[Numpy] 데이터 분석의 기초, 다차원 배열 ndarray 완벽 정리
Numpy는 수치적 연산을 위해 최적화된 파이썬 모듈로, 데이터 분석과 머신러닝의 가장 기본이 되는 라이브러리입니다. Pandas, Scikit-learn 등 수많은 라이브러리가 Numpy를 기반으로 구현되어 있습니다.
1. Numpy를 사용하는 이유
- 성능: 파이썬 리스트보다 훨씬 빠릅니다.
- 메모리: 적은 메모리를 효율적으로 사용합니다.
- 기능: 선형대수, 통계 등 풍부한 수치 함수를 제공합니다.
- 표준: 데이터 과학 생태계의 공용어와 같습니다.
차원
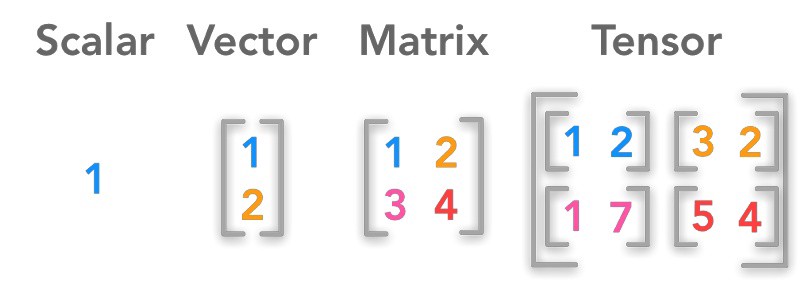
Scalar : 0차원 array (단일값)
Vector : 1차원 array
Matrix : 2차원 array
Tensor : 3차원(이상) array
2. ndarray의 기본 속성
Numpy의 핵심 타입은 ndarray (n-dimensional array)입니다. 모든 원소는 단일 타입으로 정의됩니다. (리스트는 원소타입이 각각 다르다)
import numpy as np #핵심
#생성
arr1 = np.array([1, 2, 3, 4, 5])
# 주요 속성 확인
arr1.shape # (5,) -> 1차원, 크기 5
arr1.ndim # 1 (차원 수) # len(arr1.shape)로 써도 된다.
arr1.size # 5 (전체 원소 개수)
arr1.dtype # dtype('int64') (데이터 타입)
# 2차원 array 생성
arr2=np.array([[2,3,4],[1,2,4]])
arr2.shape #(2,3)
#숫자 2개==2차원,
#차원의 크기는 2*3=6,
#크기가 3짜리 1차원 배열이 2개가 있다는 뜻
# 1차원 배열의 원소는 스칼라값 (0차원)
len(arr1) #5
# 2차원 배열의 원소는 1차원 배열
len(arr2) #2 #1차원 배열의 개수는 2개
데이터 타입 (dtype)
타입이 섞여 있을 경우, 더 큰 범위를 포함하는 타입(예: 정수와 실수가 섞이면 실수형)으로 통일됩니다.
- int: 정수
- float: 실수
- bool: 불리언
- object: 파이썬 객체
자료형의 종료
(자료형 뒤에 붙는 숫자는 몇 비트 크기인지를 의미한다.)
- 부호가 있는 정수 int(8, 16, 32, 64)
- 부호가 없는 정수 uint(8 ,16, 32, 64)
- 실수 float(16, 32, 64, 128)
- 복소수 complex(64, 128, 256)
- 불리언 bool
- 문자열 string_
- 파이썬 오프젝트 object
- 유니코드 unicode_
3. 배열 생성 및 차원 변경
생성 함수
np.arange(start, stop, step): 범위 내 배열 생성 (range와 사용법 유사)np.zeros(shape): 0으로 채워진 배열np.ones(shape): 1로 채워진 배열np.full(shape, fill_value): 특정 값으로 채우기np.eye(N): 주대각선만 1이고 나머지는 0 인 N x N 단위 행렬
np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1,10,2)
# array([1, 3, 5, 7, 9])
np.arange(10,0)
# array([], dtype=int64) 빈 배열
np.arange(10,0,-1)
# array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
np.arange(1,10,dtype=np.int16)
# array([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int16)
# N x N 단위 행렬
np.eye(5,dtype=np.int16)
"""array([[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1]], dtype=int16)"""
shape(차원) 변경하기
차원변환은 데이터분석 과 인공지능에서 매우 빈번하게 발생되는 작업이니만큼 자유자재로 변환할수 있어야 하고, 머리속으로 내가 변환하는 데이터의 구조가 그려지도록 익숙해져야 합니다
EX) 이미지 데이터 벡터화 - 이미지는 기본적으로 2차원 혹은 3차원(RGB)이나 트레이닝을 위해 1차원으로 변경하여 사용됩니다.
| 특징 | ravel() | flatten() |
|---|---|---|
| 반환값 | 원본의 View (가급적 참조) | 원본의 Copy (데이터 복사) |
| 속도/메모리 | 빠름, 메모리 효율적 | 상대적으로 느림, 메모리 추가 점유 |
| 수정 시 | 반환된 값을 수정하면 원본도 바뀜 | 반환된 값을 수정해도 원본은 유지됨 |
| 형태 | np.ravel(a) 또는 a.ravel() | a.flatten() (ndarray의 메서드로만 제공) |
ravel(), flatten() 예시
import numpy as np
a = np.array([[1, 2],
[3, 4]])
# C-style (Row-major): 가로 방향으로 읽으며 펼침 (기본값)
# 결과: [1, 2, 3, 4]
print(a.ravel(order='C'))
# F-style (Column-major): 세로 방향으로 읽으며 펼침
# 결과: [1, 3, 2, 4]
print(a.ravel(order='F'))reshape함수 예시
- 원소의 총 개수(size)가 유지되어야 변환이 가능합니다.
-1을 사용하면 나머지 차원을 자동으로 계산합니다.
np.arange(12).reshape(2,6) #2차원 배열, 원소 6개씩
#array([[ 0, 1, 2, 3, 4, 5],
#[ 6, 7, 8, 9, 10, 11]])
x.reshape(2, -1) # (2, 6) 자동 계산
np.arange(12).reshape(3,2,2)
# 전체 12개를 먼저 3개의 큰 덩어리로 나누고, 그 각 덩어리를 다시 2행 2열짜리 표로 만든 것
#array([[[ 0, 1],
# [ 2, 3]],
# [[ 4, 5],
# [ 6, 7]],
# [[ 8, 9],
# [10, 11]]])
차원 확장 (Expansion)
(1) reshape() 사용
가장 기본적인 방법으로, 전체 요소의 개수만 맞으면 자유롭게 확장 가능합니다.
import numpy as np
x3 = np.arange(6) # (6,)
# (6,) => (6, 1) 로 차원 확장
x3 = x3.reshape(6, 1) #덮어쓰기를 해야지 적용된다!!!!
# (6, 1) => (6, 1, 1) 로 추가 확장
x3 = x3.reshape(6, 1, 1)(2) np.expand_dims() 사용
특정 축(axis)을 지정하여 그 자리에 차원을 '삽입'합니다.
x5 = np.arange(3) # (3,)
# axis=0: 맨 앞에 차원 추가 (3,) -> (1, 3)
y5 = np.expand_dims(x5, axis=0)
x6 = np.arange(4).reshape(2, 2)
# axis=-1: 마지막에 차원 추가 (2, 2) -> (2, 2, 1)
y7 = np.expand_dims(x6, axis=-1)
# 여러 축에 동시 추가 가능: (2, 2) -> (1, 2, 2, 1)
y8 = np.expand_dims(x6, axis=(0, -1))(3) np.newaxis 활용 (Indexing)
슬라이싱 연산 중에 직관적으로 차원을 늘릴 수 있어 실무에서 매우 선호되는 방식입니다.
x8 = np.array([2, 0, 1, 8]) # (4,)
# 1차원 벡터를 행 벡터(Row Vector)로 변환: (4,) -> (1, 4)
row_vec = x8[np.newaxis, :]
# 1차원 벡터를 열 벡터(Column Vector)로 변환: (4,) -> (4, 1)
col_vec = x8[:, np.newaxis]차원 제거 (Reduction)
(1) np.squeeze()
차원 중 사이즈가 1인 것들을 모두 찾아 제거합니다. 데이터의 본질적인 값은 유지하면서 불필요한 껍데기(차원)를 벗겨냅니다.
# (2, 1, 3, 1) 구조의 배열 생성
x4 = np.arange(6).reshape((2, 1, 3, 1))
# 사이즈가 1인 차원을 모두 제거: (2, 1, 3, 1) -> (2, 3)
squeezed_x4 = x4.squeeze()(2) 특정 차원만 제거하기
squeeze()의 axis 파라미터를 사용하면 사이즈가 1인 차원이 여러 개일 때 원하는 것만 골라 제거할 수 있습니다.
# x4.squeeze(axis=1) -> (2, 3, 1)4. 축(axis)의 이해
Numpy 연산에서 axis 파라미터는 매우 중요합니다.
axis (축) 은 각 '차원' 을 의미합니다.
axis= 값을 명시하면 그 함수의 연산 은 해당 axis(축) 에 '따라서' 연산을 수행함
- 1차원 array 라면 각 차원에 대한 axis 값은 0 <- 1개 입니다.
- 2차원 array 라면 각 차원에 대한 axis 값은 0, 1 <- 2개 입니다.
- 3차원 array 라면 각 차원에 대한 axis 값은 0, 1, 2 <- 3개 입니다.
`axis=0`: 행을 따라 연산 (세로로 더하기)
`axis=1`: 열을 따라 연산 (가로로 더하기)
x1 = np.arange(15)
np.sum(x1) #np.int64(105)
np.sum(x1,axis=None) #np.int64(105)
x2 = x1.reshape(3, 5)
#array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
np.sum(x2) # axis=None, 105
np.sum(x2, axis=0) #행끼리 연산 (3,5) => (5,) axis=0인 3을 제거한 것
#array([15, 18, 21, 24, 27]) 행이 사라지고 열의 형태만 남음
np.sum(x2, axis=1) #(3,5) => (3,) 얘는 1인 5를 제거한 것
#array([10, 35, 60]) 열(세로)이 사라지고 행(가로)의 형태만 남음5. 인덱싱과 슬라이싱
인덱싱(index)
- 파이썬 리스트와 동일한 개념으로 사용합니다.
- tuple 를 사용하여 각 차원별 인덱스에 접근 가능합니다.
- 인덱싱 할때마다 차원감소됩니다.
y = np.arange(10).reshape(2, 5) # 2차원
#array([[0, 1, 2, 3, 4],
#[5, 6, 7, 8, 9]])
#출력 결과
y[0]
#array([0, 1, 2, 3, 4]) 1차원으로 차원감소
y[0][2]
# np.int64(2) scarler 값으로 차원 감소
# 콤마(튜플)로 차원별 인덱싱 가능! numpy 에선 후자의 방법을 추천!(중요)
y[0,2] #위와 결과가 같음.
# np.int64(2) scarler 값으로 차원 감소
슬라이싱 (Slicing)
리스트와 달리 다차원에서 콤마(,)를 이용한 동시 슬라이싱이 가능하며,
슬라이싱 결과는 차원을 유지합니다.
y = [[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]]
# 과연 아래와 같이 slicing 가능한가?
# [[1, 2, 3],
# [6, 7, 8]]
y[:2][1:4] #안된다
# ↑ list 는 차원별 slicing 이 불가능하다!
# 출력 결과 : [[5, 6, 7, 8, 9]]
# ↓ Numpy Array 는 차원별 slicing 가능하다!
x = np.arange(15).reshape(3, 5)
x
#이렇게가 아니라
x[:2][1:4] #출력 결과 : array([[5, 6, 7, 8, 9]])
#이렇게!
x[:2, 1:4] #출력 결과 : array([[1, 2, 3],
#[6, 7, 8]])
x[2, 1:4] #출력 결과 : array([11, 12, 13])
배열의 축 바꾸기 (T, transpose, swapaxes)
데이터의 행과 열을 바꾸거나, 고차원 텐서의 차원 순서를 변경하는 방법을 정리합니다.

2차원 배열의 전치 (Transpose)
가장 기본적으로 행과 열을 서로 맞바꾸는 동작입니다.
import numpy as np
a = np.arange(15).reshape(3, 5) # (3, 5)
# 방법 1: np.transpose()
np.transpose(a) # (5, 3)
# 방법 2: .T 속성 (가장 많이 사용됨)
a.T
# 방법 3: swapaxes() - 0번 축과 1번 축을 교환
np.swapaxes(a, 0, 1)2. 고차원 배열에서의 축 변경
3차원 이상의 배열에서는 단순히 뒤집는 것보다 특정 축의 순서를 지정하는 것이 중요합니다.
(1) np.transpose(array, axes)
축의 순서를 리스트나 튜플로 지정합니다. 지정하지 않으면 역순으로 바뀝니다.
# (2, 3, 5) -> 축 번호는 (0, 1, 2)
b = np.random.randn(2, 3, 5)
# 0번과 1번의 위치를 바꾸고 싶을 때
b_trans = b.transpose(1, 0, 2) # 결과 shape: (3, 2, 5)
### (2) np.swapaxes(array, axis1, axis2)
전체 순서를 고민할 필요 없이, **바꾸고 싶은 두 개의 축**만 딱 집어서 교환합니다.
# 0번 축과 2번 축을 교환
b_swapped = np.swapaxes(b, 0, 2) # 결과 shape: (5, 3, 2)요약
.T: 2차원 행렬 뒤집기용 (간편함)transpose(): 전체 축 순서를 재설정할 때 (강력함)swapaxes(): 두 축의 위치만 가볍게 바꿀 때 (명확함)
6. Array 연산의 기초: List와의 차이 및 브로드캐스팅
파이썬 기본 리스트(List)와 넘파이 배열(Array)의 연산 방식 차이를 이해하고, 넘파이만의 강력한 기능인 브로드캐스팅을 정리합니다.
파이썬 리스트(List)의 연산
리스트에서의 연산은 산술 계산이 아니라 '데이터의 변형(반복, 연결)'을 의미합니다.
a = [10, 20, 30, 40]
b = 2
c = [100, 200, 300, 400]
# 리스트 * 숫자 : 리스트 내용 반복
print(a * 2) # [10, 20, 30, 40, 10, 20, 30, 40]
# 리스트 + 숫자 : TypeError 발생
# a + b
# 리스트 + 리스트 : 두 리스트를 하나로 연결
print(a + c) # [10, 20, 30, 40, 100, 200, 300, 400]넘파이 배열(Array)의 연산
배열의 연산은 기본적으로 원소끼리(Element-wise) 수행됩니다. 수학적 행렬/벡터 연산과 동일하게 동작합니다.
import numpy as np
x = np.array([1, 2, 3])
y = np.array([10, 20, 30])
# 원소별 더하기/빼기
print(x + y) # [11, 22, 33]
print(x - y) # [-9, -18, -27]
브로드캐스팅 (Broadcasting)
- (기본적으로는) Shape이 같은 두 ndarray에 대한 연산은 각 원소별로 진행합니다.
- 다른 Shape을 갖는 array 간 연산 의 경우 브로드 캐스팅(Shape을 맞춤) 후 진행합니다.
(1) Array와 스칼라(Scalar) 연산
배열의 모든 원소에 동일한 값을 한 번에 적용합니다.
# 모든 원소에 10을 더함
print(x + 10) # [11, 12, 13](2) 단일 값을 가진 객체와의 연산
대괄호([])의 개수에 따라 연산 후 결과물의 차원(Shape)이 결정됩니다.
# x + [10] : 1차원 벡터 간의 연산으로 간주
# [1, 2, 3] + [10, 10, 10]
print(x + [10]) # [11, 12, 13] (1차원)
# x + [[10]] : 2차원 행렬과의 연산으로 간주 (브로드캐스팅)
# x는 (3,)에서 (1, 3)으로 확장되고, [[10]]은 (1, 3)으로 확장됨
# 결과는 [[11, 12, 13]] (2차원)
print(x + [[10]])
a = np.arange(12).reshape(4, 3)
b = np.arange(100, 103) # (3,)
a + b # b가 모든 행에 더해짐
#출력 결과
array([[100, 102, 104],
[103, 105, 107],
[106, 108, 110],
[109, 111, 113]])
요약 및 결론
- List:
+는 연결,*는 반복을 의미하며 숫자와의 직접 더하기는 불가능합니다. - Array: 모든 산술 연산이 원소 단위로 이루어집니다.
- Broadcasting:
[[10]]처럼 고차원 단일 값과 연산하면, 결과 배열도 해당 고차원 형태를 따라갑니다.
7. 불리언 인덱싱 (Boolean Indexing) ★중요
조건에 맞는 데이터만 추출하는 강력한 기능입니다.
array 인덱싱 시, bool 리스트(aka. mask)를 전달하여 True인 경우만 필터링 합니다.
for 사용하지 않고도 array 에서 '조건'에 맞는 데이터만 추출 하는 기능
# 브로드캐스팅을 활용하여 array로 부터 bool list 얻기
# - 예) 짝수인 경우만 찾아보기
np.random.seed(41)
x = np.random.randint(1, 100, size=10)
even_mask = x % 2 ==0
# 위와 같이 bool 값으로 이루어진 array 를 Mask 라고도 한다
print(even_mask) # True, False들로 구성.
# x[[True,True,True,True,False,False,False,False,False,True]]
x[even_mask] #True 값들만 출력
x = np.random.randint(1, 100, 10)
# 30보다 큰 짝수만 추출
mask = (x > 30) & (x % 2 == 0) #이때 and는 사용(x), &만 사용 가능
x[mask]
8. 실습 예제: 서울시 5월 기온 분석
temp = np.array([23.9, 24.4, 24.1, 25.4, 27.6, 29.7, 26.7, 25.1, 25.0, 22.7, 21.9, 23.6, 24.9, 25.9, 23.8, 24.7, 25.6, 26.9, 28.6, 28.0, 25.1, 26.7, 28.1, 26.5, 26.3, 25.9, 28.4, 26.1, 27.5, 28.1, 25.8])
# Q1. 평균기온이 25도를 넘는 날의 수는?
over_25 = temp[temp > 25]
print(len(over_25))
# Q2. 평균기온이 25도를 넘는 날의 평균기온은?
print(f"{over_25.mean():.1f}도")9. np.random 서브 모듈
- rand: 0부터 1사이의 균일 분포 [0, 1) uniform distribution
- randn: 가우시안 표준 정규 분포 (평균0, 표준편차1 인 종모양 분포) normal distribution
- randint: 균일 분포의 정수 난수
- seed: 램덤 시드값. 고정 난수값 생성
np.random.rand(10) #0부터 1까지 랜덤 숫자 생성
np.random.rand(2,3) #값 3개 가진 이중 배열
np.random.randn(5) #정규분포를 가진 5개 랜덤 숫자 생성
np.random.randint(5) # 0 ~ 4 사이의 정수 난수 [0, 5) 1개 생성
np.random.randint(1,10) #[1,10) # 1 ~ 9 사이의 정수 난수 1개 생성
np.random.randint(1,100,(3,5,2)) #3중 배열로 2중 배열 3개, 각 2중 배열에 1차원 배열 5개씩 생성
# seed() : 난수를 예측가능하도록 만든다. 실행할때마다 동일한 난수가 발생되도록 함.
np.random.seed(0) #이걸 사용하는 다른 컴퓨터도 동일한 결과를 내놓게 함.
np.random.rand(4)
# 비결정적 연산 (Non-Deterministic Operations)
# 같은 코드, 같은 입력을 줬는데도 결과가 매번 조금씩 달라지는 연산
# 결정적 연산 (Deterministic Operations)
# 같은 코드, 같은 입력, 같은 시드를 주면 결과가 동일한 연산
10. 통계 함수와 NaN(Not a Number)
배열에서 최댓값과 그 위치를 찾는 방법, 그리고 데이터 분석의 필수 관문인 결측치(NaN)의 특징을 정리합니다.
최댓값 찾기: max()와 argmax()
넘파이에서는 단순히 최댓값을 찾는 것뿐만 아니라, 그 값이 어디에 위치해 있는지도 쉽게 알 수 있습니다.
(1) 전체 대상 연산
별도의 축 지정이 없으면 배열을 1차원으로 펼쳤을 때를 기준으로 계산합니다.
import numpy as np
y = np.array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
# 전체 최댓값
np.max(y) # 14
# 전체 최댓값의 인덱스 (펼쳤을 때의 번호)
np.argmax(y) # 14(2) 축(axis)별 연산
특정 방향(행 또는 열)을 기준으로 최댓값을 찾습니다.
# axis=0 (열 방향): 위에서 아래로 훑으며 최댓값 찾기
# 결과 모양: (3, 5) -> (5,)
np.max(y, axis=0) # [10, 11, 12, 13, 14]
# 열 방향 최댓값의 인덱스
np.argmax(y, axis=0) # [2, 2, 2, 2, 2] (모두 마지막 행에 있음)결측치 처리: NaN (Not a Number)
NaN은 정의되지 않거나 표현할 수 없는 수치 결과를 의미하며, 실무 데이터(누락값, DBMS의 null 등)에서 매우 자주 마주하게 됩니다.
(1) NaN의 특징
NaN은 수치형 데이터 타입(float)이지만, 어떤 연산을 해도 결과는 NaN이 된다는 치명적인 특징이 있습니다.
np.nan # nan
# NaN과의 연산 결과는 무조건 NaN
print(np.nan + 10) # nan
arr = np.array([10, 20, np.nan])
print(np.sum(arr)) # nan (하나만 섞여 있어도 결과가 파괴됨)(2) NaN 판별하기: isnan()
NaN은 일반적인 비교 연산자(==)로 확인할 수 없으므로, 반드시 전용 함수를 사용해야 합니다.
# 100은 숫자인가? (False)
np.isnan(100) # False
# np.nan은 NaN인가? (True)
np.isnan(np.nan) # True
# math 라이브러리에서도 동일하게 제공
import math
math.isnan(np.nan) # True요약 및 주의사항
- 데이터 분석의 필수: 원본 데이터에
NaN이 포함되어 있다면 통계값(평균, 합계 등)이 왜곡될 수 있으므로, 연산 전에 반드시 제거하거나 다른 값(0이나 평균값 등)으로 치환해야 합니다. - 차원 축소:
max(axis=0)을 하면 해당 축이 사라지며 차원이 축소됩니다. (3x5 배열이 5개짜리 1차원 배열로 변함)
팁: NaN을 무시하고 계산하고 싶다면?
넘파이에는 NaN을 제외하고 계산해주는 nan-safe 함수들이 별도로 존재합니다.
np.nansum(arr): NaN을 0으로 간주하고 합계 계산np.nanmax(arr): NaN을 제외한 최댓값 계산
