KGAT: Knowledge Graph Attention Network for Recommendation
https://arxiv.org/pdf/1905.07854.pdf
이 논문이 제시하는 모델은 효과적인 추천을 위해 high-order relations을 고려한 Knowledge Graph model 이다.
High-order relation 이란 두 아이템들의 attribute들이 link된 것이다.
(attribute들 간의 relation은 기본적으로 여러 관계를 경유하기 때문에 High-order, 아래 그림에서 entity들이 attribute node에 해당함. 다시 말해서, attribute들도 고려하는 추천시스템이라는것.)
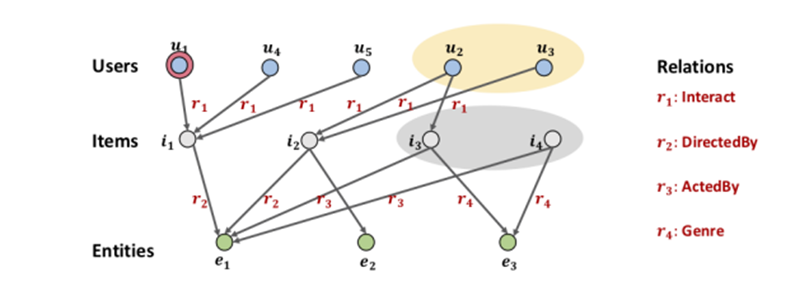
CKG
이 논문에서 다루는 데이터는 collaborative knowledge graph(CKG)이다.
CKG는 위 그림처럼 knowledge graph와 user-item graph의 hybrid structure.
Knowledge graph : entity – relation graph
e.g)
U : user
I : item - 유저가 본 영화
E : entity - item인 영화에 출연한 영화배우 (아이템과 연관성이 있는 것)
Methodology
KGAT 모델을 통해 end to end 방식으로 high order relation을 추출해낸다.
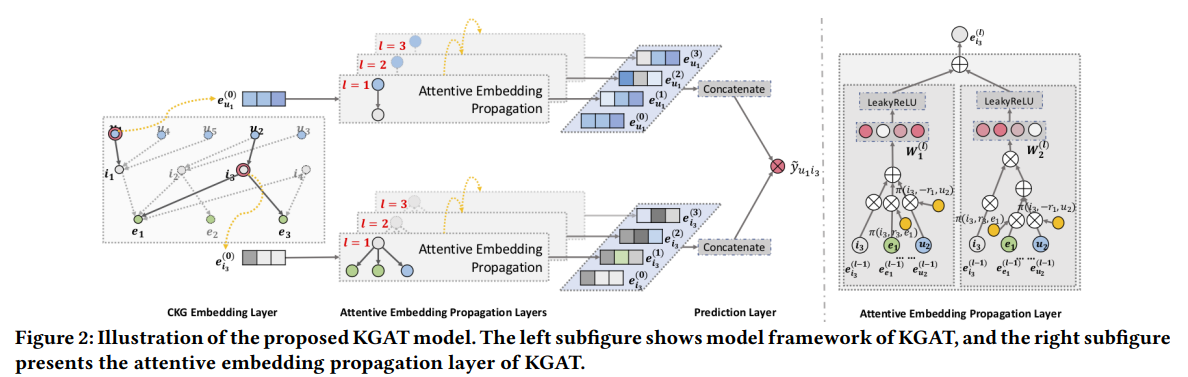
논문에서 제시하는 KGAT 모델
embedding layer -> attentive layer -> prediction layer
이때, embedding layer 에는 "TransR" 이 사용된다.
기본적인 지식 그래프의 벡터 임베딩
TransE -> TransH -> TransR
E : (head,relation,tail)에서 head의 translation을 통한 tail 도달
그렇기 때문에, entity space에서의 one to one 관계만 다룰 수 있음.
H : entity space에서의 one to N , N to one , N to N 관계에 대해서 초평면을 도입함으로써 E와 다르게 다룰 수 있게됨.
R : entity space에 relation이 있는 것에 대해 relation space를 정의함. 해당 공간으로의 Projection Matrix를 정의함.
Task Description

user-item 그래프와 item-entity 그래프 (지식그래프) 가 들어오면,
user 와 item 간의 연결을 예측한다.
Embedding layer
TransR과 동일하다.
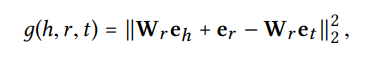
https://linyankai.github.io/publications/aaai2015_transr.pdf
scoring function.
(relation space로 projection하는 learnable W함수, relation에서의 head vector를 translation을 통해 tail vector로 일치 될 수 있음)
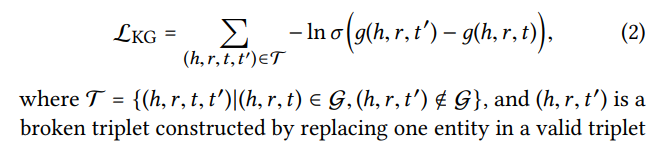
relation이 broken된 node랑 , (h,r,t)를 "선택해서" broken 된 애는 작은 값을 갖고 (h,r,t)는 큰 값을 갖도록 학습함.
https://arxiv.org/pdf/1704.03135.pdf
pairwise ranking loss
pairewise는 (element wise처럼) 쌍끼리
pairwise ranking loss는 본래의 논문에서 softmax function 대신 사용해서 class를 결정하는데 사용되지만, KGAT의 embedding layer인 TransR 논문에서는 similarity 학습을 위해서 사용된다.
Attentive Embedding Propagation Layer
graph convolutional network의 방법론을 사용한다.
https://arxiv.org/abs/1609.02907
Information Propagation
기본적으로 하나의 Entity는 하나가 아닌 여러 triplet과 연결되어 있고 여러 관계를 거쳐서 연결되어 있기 때문에,
연결된 정도를 나타내는 decay factor 를 정의해야하고 그것을 고려해서 aggregation 한다. 구체적인 형태는 다음과 같다.
Entity 는 그것에 연결된 Entity에 decay factor를 곱하고 linear combination 형태로 attention 한다.
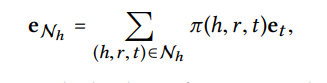
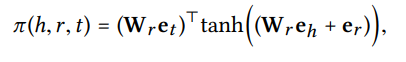
decay factor 를 정의한 뒤 normalize는 다음과 같이 softmax함수를 통해 이뤄진다.
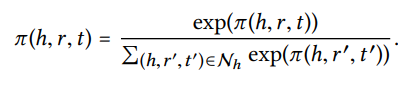
information aggregation
논문에서 예를 든 aggregator는 다음과 같다.

High-order Propagation
High order를 갖는 경우에는 recursive 하게 다룬다.
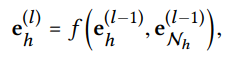
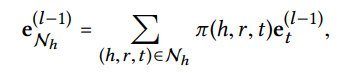
Model Prediction
L번째 Layer 까지 실행한 후에는 다음과 같은 representation을 얻는다.
user node =>
item node =>
그다음 concatenate 한다.
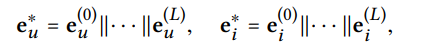
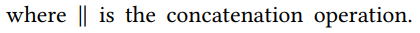
마지막으로, inner product를 통해 "matching score" 라고 표현하는 유사도를 측정하게된다.
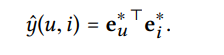
Optimization
TransR에서 제시되는 objective function .
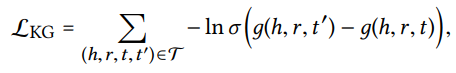
Recommendation model을 optimization 시키기 위한 objective function인 의 경우는 user u와 item j 사이의 관찰된, potisive relation 쌍과 관찰되지 않은 negative relation 쌍을 "선택해" 계산을 진행한다.
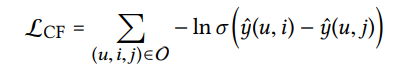

최종적으로, regularization term을 추가한 두 objective function의 합이 최종 objective function이다.
