오랜만에 보니 더욱 쓸 맛나는 것 같은 Python의 자유로운 기능들!
0️⃣ 참고 : NaN이란?
“숫자형 데이터이긴 하지만 실제 의미 있는 수가 아님.”
수학적 계산에서 자주 등장하는 개념이고, 프로그래밍 언어에서도 "숫자가 아니란 뜻(Not a number)"으로 쓰인다. 데이터 처리 중에 누락값, 오류값, 잘못된 계산 결과로도 생긴다.
📌 NaN의 특징
🔹 숫자형(float)
type(float('nan')) → <class 'float'>
🔹 비교 불가능, 정렬/비교 연산에서 무시됨
nan == nan → False ❗
직접 비교하면 안 되므로,
math.isnan() 또는 numpy.isnan()을 사용해야 한다.
import math
x = float('nan')
print(math.isnan(x)) # True1️⃣ unzip, zip
unzip : zip(*iterable)
fruits = 'apple', 'banana', 'cherry']
# enumerate()를 사용하면 (index, value) 쌍으로 묶인 이터레이터가 생성됨
enumerated = enumerate(fruits)
pairs = list(enumerated) # [(0, 'apple'), (1, 'banana'), (2, 'cherry')]unzip을 이용해 각 요소에 접근하기
: zip(*iterable)을 이용하면, 쌍으로 된 데이터를 분리(unzip) 할 수 있다.
# 인덱스와 값 분리
indices, values = zip(*pairs)
print(indices) # (0, 1, 2)
print(values) # ('apple', 'banana', 'cherry')✅ 응용 예시: enumerate + unzip + list comprehension
인덱스가 짝수인 값만 뽑고 싶다면:
fruits = ['apple', 'banana', 'cherry', 'date']
indices, values = zip(*enumerate(fruits))
even_values = [v for i, v in zip(indices, values) if i % 2 == 0]
print(even_values) # ['apple', 'cherry']✅ enumerate + zip
fruits = ['apple', 'banana', 'cherry']
prices = [1000, 2000, 3000]
for i, (fruit, price) in enumerate(zip(fruits, prices)):
print(f"{i}: {fruit} costs {price} won.")🔹 참고 : zip()으로
반복문에서 동시에 접근할 수도 있고(3개 이상도 가능)
for name, age in zip(names, ages):
print(f"{name} is {age} years old.")zip()을 이용하여 딕셔너리도 생성 가능
keys = ['name', 'age', 'city']
values = ['Alice', 24, 'Seoul']
person = dict(zip(keys, values))
print(person) # {'name': 'Alice', 'age': 24, 'city': 'Seoul'}📌 dictionary comprehension 문법
number = "4177252841"
n2idx = {n:i for i, n in enumerate(number)}
# {'4': 8, '1': 9, '7': 3, '2': 6, '5': 5, '8': 7}
# '4': 8 인 이유? 4가 문자열 안에 여러 번 등장함.
# 딕셔너리는 key 중복이 안 되므로, 마지막에 등장한 위치(index=8)로 덮어씌워짐.
unpacking
for name, age, *_ in prof_list:
여기서 _는 리스트(list) 로 만들어집니다.
이건 “시퀀스 언패킹에서 나머지를 묶을 때” 사용되는 문법 때문이에요.
즉, 여기서 은 언패킹 시 “남은 요소를 전부 리스트로 묶어줘”라는 뜻입니다.
def get_mult_result(*li):
이건 함수 인자에서의 가변인자(packing) 문법이에요.
여기서 *li는 “호출할 때 전달된 모든 인자를 하나의 튜플(tuple) 로 묶겠다”는 뜻입니다.
-
왼쪽(할당문) → 나머지를 리스트로 묶음
-
오른쪽(함수 정의의 인자) → 인자들을 튜플로 묶음
➡️ 즉, *의 위치(할당 vs 함수정의) 가 자료형을 결정합니다.
prof_list = [
("Kim", 52, "010-1111-1222", "soccer", 5),
("Park", 48, "010-3311-6622", "football", 4),
("Oh", 57, "010-3271-6929", "tennis", 1),
("Lee", 42, "010-6274-8809", "soccer", 2)
]
for name, age, *_ in prof_list: # 3개의 원소를 1개의 원소로 패킹(Packing)하기
print("prof_name :", name)
print("prof_age :", age)
print("Others :", _)
def get_mult_result(*li):
result = 1
for i in li:
result *= i
return result
print(get_mult_result(3, 5, 7, 2, 4))proflist 안의 for문에서는 가 리스트(list) 형태로 남은 원소들을 패킹합니다.
get_mult_result(*li)에서 li는 튜플(tuple) 로 전달된 인자들을 묶습니다.
따라서 _와 li 모두 “여러 값을 하나로 묶는다”는 점은 같지만,
언패킹 시(for) → list
가변인자(def) → tuple
이 차이점이 있습니다.
1단계: 함수 정의
def introduce(*info):
print("info :", info)
print("type :", type(info))→ *info는 함수 정의 시 쓰이는 가변 인자 문법이에요.
들어오는 모든 인자를 하나의 튜플(tuple) 로 “패킹(packing)”합니다.
# 함수 호출
introduce("Kim", 52, "010-1111-1222", "soccer", 5)# 출력 결과
info : ('Kim', 52, '010-1111-1222', 'soccer', 5)
type : <class 'tuple'>활용 예시
def multiply_all(*nums):
result = 1
for n in nums:
result *= n
return result
print(multiply_all(3, 5, 7, 2, 4)) # 840*는 함수 정의뿐 아니라 호출할 때도 쓸 수 있습니다.
values = [3, 5, 7, 2, 4]
print(multiply_all(*values)) # 리스트를 언패킹해서 개별 인자로 전달2️⃣ sys.maxsize
sys.maxsize는 현재 파이썬 인터프리터에서 int가 표현할 수 있는 기본 최대 정수 크기이다. (실제론 int가 이보다 커질 수도 있음 — 하지만 보통 “int형 최대값”처럼 쓰임)
3️⃣ max()
◽ max()에 default 인자
max()에 key 인자를 주어서 💫기본값을 지정할 수 있다.
비교를 단순한 값이 아니라 함수의 반환값 기준으로 하게 해준다.
# 빈 리스트에서 max()를 호출하면 에러가 난다.
max([]) # ValueError: max() arg is an empty sequence
# 하지만 default 옵션으로 기본값을 지정할 수 있다.
print(max([], default=0)) # 0◽ max()에 key 인자
max()에 key 인자를 주어서 💫비교 기준💫을 지정할 수 있다.
비교를 단순한 값이 아니라 함수의 반환값 기준으로 하게 해준다.
🔹 문자열 길이로 비교
words = ["cat", "elephant", "dog"]
print(max(words, key=len)) # 'elephant'print(max("a", "abc", "ab", key=len)) # 'abc'🔹 절댓값 기준으로 비교
nums = [-10, -5, 3, 1]
print(max(nums, key=abs)) # -10절댓값이 가장 큰 게 -10이니까 그걸 반환.
▫️ 튜플의 두 번째 요소 기준으로 비교
pairs = [(1, 5), (2, 10), (3, 7)]
print(max(pairs, key=lambda x: x[1])) # (2, 10)▫️ 다중 기준 정렬 (튜플 반환)
key에 튜플을 리턴하면 여러 기준으로 비교 가능.
students = [
("Kim", 90, 22),
("Lee", 90, 21),
("Park", 80, 23)
]
# 점수 기준 → 같으면 나이 기준 (작은 나이 우선)
print(max(students, key=lambda x: (x[1], -x[2]))) # ('Lee', 90, 21)◽ max()와 언패킹
iterable 여러 개 비교
a = [3, 5, 7]
b = [1, 9, 2]
print(max(*a, *b)) # 94️⃣ find()
인덱스로 처리하는 방법 (find() 이용)
s = "banana"
target = "a"
idx = s.find(target) # 첫 번째 'a'의 인덱스 (0)
if idx != -1:
s = s[:idx] + s[idx+1:]
print(s) # 'bnana'str.find(x) → 찾는 문자의 첫 번째 인덱스 반환
못 찾으면 -1 반환
슬라이싱을 이용해 “해당 문자만 제외한 새 문자열”을 만든 거예요.
✅ 이 방식은 replace()보다 명시적이라, “정확히 첫 번째만 지운다”는 의도를 코드에 드러낼 수 있습니다.
re (정규식) 이용 — 첫 번째 등장만 제거
import re
s = "banana"
s = re.sub("a", "", s, count=1)
print(s) # 'bnana're.sub(pattern, replacement, string, count)
count=1 → 첫 번째 매칭만 바꿈
이건 replace()와 거의 동일하지만, 정규식을 쓸 수 있어서 좀 더 복잡한 패턴도 다룰 수 있습니다.
예: re.sub(r"[aeiou]", "", s, 1) → 첫 번째 모음만 제거
5️⃣ Dictionary
get(k, [default])
키로 값 조회 (없으면 기본값)
d.get('x', 0)
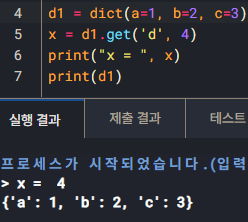
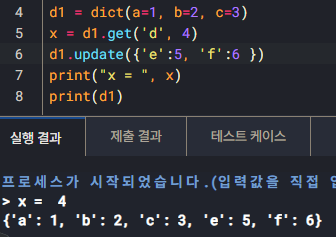
update()
Dictionary Comprehension
squares = {x: x**2 for x in range(5)}
print(squares) # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
# 조건 추가도 가능
even_squares = {x: x**2 for x in range(10) if x % 2 == 0}
print(even_squares) # {0: 0, 2: 4, 4: 16, 6: 36, 8: 64}병합
d1 = {'a': 1, 'b': 2}
d2 = {'b': 3, 'c': 4}
merged = d1 | d2
print(merged) # {'a': 1, 'b': 3, 'c': 4}조건부업데이트 setdefault(k, [default])
키가 있으면 기존 값을 그대로 반환하고,
없으면 d[k] = default로 새로 만들고, 그 값을 반환한다.
두 번째 인자를 생략하면 기본값은 None
if 'x' not in d:
d['x'] = 1
# 같은 표현
d.setdefault('x', 1)딕셔너리는 Python 3.7부터 삽입 순서 유지하지만,
정렬하려면 sorted()를 사용합니다.
scores = {'Kim': 90, 'Lee': 85, 'Park': 92}
print(sorted(scores)) # 키 기준 정렬 ['Kim', 'Lee', 'Park']
print(sorted(scores.items(), key=lambda x: x[1]))
# 값 기준 정렬 [('Lee', 85), ('Kim', 90), ('Park', 92)]defaultdict()
🚫 일반 dict (Key Error 발생)
d = {}
d['a'].append(1) # KeyError ❌✅ defaultdict (자동 생성)
from collections import defaultdict
d = defaultdict(list)
d['a'].append(1)
d['a'].append(2)
print(d) # defaultdict(<class 'list'>, {'a': [1, 2]})✅ setdefault() 버전
pairs = [('A', 1), ('B', 2), ('A', 3)]
group = {}
for k, v in pairs:
group.setdefault(k, []).append(v)
print(group)
# {'A': [1, 3], 'B': [2]}✅ defaultdict 버전 (더 간결)
from collections import defaultdict
group = defaultdict(list)
for k, v in pairs:
group[k].append(v)
print(group)
# defaultdict(<class 'list'>, {'A': [1, 3], 'B': [2]})defaultdict에서도 setdefault()와 마찬가지로 기존 키가 이미 존재하면 덮어쓰지 않는다.
⚠️ 단, 주의점
defaultdict는 키를 조회할 때([]) 자동으로 새 항목을 만든다는 점이 setdefault()와 다르다.
from collections import defaultdict
d = defaultdict(int)
print('a' in d) # False
print(d['a']) # 0 ← 접근하는 순간 'a'가 생김!
print('a' in d) # True접근만 해도 키가 생겨버리기 때문에,
“존재 여부만 확인하려고 d[key]를 호출하면” 의도치 않게 딕셔너리가 변할 수 있다.
이런 경우엔 get()을 써야 안전하다.
커스텀 기본값
기본값을 동적으로 정할 수도 있음.
from collections import defaultdict
d = defaultdict(lambda: 'unknown')
print(d['name']) # 'unknown'
print(d) # defaultdict(<function <lambda> at 0x...>, {'name': 'unknown'})default_factory()는 defaultdict() 안에 들어가는 “기본값을 만들어주는 함수”입니다.
즉, 키가 없을 때 “이 함수로 새 값을 만들어서 딕셔너리에 넣어줘”라는 뜻이에요.
“defaultdict는 없는 키에 접근하면 default_factory()를 실행해서 기본값을 만들어 넣는다.”
예를 들어 defaultdict(list)면 list()가 실행돼 빈 리스트 []가 들어간다.
🧩 예를 들어볼게요
from collections import defaultdict
d = defaultdict(list)여기서 list가 바로 default_factory예요.
의미는 다음과 같습니다 👇
“이 딕셔너리에 없는 키가 들어오면,
자동으로 list() (즉, 빈 리스트 [])를 새로 만들어 넣어줘.”
🔍 예시
d = defaultdict(list)
print(d) # 아직 아무것도 없음
print(d['a']) # 키 'a'가 없는데 접근함 → 자동으로 list() 호출
print(d) # {'a': []} ← 새 키 자동 생성됨'a' 키는 원래 없었음
그런데 d['a']로 접근 → list()가 호출돼 []가 만들어짐
그래서 'a': []가 새로 추가됨
이게 바로 👇
“새 키일 때만 default_factory()로 새 기본값을 만든다”
라는 뜻이에요.
defaultdict(int)가 자동으로 0부터 시작하는 카운터 역할을 할 수 있음
from collections import defaultdict
d1 = defaultdict(int)
for x in ['apple', 'banana', 'apple']:
d1[x] += 1
print(d1)
# 출력 → defaultdict(<class 'int'>, {'apple': 2, 'banana': 1})아래 코드와 같은 역할
count = {}
for x in items:
if x not in count:
count[x] = 0
count[x] += 1단어 등장 횟수 세기
sentence = "the cat and the dog and the cat"
count = defaultdict(int)
for word in sentence.split():
count[word] += 1
print(count)
# {'the': 3, 'cat': 2, 'and': 2, 'dog': 1}숫자 리스트의 등장 빈도 세기
nums = [1, 2, 1, 3, 2, 1]
freq = defaultdict(int)
for n in nums:
freq[n] += 1
print(freq)
# {1: 3, 2: 2, 3: 1}배열/문자열에서 각 원소가 몇 번 등장했는가?
count = defaultdict(int)
for elem in arr:
count[elem] += 1list.index()
⚠️ 주의점
해당 값이 리스트에 없으면 ValueError 가 납니다.
nums.index(100)ValueError: 100 is not in list
➡️ 안전하게 처리하고 싶다면 in과 함께 써야 합니다:
if 100 in nums:
print(nums.index(100))
else:
print("값이 리스트에 없습니다.")- 모든 등장 위치를 찾고 싶다면
index()는 첫 번째 값만 주니까,
모든 인덱스를 알고 싶다면 리스트 컴프리헨션을 사용합니다.
nums = [10, 20, 30, 20, 40]
positions = [i for i, x in enumerate(nums) if x == 20]
print(positions) # [1, 3]
➡️ enumerate()는 (인덱스, 값) 쌍을 만들어주기 때문에, 조건에 맞는 모든 인덱스를 쉽게 찾을 수 있습니다.
문자열 정렬
🧩 1️⃣ 문자열 내부의 문자들을 알파벳순으로 정렬
s = "python"
sorted_s = ''.join(sorted(s))
print(sorted_s) # 'hnopty'sorted(s)는 문자열을 문자 단위로 쪼개서 리스트로 정렬합니다.
→ ['h', 'n', 'o', 'p', 't', 'y']
''.join()으로 다시 문자열로 합치면 알파벳순 문자열이 됩니다.
🧩 2️⃣ 문자열들의 리스트를 알파벳순으로 정렬
words = ["banana", "apple", "cherry"]
sorted_words = sorted(words)
print(sorted_words) # ['apple', 'banana', 'cherry']
➡️ 파이썬의 기본 정렬은 사전 순 (lexicographical order) 이라서
알파벳순 정렬이 기본 동작입니다.
⚙️ 3️⃣ 대소문자 구분 여부
파이썬은 기본적으로 대문자 < 소문자로 취급합니다.
words = ["Apple", "banana", "Cherry", "apple"]
print(sorted(words))
# ['Apple', 'Cherry', 'apple', 'banana']➡️ 대문자/소문자 구분 없이 정렬하고 싶다면:
print(sorted(words, key=str.lower))
# ['Apple', 'apple', 'banana', 'Cherry']만약 “빈 리스트 3개를 만들고 싶다면?”
이렇게 해야 합니다 👇
res = [[] for _ in range(len(idx_set))]
# 또는
res = [[] for _ in range(3)]출력:
[[], [], []]⚠️ 비슷하지만 잘못된 예시도 하나
res = [[]] * 3이건 [[], [], []] 처럼 보이지만 전부 같은 리스트를 참조합니다.
즉, 하나만 바꿔도 다 바뀜:
res[0].append(1)
print(res) # [[1], [1], [1]]원하는 결과: [["ant"], ["ate"], ["cat"]]
이걸 얻으려면 새 리스트를 생성해야 합니다.
방법 ① 리스트 컴프리헨션 (가장 깔끔함)
idx_set = ["ant", "ate", "cat"]
res = [[item] for item in idx_set]
print(res)
# [['ant'], ['ate'], ['cat']]방법 ② 일반 for문
res = []
for item in idx_set:
res.append([item])
print(res)
# [['ant'], ['ate'], ['cat']]🟨 3. filter(function, iterable)
반복 가능한 객체(list, tuple 등)에서
조건에 맞는 요소만 걸러서 반환.
nums = [1, 2, 3, 4, 5, 6]
even = filter(lambda x: x % 2 == 0, nums)
print(list(even)) # [2, 4, 6]map() 예시 — 변환
nums = [1, 2, 3, 4, 5]
result = map(lambda x: x * 2, nums)
print(list(result))
# [2, 4, 6, 8, 10]➡ 모든 숫자를 두 배로 변환함.
filter() 예시 — 선택
nums = [1, 2, 3, 4, 5]
result = filter(lambda x: x % 2 == 0, nums)
print(list(result))
# [2, 4]➡ 짝수만 선택함.
- .reverse()
리스트의 순서를 반대로 뒤집음 (in-place)
반환값은 None (리스트 자체가 바뀜).
문자열에는 .reverse()가 없고, 리스트 전용입니다.
문자열은 [::-1] 슬라이싱으로 뒤집을 수 있습니다.
reduce()
reduce()는 리스트의 모든 값을 하나로 줄이는(누적하는) 함수예요.
즉, “반복적으로 합치기”를 자동으로 해줍니다.
👉 이름 그대로 reduce = 줄인다(축소한다)
🧠 사용법
from functools import reduce
reduce(function, iterable)function: 누적 계산을 수행할 함수
iterable: 리스트나 튜플 같은 반복 가능한 객체
🔹예시 1 — 합 구하기
from functools import reduce
nums = [1, 2, 3, 4, 5]
result = reduce(lambda x, y: x + y, nums)
print(result) # 15작동 과정:
1단계: x=1, y=2 → 3
2단계: x=3, y=3 → 6
3단계: x=6, y=4 → 10
4단계: x=10, y=5 → 15
즉,
(((1 + 2) + 3) + 4) + 5
이 과정을 자동으로 해줍니다.
🔹예시 2 — 곱 구하기
nums = [1, 2, 3, 4]
result = reduce(lambda x, y: x * y, nums)
print(result) # 24즉,
(((1 2) 3) * 4)
🔹예시 3 — 문자열 연결하기
words = ["Python", "is", "fun"]
result = reduce(lambda x, y: x + " " + y, words)
print(result)
# "Python is fun"operator.itemgetter()
튜플, 리스트, 딕셔너리 등의 특정 위치(혹은 키)에 있는 값을 꺼내는 함수를 만들어주는 도구이다.
즉, “이 자료에서 인덱스 n번째 값(혹은 특정 key 값)을 꺼내라”
라는 함수를 자동으로 생성한다.
위처럼 튜플 리스트를 특정 위치 기준으로 정렬할 때 정말 많이 쓴다.
예시
from operator import itemgetter
foods = [(3, 2), (1, 5), (2, 4)]
# 두 번째 값(인덱스 1) 기준으로 오름차순 정렬
foods.sort(key=itemgetter(1))
print(foods)foods.sort(key=lambda x: x[1])와 완전히 같은 표현이지만 itemgetter()가 C로 구현돼있어서 훨씬 빠르다.
여러 인덱스 동시에 가져오기
from operator import itemgetter
data = ('apple', 10, 5.5, 'red')
get_name_and_price = itemgetter(0, 2)
print(get_name_and_price(data)) # ('apple', 5.5)→ (0, 2)를 넘기면, 인덱스 0과 2의 값만 튜플로 반환함.
6️⃣7️⃣8️⃣9️⃣🔟
