을 활용한 방식(전역 상태 없이 지역 변수만 있는 방식)이 더 안전하고, 함수형 설계에도 부합하다. (참고로, 재귀가 아주 깊으면 스택 오버플로우가 터질 수 있으므로 그럴 땐 반복문 방식이 더 안전하다.)
🔹 시간복잡도
O(n) (n = 트리의 노드 수)
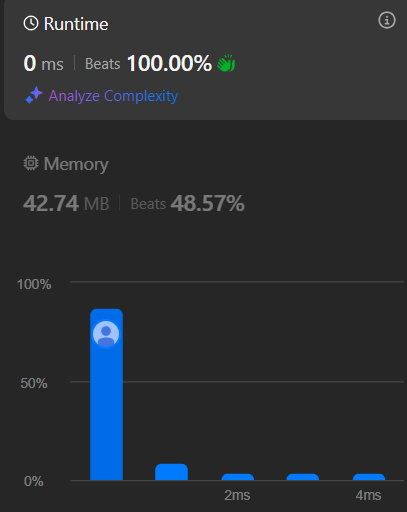
1️⃣-3️⃣ 내 풀이 ver. 3
📌 누적 최대 깊이를 취하는 로직을 유지하되, 참조나 필드 없이 지역 변수로만 작성한 코드전역 변수로 상태 저장하던 기존 코드와 매커니즘이 좀 다르다.
class Solution {
public int maxDepth(TreeNode root) {
return dfs(root, 0, 0);
}
private int dfs(TreeNode node, int depth, int maxi) {
if (node == null) {
return Math.max(maxi, depth);
}
// 왼쪽과 오른쪽에서 각각 최대 깊이 계산
int leftMax = dfs(node.left, depth + 1, Math.max(maxi, depth));
int rightMax = dfs(node.right, depth + 1, Math.max(maxi, depth));
// 두 쪽에서 나온 최댓값 반환
return Math.max(leftMax, rightMax);
}
}
기존 코드에서는 if (node == null) 조건문에서 DFS 전 구간에서 공유되는 전역 변수 maxSoFar에 누적 최댓값이 갱신된다.(모든 경로의 최대 깊이)
하지만 ver.3 에서는 if (node == null) 에서의 maxi값이 DFS의 현재 경로 내에서만 유지되며, 전역 공유가 없다. 즉, if (node == null)에서 반환된 값은 그 경로 한정이므로 부모 호출에서 left와 right를 비교하여 합친 최대 깊이를 계산해야 한다.
2️⃣ 책 풀이 1
반복 구조로 BFS를 활용한 풀이이다.
while문 안에 for 문을 넣어서 트리의 층(레벨)단위로 묶어 반복하게 하였다.
class Solution {
public int maxDepth(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int depth = 0;
while (!queue.isEmpty()) {
depth++;
// 큐 크기 계산, 이 값은 해당 깊이의 모든 노드 수와 일치한다.
int q_size = queue.size();
// 해당 깊이에 위치한 모든 노드 수만큼 반복
for (int i=0; i<q_size ; i++) {
TreeNode cur = queue.poll();
if (cur.left != null) queue.add(cur.left);
if (cur.right != null) queue.add(cur.right);
}
}
// BFS 반복 횟수 == 깊이
return depth;
}
}queue에 부모 노드와 자식 노드가 섞이지만 처음 for문 진입 시 부모 노드의 길이를 queue.size()로 정확히 계산하고 딱 그만큼만 반복하도록 선언해두었으므로 해당 층(레벨)의 노드들만 추출된 후 for문이 종료된다.
⚠️ 만약 for (int i=0 ; i < queue.size() ; i++) {처럼 queue.size()를 조건식에서 직접 사용하면, 반복문 돌 때마다 queue.size()가 다시 계산된다. 그러므로 원래 의도했던 "현재 레벨에 있는 노드 개수만큼만" 반복하는 게 아니라, 다음 레벨에 추가된 노드까지 포함해서 계속 반복하게 된다. 그러므로 레벨 단위 반복을 할 땐 반드시 int q_size = queue.size()처럼 현재 레벨 크기를 먼저 고정해야 한다.
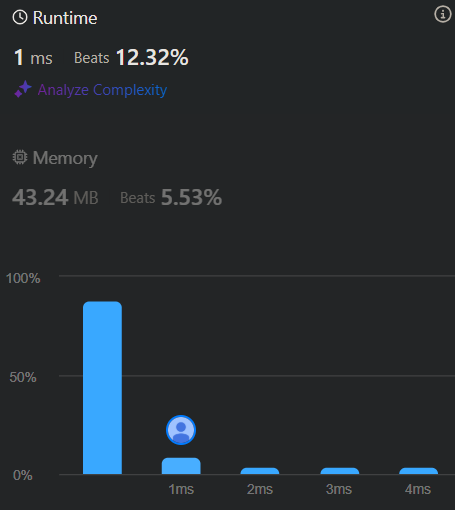
시간복잡도는 O(n)이다. (n은 트리에 존재하는 노드의 개수)
LinkedList 기반 큐에서 poll(), add() 모두 O(1)
3️⃣ 책 풀이 2
재귀 구조로 DFS를 활용한 풀이이다.
가장 우아하고 응용의 여지가 많아서 공부해두면 유용한 코드이다.
public int maxDepth(TreeNode root) {
// 더 이상 존재하지 않는 노드라면 0을 리턴
if (root == null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left,right) + 1;
}
끝까지 탐색하여 노드가 null이 되면 0을 리턴한다.
null인 노드는 그냥 0을 리턴하지만 그 외의 다른 깊이에서는 +1하면서 리턴한다.
이렇게 하면 깊이의 횟수 만큼 +1 처리된 값이 리턴되는 것이다.
게다가 왼쪽/오른쪽 노드 중 큰 값에 1씩 증가시키기 때문에 결국 가장 깊이 내려간 노드의 값이 증가하는 형태가 된다.
직관적으로 이해가 되지 않을 땐, 종이에 트리와 함께 메서드 호출에 따른 스택 프레임, 인자와 return 값 등을 적으면서 이해하는 정공법이 오히려 더 빠른 것 같다.
