[Pandas] 데이터프레임 조작 및 전처리 완벽 정리
1. Row/Column 추가 및 삭제
컬럼(Column) 추가
- [ ] 사용:
df['새컬럼명'] = 데이터형태로 추가 (가장 우측에 추가)
df['Age_Double']=df['Age']*2| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Age_Double |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 44.0 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th...) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 76.0 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 52.0 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 70.0 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 70.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S | 54.0 |
| 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S | 38.0 |
| 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | NaN |
| 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C | 52.0 |
| 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q | 64.0 |
- insert() 사용:
df.insert(위치인덱스, '컬럼명', 데이터)를 사용하여 원하는 위치에 삽입
df.insert(3, 'Fare10', df['Fare'] / 10 )
df.head()| PassengerId | Survived | Pclass | Fare10 | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Age_Double |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | 0.7250 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 44.0 |
| 2 | 1 | 1 | 7.1283 | Cumings, Mrs. John Bradley (Florence Briggs Th...) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 76.0 |
| 3 | 1 | 3 | 0.7925 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 52.0 |
| 4 | 1 | 1 | 5.3100 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 70.0 |
| 5 | 0 | 3 | 0.8050 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 70.0 |
컬럼(Column) 삭제
- drop() 함수:
df.drop('컬럼명', axis=1)(axis=1은 열 방향)
# DataFrame 은 2차원 데이터, axis= 값은 0, 1 두가지가 존재 한다
# axis=0 : row level (default)
# axis=1 : column level
# 열 제거, 원본 변화 없다.
df.drop('Age_Double', axis=1)| PassengerId | Survived | Pclass | Fare10 | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | 0.72500 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | 7.12833 | Cumings, Mrs. John Bradley (Florence Briggs Th...) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | 0.79250 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | 5.31000 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | 0.80500 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | 1.30000 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 888 | 1 | 1 | 3.00000 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 0 | 3 | 2.34500 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 890 | 1 | 1 | 3.00000 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 113803 | 30.0000 | C148 | C |
| 891 | 0 | 3 | 0.77500 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
- 원본 반영:
inplace=True옵션을 주어야 원본 데이터프레임이 변경됨
행(Row) 추가 및 삭제
- 추가:
df.loc['새인덱스'] = 데이터 - 삭제:
df.drop(['인덱스명'], axis=0)(axis=0은 행 방향, 기본값)
df2 = pd.DataFrame([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
], columns=['a','b','c','d'], index = ['김길동', '최진수', '허수민'])
df2| a | b | c | d | |
|---|---|---|---|---|
| 김길동 | 1 | 2 | 3 | 4 |
| 최진수 | 5 | 6 | 7 | 8 |
| 허수민 | 9 | 10 | 11 | 12 |
# 새로운 행(row) 추가
df2.loc['김갑수'] = pd.Series([100, 200, 300, 400], index=['a', 'b', 'c', 'd'])
df2| 인덱스 (Index) | a | b | c | d |
|---|---|---|---|---|
| 김길동 | 1 | 2 | 3 | 4 |
| 최진수 | 5 | 6 | 7 | 8 |
| 허수민 | 9 | 10 | 11 | 12 |
| 김갑수 | 100 | 200 | 300 | 400 |
df2.loc['김철수'] = [101, 202, 303, 404]| 인덱스 (Index) | a | b | c | d |
|---|---|---|---|---|
| 김길동 | 1 | 2 | 3 | 4 |
| 최진수 | 5 | 6 | 7 | 8 |
| 허수민 | 9 | 10 | 11 | 12 |
| 김갑수 | 100 | 200 | 300 | 400 |
| 김철수 | 101 | 202 | 303 | 404 |
# 행 삭제
# drop() 사용, axis=0 (디폴트)
df2.drop(['최진수', '허수민'])| 인덱스 (Index) | a | b | c | d |
|---|---|---|---|---|
| 김길동 | 1 | 2 | 3 | 4 |
| 김갑수 | 100 | 200 | 300 | 400 |
| 김철수 | 101 | 202 | 303 | 404 |
2. 상관관계 (Correlation)
두 변수 간의 선형적 흐름이 얼마나 비슷한지를 나타내는 척도입니다.
- 범위: -1 ~ +1 사이의 값
- +1에 가까울수록: 양의 상관관계 (같이 증가)
- -1에 가까울수록: 음의 상관관계 (한쪽이 증가하면 다른 쪽은 감소)
- 0에 가까울수록: 상관관계가 거의 없음
- 절대값이 클수록: 상관관계가 크다.
- 함수:
df.corr(numeric_only=True) - 주의: 상관관계가 높다고 해서 반드시 '인과관계'가 성립하는 것은 아님
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
상관관계가 있는 자료들
# Fare - Pclass
# Survived - Pclass
# Survived - Fare
# Age - Pclass
# parch-SibSp
# SibSp-Age
# 상관관계 시각화
plt.matshow(df.corr(numeric_only=True))
plt.colorbar()
plt.show()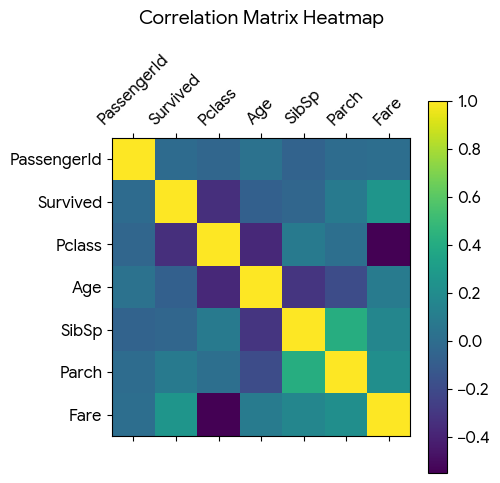
3. NaN (결측치) 처리
데이터에 값이 없는 상태(Not a Number)를 의미하며, 분석 전 반드시 확인해야 합니다.
- 확인:
df.isna()(결측치면 True),df.info()
df.info()
# ↓ Age, Cabin, Embarked 는 결측치가 있슴을 알수 있다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df.isna()
# ↓ 결측치는 True 로 표시된다.| PassengerId | Survived | Pclass | Name | Sex | Age | ... | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | ... | True | False |
| 1 | False | False | False | False | False | ... | False | False |
| 2 | False | False | False | False | False | ... | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 888 | False | False | False | False | True | ... | True | False |
# 특정 컬럼에 대해서 확인
df['Age'].isna()| Index | Age |
|---|---|
| 0 | False |
| 1 | False |
| ... | ... |
| 888 | True |
| 889 | False |
# 결측된 데이터만 확인 <- boolean selection 활용
df[df['Age'].isna()]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 17 | 18 | 1 | 2 | Williams, Mr. Charles Eugene | male | NaN | 0 | 0 | 244373 | 13.0000 | NaN | S |
| 19 | 20 | 1 | 3 | Masselmani, Mrs. Fatima | female | NaN | 0 | 0 | 2649 | 7.2250 | NaN | C |
| 26 | 27 | 0 | 3 | Emir, Mr. Farred Chehab | male | NaN | 0 | 0 | 2631 | 7.2250 | NaN | C |
| 28 | 29 | 1 | 3 | O'Dwyer, Miss. Ellen "Nellie" | female | NaN | 0 | 0 | 330959 | 7.8792 | NaN | Q |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 859 | 860 | 0 | 3 | Razi, Mr. Raihed | male | NaN | 0 | 0 | 2629 | 7.2292 | NaN | C |
| 863 | 864 | 0 | 3 | Sage, Miss. Dorothy Edith "Dolly" | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S |
| 868 | 869 | 0 | 3 | van Melkebeke, Mr. Philemon | male | NaN | 0 | 0 | 345777 | 9.5000 | NaN | S |
| 878 | 879 | 0 | 3 | Laleff, Mr. Kristo | male | NaN | 0 | 0 | 349217 | 7.8958 | NaN | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
- 삭제:
df.dropna()subset=['컬럼명']: 특정 컬럼에 결측치가 있는 경우만 삭제axis=1: 결측치가 포함된 '열' 자체를 삭제
df # 891 rows × 12 columns
df.dropna() # 183 rows × 12 columns| PassengerId | Survived | Pclass | Name | Sex | Age | ... | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley... | female | 38.0 | ... | 71.2833 | C85 | C |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath... | female | 35.0 | ... | 53.1000 | C123 | S |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | ... | 51.8625 | E46 | S |
| 10 | 11 | 1 | 3 | Sandstrom, Miss. Marguerite Rut | female | 4.0 | ... | 16.7000 | G6 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | ... | 26.5500 | C103 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | ... | 30.0000 | C148 | C |
# ↑ 183개의 row 가 나온다 (891개에서 확 줄었다)
# index 나 PassengerId 를 보면 중간중간에 빠진거 확인
# dropna() 기본적으로 row 기준(axis=0)으로 동작한다
# 각 row 에서, 하나라도 NaN 값이 있으면 해당 row 를 지워버린다
# 행을 삭제하되, 특정 컬럼에 대해서만 dropna 하기
df.dropna(subset=['Age']) # 714 rows × 12 columns
# ↓Age 컬럼이 NaN 인 경우만 row 가 drop 됨 (axis=0)| 인덱스 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath... | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
df.dropna(subset=['Age', 'Cabin']) # 185 rows × 12 columns | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath... | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 10 | 11 | 1 | 3 | Sandstrom, Miss. Marguerite Rut | female | 4.0 | 1 | 1 | PP 9549 | 16.7000 | G6 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard... | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 872 | 873 | 0 | 1 | Carlsson, Mr. Frans Olof | male | 33.0 | 0 | 0 | 695 | 5.0000 | B51 B53 B55 | S |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr... | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
# NaN 이 있는 '컬럼' 삭제하기
df.dropna(axis=1)
# ↓ Age, Cabin, Embarked 컬럼 삭제!| PassengerId | Survived | Pclass | Name | Sex | SibSp | Parch | Ticket | Fare | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 1 | 0 | A/5 21171 | 7.2500 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley... | female | 1 | 0 | PC 17599 | 71.2833 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 0 | 0 | STON/O2. 3101282 | 7.9250 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath... | female | 1 | 0 | 113803 | 53.1000 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 0 | 0 | 373450 | 8.0500 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 0 | 0 | 211536 | 13.0000 |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 0 | 0 | 112053 | 30.0000 |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen... | female | 1 | 2 | W./C. 6607 | 23.4500 |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 0 | 0 | 111369 | 30.0000 |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 0 | 0 | 370376 | 7.7500 |
- 대체:
df.fillna(값)- 주로 평균값(
mean())이나 중앙값으로 채워 데이터의 손실을 방지함
- 주로 평균값(
# Age 평균값
df['Age'].mean() # NaN 은 배제된 연산결과닷! 주의
#29.69911764705882 (인원수 삭제가 일어남-714명)
# 위 mean() 값은 891(전체)명에 대한 평균값이 아니라 714(Nan값 제외) 명에 대한 평균값이다
# df['Age'].sum() / df['Age'].count() 둘이 같음
# NaN 을 평균값으로 대체(원본에 영향 없음)
df['Age'].fillna(df['Age'].mean())4. 데이터 타입의 이해 (수치형 vs 범주형)
| 구분 | 수치형 (Numerical) | 범주형 (Categorical) |
|---|---|---|
| 특징 | 연속적인 숫자 | 불연속적인 값 (분류 목적) |
| 예시 | 나이, 운임(Fare) | 성별, 등급(Pclass), 우편번호 |
| 연산 | 산술 연산 및 대소 비교 가능 | 연산 및 대소 비교가 무의미함 |
데이터 변환: apply()
특정 함수를 컬럼 전체에 적용하여 데이터를 변환할 때 사용합니다.
(예: 나이 숫자를 10대, 20대 등 범주형으로 변환)
# 23 -> 20
# 43 -> 40
def age_categorize(age):
if np.isnan(age):
return -1 # Age 값이 없으면 -1 로 처리
return int(age / 10) * 10
age_categorize(47) #40
# 특정 컬럼에 apply(함수) 한다
age_span = df['Age'].apply(age_categorize)
age_span| 인덱스 | 변환 결과 (Age_span) |
|---|---|
| 0 | 20 |
| 1 | 30 |
| 2 | 20 |
| 3 | 30 |
| 4 | 30 |
| ... | ... |
| 886 | 20 |
| 887 | 10 |
| 888 | -1 |
| 889 | 20 |
| 890 | 30 |
5. 원-핫 인코딩 (One-hot encoding)
범주형 데이터를 머신러닝 모델이 인식할 수 있도록 숫자(0과 1)로 변환하는 기법입니다.
- 범주의 개수만큼 컬럼을 생성하고, 해당 범주에만 1을 부여합니다.
- 함수:
pd.get_dummies(df, columns=['컬럼명'], dtype=int)
# 범주형 데이터는 연산이 불가하다 (혹은 의미 없다)
# 그래서 '처리' 가 가능하도록 데이터를 바꿔주어야 할 필요가 있다.
# 범주형 테이터 컬럼한개를 '범주의 개수' 만큼 늘려서
# 범주에 해당하는 값에만 '1' 을 주고
# 나머지에는 '0' 을 주어 처리하는 방법
# --> 이를 One-hot encoding 이라 합니다 <-- 결국 '1' 은 한개만 등장한다
# 가령
# Color 란 컬럼에 "Red", "Green", "Blue" 라는 '세가지' 종류의 범주값만 있다면
# '세 개'의 '0, 1 로 구성된 값'으로 변환시키는 겁니다 ('1' 은 한개만 등장)
# Red -> [1, 0, 0]
# Green -> [0, 1, 0]
# Blue -> [0, 0, 1]
# columns= 파라미터로
# one-hot encoding 컬럼으로 만들어질 컬럼들을 지정해줄수 있다.
pd.get_dummies(df, columns=['Pclass', 'Sex', 'Embarked'], dtype=int)
# dtype=int 를 주면, 0 과 1 로 인코딩된다.| Index | PassenId | Survived | Name | Age | SibSp | Parch | Ticket | Fare | Cabin | Age_span | Pclass_1 | Pclass_2 | Pclass_3 | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | 20 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 2 | 1 | Cumings, Mrs. John Bradley... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | 30 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 2 | 3 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | 20 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 3 | 4 | 1 | Futrelle, Mrs. Jacques Heath... | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 30 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 4 | 5 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | 30 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | Montvila, Rev. Juozas | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | 20 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 887 | 888 | 1 | Graham, Miss. Margaret Edith | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | 10 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 888 | 889 | 0 | Johnston, Miss. Catherine Helen... | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | -1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 889 | 890 | 1 | Behr, Mr. Karl Howell | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | 20 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 890 | 891 | 0 | Dooley, Mr. Patrick | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | 30 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
# drop_first=True
pd.get_dummies(df, columns=['Pclass', 'Sex', 'Embarked'], dtype=int, drop_first=True)
#서로 의존적인 컬럼 중 첫 번째 것을 삭제하여 데이터의 중복성을 제거하는 옵션"**입니다.
#Sex_female이 0이면 당연히 Sex_male은 1이 됩니다.
#즉, 한 쪽만 알아도 나머지 값을 100% 알 수 있는 **정보의 중복(다중공선성)**이 발생합니다.6. 그룹화 (Groupby)
데이터를 특정 조건으로 묶어 통계량을 계산할 때 사용합니다.
(분할 Split -> 적용 Apply -> 병합 Combine 과정)
- 생성:
grouped = df.groupby('컬럼명') - 확인:
grouped.groups,grouped.size() - 연산:
grouped.mean(),grouped.sum(),grouped.count()등
사용 예시들 모음
grouped_pclass = df.groupby(by='Pclass')
# groupby 객체의 속성
# - groups -> dict 형태
# - key -> 컬럼의 각 값
# - value -> 인덱스 값들의 list
# Pclass 의 값은 1, 2, 3 세 개 밖에 없었으니 그룹 개수는 3개다
grouped_pclass.groups
# groups 의 key 값은 'Pclass' 의 값들,
# value 는 index 들의 list
/*
{1: [1, 3, 6, 11, 23, 27, 30, 31, 34, 35, 52, 54, 55, 61, 62, 64, 83, 88, 92, 96, 97, 102, 110, 118, 124, 136, 137, 139, 151, 155, 166, 168, 170, 174, 177, 185, 187, 194, 195, 209, 215, 218, 224, 230, 245, 248, 252, 256, 257, 258, 262, 263, 268, 269, 270, 273, 275, 284, 290, 291, 295, 297, 298, 299, 305, 306, 307, 309, 310, 311, 318, 319, 325, 329, 331, 332, 334, 336, 337, 339, 341, 351, 356, 366, 369, 370, 373, 375, 377, 380, 383, 390, 393, 412, 430, 434, 435, 438, 445, 447, ...],
2: [9, 15, 17, 20, 21, 33, 41, 43, 53, 56, 58, 66, 70, 72, 78, 84, 98, 99, 117, 120, 122, 123, 133, 134, 135, 144, 145, 148, 149, 150, 161, 178, 181, 183, 190, 191, 193, 199, 211, 213, 217, 219, 221, 226, 228, 232, 234, 236, 237, 238, 239, 242, 247, 249, 259, 265, 272, 277, 288, 292, 303, 308, 312, 314, 316, 317, 322, 323, 327, 340, 342, 343, 344, 345, 346, 357, 361, 385, 387, 389, 397, 398, 399, 405, 407, 413, 416, 417, 418, 426, 427, 432, 437, 439, 440, 443, 446, 450, 458, 463, ...],
3: [0, 2, 4, 5, 7, 8, 10, 12, 13, 14, 16, 18, 19, 22, 24, 25, 26, 28, 29, 32, 36, 37, 38, 39, 40, 42, 44, 45, 46, 47, 48, 49, 50, 51, 57, 59, 60, 63, 65, 67, 68, 69, 71, 73, 74, 75, 76, 77, 79, 80, 81, 82, 85, 86, 87, 89, 90, 91, 93, 94, 95, 100, 101, 103, 104, 105, 106, 107, 108, 109, 111, 112, 113, 114, 115, 116, 119, 121, 125, 126, 127, 128, 129, 130, 131, 132, 138, 140, 141, 142, 143, 146, 147, 152, 153, 154, 156, 157, 158, 159, ...]}*/
# size()
# 각 group 별로 담겨 있는 데이터 개수 확인
grouped_pclass.size()
# Series <- df['Pclass'].value_counts() 와 결과 같다| 객실 등급 (Pclass) | 승객 수 (명) |
|---|---|
| 1등급 (1st Class) | 216 |
| 2등급 (2nd Class) | 184 |
| 3등급 (3rd Class) | 491 |
get_group()
그룹별 DataFrame 리턴
# Pclass 가 1 인 그룹의 DataFrame
grouped_pclass.get_group(1)| 인덱스 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath... | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| 23 | 24 | 1 | 1 | Sloper, Mr. William Thompson | male | 28.0 | 0 | 0 | 113788 | 35.5000 | A6 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard... | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 872 | 873 | 0 | 1 | Carlsson, Mr. Frans Olof | male | 33.0 | 0 | 0 | 695 | 5.0000 | B51 B53 B55 | S |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr... | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
7. groupby 객체의 기초 연산 메소드
- 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산)
- count - 데이터 개수
- sum - 데이터의 합
- mean, std, var - 평균, 표준편차, 분산
- min, max - 최소, 최대값
# groupby() 로 쪼갬 <-- split
# group 별로 count()연산 <-- apply
# DataFrame 으로 합하여 리턴 <-- combine (원본과는 다른 새로운 DataFrame)
grouped_pclass.count()| Pclass | Survived | Name | Sex | Age | SibSp | Parch | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 216 | 216 | 216 | 186 | 216 | 216 | 216 | 176 | 214 |
| 2 | 184 | 184 | 184 | 173 | 184 | 184 | 184 | 16 | 184 |
| 3 | 491 | 491 | 491 | 355 | 491 | 491 | 491 | 12 | 491 |
# grouped_pclass.mean() # 에러 . 문자열 타입도 연산하려 해서리..
grouped_pclass.mean(numeric_only=True) # OK
# groupby 객체에 컬럼 선택 가능!
grouped_pclass[['PassengerId', 'Survived', 'Age']].mean()| Pclass | PassengerId (Mean) | Survived (Mean) | Age (Mean) |
|---|---|---|---|
| 1 (1등석) | 461.597222 | 0.629630 | 38.233441 |
| 2 (2등석) | 445.956522 | 0.472826 | 29.877630 |
| 3 (3등석) | 439.154786 | 0.242363 | 25.140620 |
# 객식등급별 승객 나이의 평균
grouped_pclass[['Age']].mean()
# 동일 결과
grouped_pclass.mean(numeric_only=True)[['Age']]복수 columns로 grouping
- groupby에 column 리스트를 전달
- 통계함수를 적용한 결과는 multiindex를 갖는 dataframe
grouped_multi = df.groupby(['Pclass', 'Sex'])
grouped_multi.size()| 객실 등급 (Pclass) | 성별 (Sex) | 승객 수 (명) |
|---|---|---|
| 1등급 (1st Class) | 여성 (female) | 94 |
| 남성 (male) | 122 | |
| 2등급 (2nd Class) | 여성 (female) | 76 |
| 남성 (male) | 108 | |
| 3등급 (3rd Class) | 여성 (female) | 144 |
| 남성 (male) | 347 |
grouped_multi[['Survived', 'Age']].mean()| Pclass | Sex | Survived (Mean) | Age (Mean) |
|---|---|---|---|
| 1 (1등석) | female | 0.968085 | 34.611765 |
| male | 0.368852 | 41.281386 | |
| 2 (2등석) | female | 0.921053 | 28.722973 |
| male | 0.157407 | 30.740707 | |
| 3 (3등석) | female | 0.500000 | 21.750000 |
| male | 0.135447 | 26.507589 |
index를 이용한 groupby(level)
-
index가 있는 경우, groupby 함수에 level 사용 가능
- level은 index의 depth를 의미하며, 가장 왼쪽부터 0부터 증가
-
set_index 함수
column 데이터를 index 레벨로 변경 -
reset_index 함수
인덱스 초기화
df.set_index('Pclass')
# level=0 인덱스를 기준으로 쪼갠다.
# 지금은 Embarked 가 index 이기 때문에 'C', 'S', 'Q' 으로 쪼개진다.
df.set_index('Embarked').groupby(level=0).size()
groupby(함수)
- groupby(함수) =>
- 함수의 매개변수는 index 다
- 함수가 리턴하는 값이 grouping 기준이 된다!
# 나이대별 생존률 구하기
df.set_index('Age')
# groupby() 에 전달할 함수
df.set_index('Age').groupby(age_categorize).size() #연령별 분류
df.set_index('Age').groupby(age_categorize)['Survived'].mean() #연령별 생존자 평균 분류| 연령대 (Age) | 생존율 (Survival Rate) |
|---|---|
| -1 | 0.293785 |
| 0 | 0.612903 |
| 10 | 0.401961 |
| 20 | 0.350000 |
| 30 | 0.437126 |
| 40 | 0.382022 |
| 50 | 0.416667 |
| 60 | 0.315789 |
| 70 | 0.000000 |
| 80 | 1.000000 |
도전 : 이름(Name) 시작 알파벳으로 승객수 집계
# 😎도전) 이름(Name) 시작 알파벳별로 승객수 집계
# groupby(함수) 활용
"""
A 51
B 72
C 69
D 43
...
...
U 1
V 15
W 33
Y 7
Z 3
"""
df['passenger'] = 1
df.groupby(df['Name'].str[0].str.upper())['passenger'].sum()aggregate(집계) 함수 사용하기
- groupby 결과에 '집계함수'를 적용하여 그룹별 데이터 확인 가능
- 줄임형태: agg()
# 밑에 2개는 같은 결과
df.groupby(['Pclass', 'Sex'])['PassengerId'].count()
df.groupby(['Pclass', 'Sex'])['PassengerId'].aggregate("count")
# df.groupby(['Pclass', 'Sex'])['PassengerId'].aggregate(np.sum) 오류 가능성 높음
df.groupby(['Pclass', 'Sex'])['PassengerId'].aggregate(["sum", "mean", "max"])
도전: 각 객실 등급별 탑승승객인원, 생존자수, 생존률?
df.groupby(['Pclass']).aggregate(승객수=('passenger', 'sum'),생존자=('Survived','sum'),생존률=('Survived','mean'))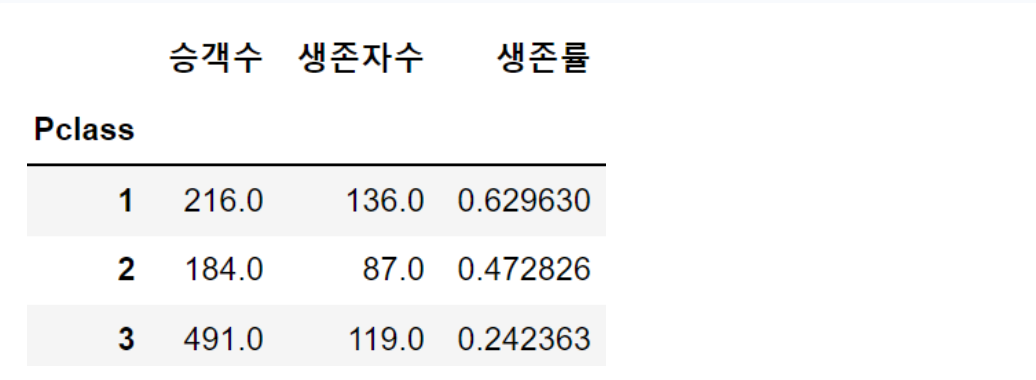
8. 정렬 및 구조 변경 (Pivot, Stack)
정렬
- 값 기준:
df.sort_values(by=['컬럼1', '컬럼2'], ascending=[True, False])
# by= 정렬기준
# 컬럼명이나 컬럼들의 리스트
df.sort_values(by='Pclass')| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | passenger |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 857 | 1 | 1 | Daly, Mr. Peter Denis | male | 51.0 | 0 | 0 | 113055 | 26.5500 | E17 | S | 1 |
| 858 | 1 | 1 | Swift, Mrs. Frederick Joel | female | 48.0 | 0 | 0 | 17466 | 25.9292 | D17 | S | 1 |
| 863 | 0 | 3 | Sage, Miss. Dorothy Edith | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S | 1 |
| 868 | 0 | 1 | Roebling, Mr. Washington Augustus II | male | 31.0 | 0 | 0 | PC 17590 | 50.4958 | A24 | S | 1 |
| 525 | 0 | 3 | O'Driscoll, Miss. Bridget | female | NaN | 0 | 0 | 14311 | 7.7500 | NaN | Q | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S | 1 |
| 889 | 0 | 3 | Johnston, Miss. Catherine Helen | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | 1 |
| 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C | 1 |
| 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q | 1 |
#내림차순
df.sort_values(by='Pclass', ascending=False)
# 우선 Pclass 오름차순, 그리고 Age 오름차순
df.sort_values(by=['Pclass', 'Age'])
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | passenger |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 306 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.92 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 1 |
| 298 | 0 | 1 | Allison, Miss. Helen Loraine | female | 2.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 1 |
| 446 | 1 | 1 | Dodge, Master. Washington | male | 4.00 | 0 | 2 | 33638 | 81.8583 | A34 | S | 1 |
| 803 | 1 | 1 | Carter, Master. William Thornton II | male | 11.00 | 1 | 2 | 113760 | 120.0000 | B96 B98 | S | 1 |
| 436 | 1 | 1 | Carter, Miss. Lucile Polk | female | 14.00 | 1 | 2 | 113760 | 120.0000 | B96 B98 | S | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 860 | 0 | 3 | Razi, Mr. Raihed | male | NaN | 0 | 0 | 2629 | 7.2292 | NaN | C | 1 |
| 864 | 0 | 3 | Sage, Miss. Dorothy Edith "Dolly" | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S | 1 |
| 869 | 0 | 3 | van Melkebeke, Mr. Philemon | male | NaN | 0 | 0 | 345777 | 9.5000 | NaN | S | 1 |
| 879 | 0 | 3 | Laleff, Mr. Kristo | male | NaN | 0 | 0 | 349217 | 7.8958 | NaN | S | 1 |
| 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | 1 |
# Pclass 오름차순, Age 내림차순
df.sort_values(by=['Pclass', 'Age'], ascending=[True, False])
- 인덱스 기준:
df.sort_index()
# sort_index() index 기준으로 정렬
df.sort_index(ascending=False)
# index 기준으로 내림차순| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | passenger |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q | 1 |
| 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C | 1 |
| 889 | 0 | 3 | Johnston, Miss. Catherine Helen | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | 1 |
| 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S | 1 |
| 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 |
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1 |
# 컬럼 이름 오름차순 정렬.
df.sort_index(axis=1)| Index | Age | Cabin | Embarked | Fare | Name | Parch | PassengerId | Pclass | Sex | SibSp | Survived | Ticket | passenger |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22.0 | NaN | S | 7.2500 | Braund, Mr. Owen Harris | 0 | 1 | 3 | male | 1 | 0 | A/5 21171 | 1 |
| 1 | 38.0 | C85 | C | 71.2833 | Cumings, Mrs. John Bradley | 0 | 2 | 1 | female | 1 | 1 | PC 17599 | 1 |
| 2 | 26.0 | NaN | S | 7.9250 | Heikkinen, Miss. Laina | 0 | 3 | 3 | female | 0 | 1 | STON/O2. 3101282 | 1 |
| 3 | 35.0 | C123 | S | 53.1000 | Futrelle, Mrs. Jacques Heath | 0 | 4 | 1 | female | 1 | 1 | 113803 | 1 |
| 4 | 35.0 | NaN | S | 8.0500 | Allen, Mr. William Henry | 0 | 5 | 3 | male | 0 | 0 | 373450 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 27.0 | NaN | S | 13.0000 | Montvila, Rev. Juozas | 0 | 887 | 2 | male | 0 | 0 | 211536 | 1 |
| 887 | 19.0 | B42 | S | 30.0000 | Graham, Miss. Margaret Edith | 0 | 888 | 1 | female | 0 | 1 | 112053 | 1 |
| 888 | NaN | NaN | S | 23.4500 | Johnston, Miss. Catherine Helen | 2 | 889 | 3 | female | 1 | 0 | W./C. 6607 | 1 |
| 889 | 26.0 | C148 | C | 30.0000 | Behr, Mr. Karl Howell | 0 | 890 | 1 | male | 0 | 1 | 111369 | 1 |
| 890 | 32.0 | NaN | Q | 7.7500 | Dooley, Mr. Patrick | 0 | 891 | 3 | male | 0 | 0 | 370376 | 1 |
Pivot / Pivot Table
- pivot: 데이터 재구조화 (중복 데이터가 있으면 에러 발생)
- pivot_table: 중복 데이터가 있을 때
aggfunc를 통해 요약 가능 (기본값은 평균)
Pivot
예시
df = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '화요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df| 지역 | 요일 | 강수량 | 강수확률 | |
|---|---|---|---|---|
| 0 | 서울 | 월요일 | 100 | 80 |
| 1 | 서울 | 화요일 | 80 | 70 |
| 2 | 서울 | 수요일 | 1000 | 90 |
| 3 | 경기 | 월요일 | 200 | 10 |
| 4 | 경기 | 화요일 | 200 | 20 |
| 5 | 부산 | 월요일 | 100 | 30 |
| 6 | 서울 | 목요일 | 50 | 50 |
| 7 | 서울 | 금요일 | 100 | 90 |
| 8 | 부산 | 화요일 | 200 | 20 |
| 9 | 경기 | 수요일 | 100 | 80 |
| 10 | 경기 | 목요일 | 50 | 50 |
| 11 | 경기 | 금요일 | 100 | 10 |
#전치
df.T| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 지역 | 서울 | 서울 | 서울 | 경기 | 경기 | 부산 | 서울 | 서울 | 부산 | 경기 | 경기 | 경기 |
| 요일 | 월요일 | 화요일 | 수요일 | 월요일 | 화요일 | 월요일 | 목요일 | 금요일 | 화요일 | 수요일 | 목요일 | 금요일 |
| 강수량 | 100 | 80 | 1000 | 200 | 200 | 100 | 50 | 100 | 200 | 100 | 50 | 100 |
| 강수확률 | 80 | 70 | 90 | 10 | 20 | 30 | 50 | 90 | 20 | 80 | 50 | 10 |
# pivot()
- dataframe의 형태를 변경
- 인덱스, 컬럼, 데이터로 사용할 컬럼을 명시
# pivot(index=None, columns=None, values=None)
# index 로 지정할 컬럼
# column 으로 지정할 컬럼
# values 나머지 채울 값들.
# 이제 지역별로(index) 요일별(column) 강수량/강수확률(value)을 보고싶다
df.pivot(index='지역', columns='요일')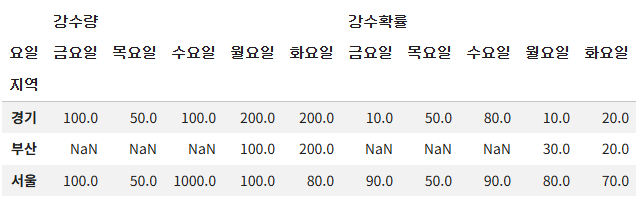
# ↑ 월~ 금 '요일' 이 두번 들어감. 강수량, 강수확률 <-- 2개의 컬럼이 있기 때문
# 부산 의 경우 금/목/수 데이터가 없다.
# '지역', '요일' 이 같은 데이터가 중복되어 있으면 에러난다.!
df.loc[len(df)] = pd.Series(['경기', '금요일', 111, 11], index=['지역', '요일', '강수량', '강수확률'])
df
df.pivot(index='지역', columns='요일')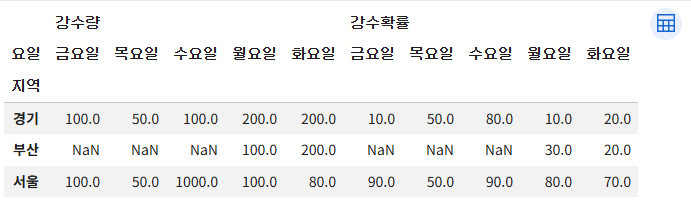
#삭제
df.drop(12, inplace=True)
#인덱스 12인 자료 삭제
# 거꾸로 해보자
df.pivot(index='요일', columns='지역')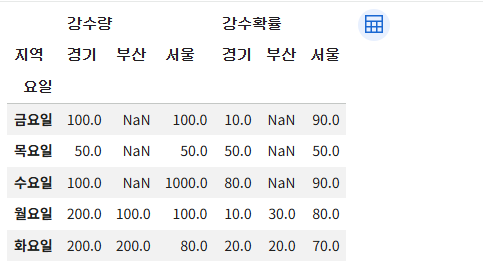
df.pivot(index='요일', columns='지역', values='강수량')
#df.pivot(index='요일', columns='지역')['강수량'] 와 같다. 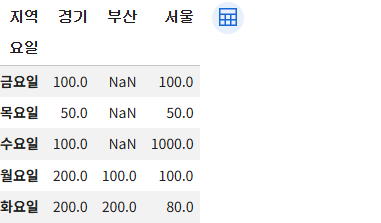
Pivot_table()
- 기능적으로 pivot과 동일
- pivot과의 차이점
- 중복되는 모호한 값이 있을 경우, aggregation 함수 사용하여 값을 채움
pd.pivot_table(df, index='지역', columns='요일')
# 중복데이터를 만들어 본다. 서울-월요일
df2 = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '월요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df2 # 서울 - 월요일 <-- 2개 있다.
# pivot() 은 중복된 엔트리가 있으면 오류발생
# pivot_table() 은 중복된 엔트리는 aggfunc= 를 사용하여 새로운 값 대체
# aggfunc='mean' (기본값)
# 서울, 월요일의 '평균값' 으로 채워진다. (디폴트)
pd.pivot_table(df2, index='지역', columns='요일', aggfunc='mean')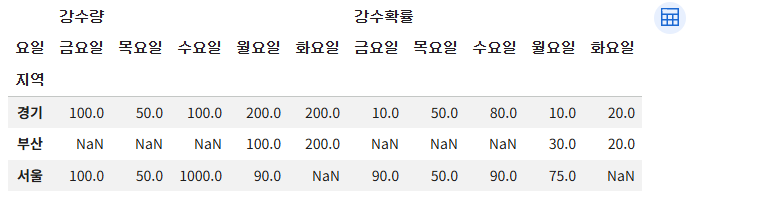
# max로 바꿀 수 있다.
pd.pivot_table(df2, index='지역', columns='요일', aggfunc='max') Stack & Unstack
- stack: 컬럼 레벨 -> 인덱스 레벨 (데이터를 아래로 쌓음)
- unstack: 인덱스 레벨 -> 컬럼 레벨 (옆으로 펼침)
- 둘은 역의 관계에 있음
new_df = df.set_index(['지역', '요일'])
new_df
#컬럼 레벨 -> 인덱스 레벨
# unstack() : index(row) -> column
# unstack(level=-1, fill_value=None)
# level : 인덱스의 레벨
# new_df 의 경우 지역 의 인덱스 레벨이 0 이다
# -1 은 오른쪽 끝 인덱스 '요일' 이 컬럼이다.
# level=-1 (디폴트) 였던 '요일' index 가 '컬럼' 으로 올라간다
new_df.unstack()
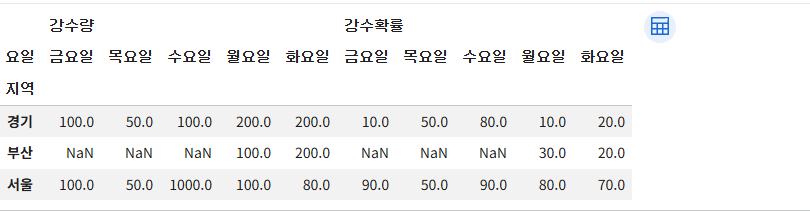
# level=0 인텍스가 컬럼으로 올라감
new_df.unstack(0)
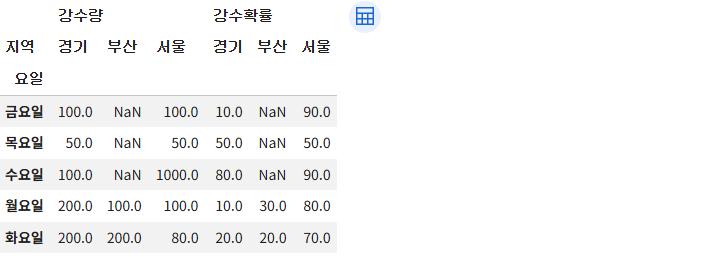
# stack() : column -> index(row)
# stack(level=-1, dropna=True)
# level : 컬럼의 레벨
df2 = new_df.unstack(0)
# level=0 의 컬럼 이 index 로 내려옴
df2.stack(0, future_stack=True)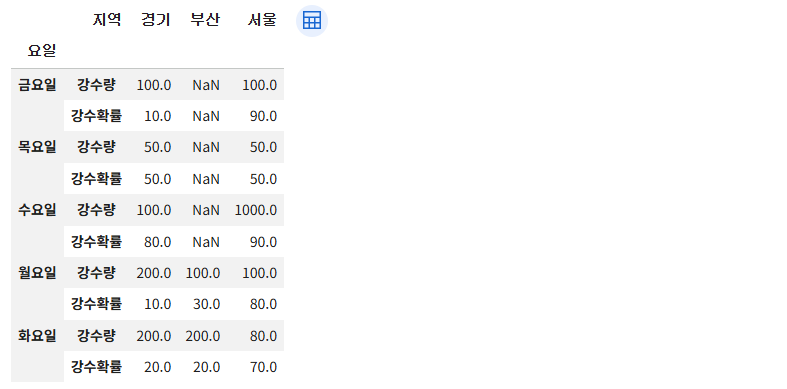
df2.stack(1)
# 모든 컬럼을 다 내리면? (즉 컬럼이 없어지면) 결과는 -> Series
df2.stack().stack()
# [도전]
# 두 index 위치 (level) 변경하기
new_df.unstack(0).stack()
8. 데이터 병합 (Concat)
여러 데이터프레임을 하나로 합칩니다.
- 행 단위(axis=0): 위아래로 이어 붙임
# 행 방향으로 병합 (axis=0)
pd.concat([df1, df2])- 열 단위(axis=1): 좌우로 옆에 붙임
# 열 방향 병합 (axis=1)
pd.concat([df1, df2], axis=1)- 함수:
pd.concat([df1, df2], axis=0)

Hard Trying