참고 자료 ) https://www.dataquest.io/blog/introduction-to-vector-databases-using-chromadb/
https://www.reddit.com/r/Rag/comments/1g3h9w2/does_rag_have_a_scaling_problem/?utm_source=chatgpt.com
관련 코드 ) https://github.com/sngmng6506/vectordb-acc-and-speed-exp
Overview.
어플리케이션에서 VectorDB 저장되는 문서의 양을 얼마까지 설정해야할지 기준선을 정하기 위해 속도와 정확도에 대해 테스트 진행함.
요약.
[속도]
1. 실제 서비스에서 속도만 고려했을 때, 문서양에 대한 제한을 안두어도 괜찮음.
2. 빠른 RAG 검색 시스템을 구현을 위해서는 VectorDB 계층에서의 최적화가 아닌 LLM 입력 토큰 및 출력 토큰의 개수를 줄이는 등 LLM 계층에서의 최적화가 필요함.
[정확도]
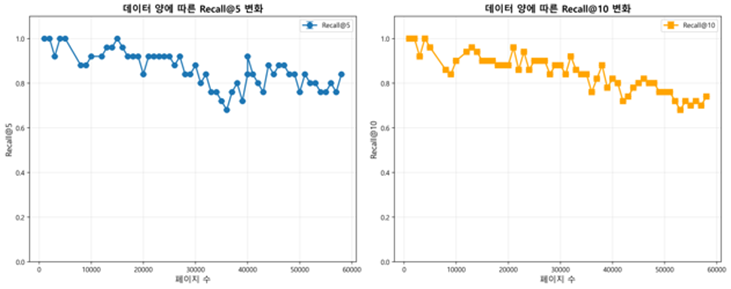
1. 임베딩 문서 양에 따른 검색 성능 하락이 관찰됨.
- 10k page 까지 높은 성능(5% 하락)을 보임, pdf 원본 기준 대략 2GB
- 30k page 까지 준수한 성능(5~15% 하락)을 보임, pdf 원본 기준 대략 4-6GB
- 50k page의 경우 최대 32%까지 성능 하락을 보임
- 벡터에 임베딩되는 문서 양의 경우 청크 전략 및 문서 전처리 방법에 따라 상이할 수 있음.
2.적절한 하이퍼 파라미터값 설정 필요.
- VectorDB의 HNSW의 파라미터 (e.g., efSearch : 탐색 후보 노드 수 )에 따라 속도는 감소할 수 있지만 탐색 성능은 올라감.
결론.
- RAG 파이프라인에서 유효한 성능의 기준선을 잡기란 다양한 변수(문서의 질, 모델 성능, RAG 구성요소들 , ...) 들에 의해 기계적으로 설정하기 어렵지만 반드시 설정을 해야하는 상황에서 보수적인 설정값으로 2GB(문서 용량)를 제안함.
Main.
[환경]
- VectorDB : ChromaDB
- 임베딩 모델 : ko-sberts-sts
- 데이터 : arxiv 논문 4693건
[방법]
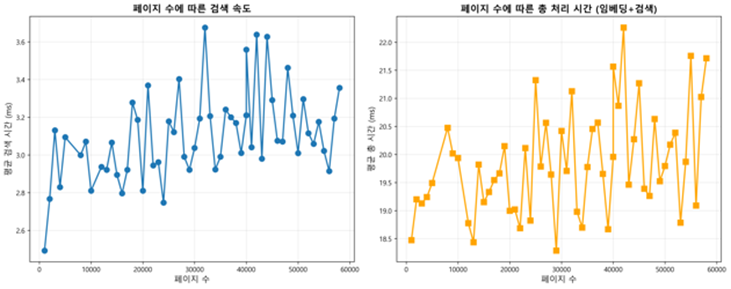
- 최대 58000page 까지 1000page 단위로 VectorDB 컬렉션을 만들어 가면서 성능을 변화를 계산함.
[속도]
- Brute-Force 방법은 Numpy를 통해 쿼리 벡터와 모든 임베딩 벡터의 간의 거리를 계산하고 가장 가까운 벡터 탐색함, 시간 복잡도 = O(N)
- HNSW(Hierarchical Navigable Small World) 방법은 ChromaDB, FAISS 등 VectorDB 검색에서 표준이 되는 알고리즘이며 시간 복잡도 = O(log N)
- Brute-Forec 와 HNSW 간의 검색 속도를 측정함.
[정확도]
- VectorDB에서 쓰이는 HNSW 알고리즘의 경우 근사 탐색이기 때문에 정확한 탐색인 Brute-Force의 경우와 비교해 “맞는 것 중 몇 개를 가져왔는지” Recall@K 를 통해 평가함.

Results.
[속도]
[정확도]

"Engineering Notes" → Here "Research Notes" → https://lifes-ng.tistory.com/ "Code" → github.com/sngmng6506