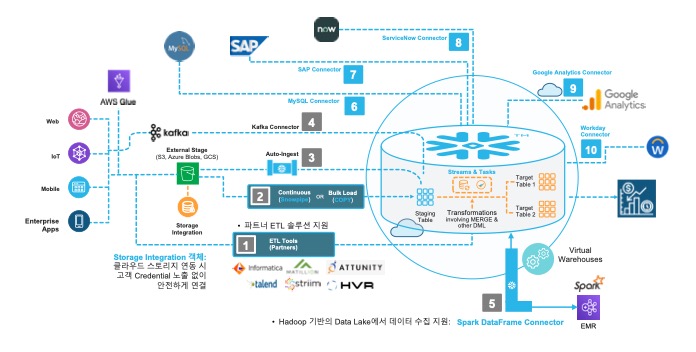
1. 다양한 적재 옵션
Option 1. ETL툴에서 직접 적재
- 상용 또는 Open Source ETL 툴을 이용하여 직접 ETL 수행
- Snowflake Marketplace에서 다양한 Partner 솔루션 제공
- 고려사항 : 3rd Party ETL 솔루션 라이센스 및 ETL Job 유지관리

Option 2. 데이터 파일 로드
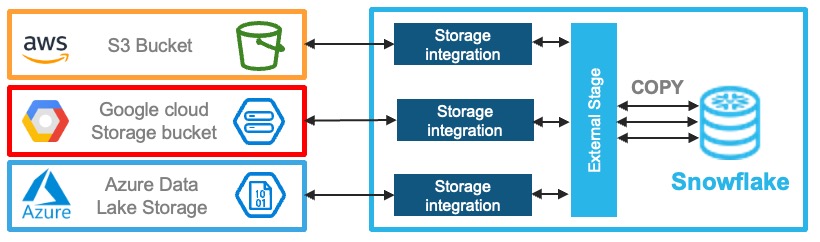
COPY를 이용한 클라우드 스토리지 파일 적재
- Snowflake 계정을 호스팅하는 클라우드 제공업체에 관계없이 클라우드 스토리지의 파일 적재 가능
- Amazon S3
- Google Cloud Storage
- Microsoft Azure Blob Storage
- Snowflake의 COPY 명령어로 적재 또는 반대로 export 가능
- 고려사항 : 클라우드 스토리지와 연계를 위해 클라우드의 IAM 설정
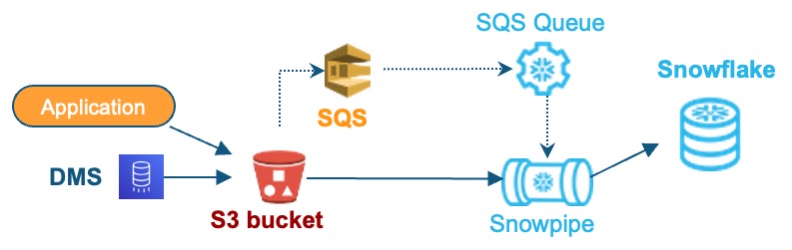
Option 3. 데이터 자동 적재
Snowpipe를 이용한 데이터 파일 자동 적재
- S3에 데이터파일이 준비되는 즉시 이벤트 알림을 통해 적재 작업 자동 시작
- S3에 저장되는 파일의 형식이 Parquet 일 경우 테이블 스키마 관리의 편의성 향상
- 고려사항
- 원천 시스템에서 S3로 ETL 대상 파일을 만드는 과정 필요
- 필요시 별도의 데이터 추출 툴 필요
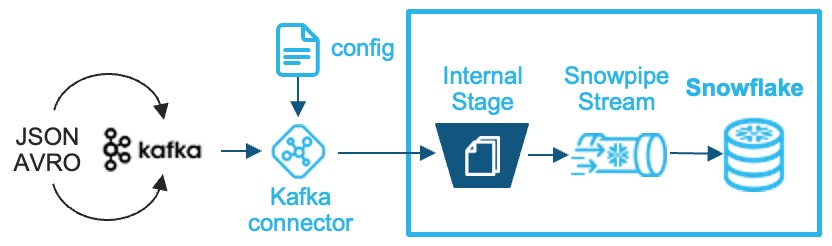
Option 4. 스트림 데이터 연속 적재
Kafka connector
- 실시간 데이터 수집을 위한 업계 표준적인 카프카 연계 방안
- 스트리밍 데이터 적재로 실시간 변경 사항 반영 가능
- 처리 과정
- 커넥터는 자동으로 스테이지, 파일, 파이프 생성
- 스트림 데이터는 내부 Snowflake 스테이지에 로드
- Snowpipe 서비스 API를 트리거
- 메시지는 대상 테이블의 variant 컬럼에 기록
- 적재 프로세스 완료 후 내부 스테이지의 모든 파일 정리
- 고려사항 : 소스시스템에서 Kafka 연계 구성 및 유지 관리 필요
2. 데이터 적재 후 파이프라인 개선
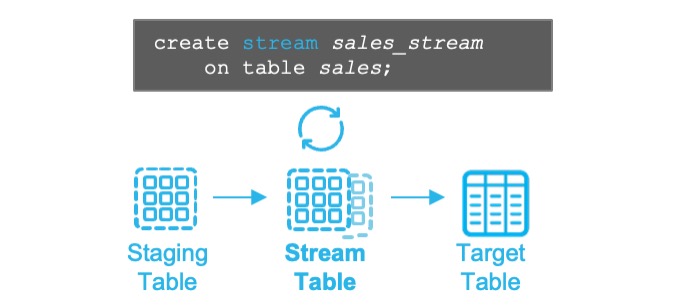
STREAM 활용한 CDC 처리
- Stage Table의 변경 사항을 자동으로 Stream 테이블에 기록
- Stream 테이블에 데이터가 기록될 때 추가 메타컬럼 생성
- METADATA$ACTION
- METADATA$ISUPDATE
- METADATA$ROWID
- Stream 테이블의 데이터는 다른 target 테이블에 기록될 때 자동 삭제
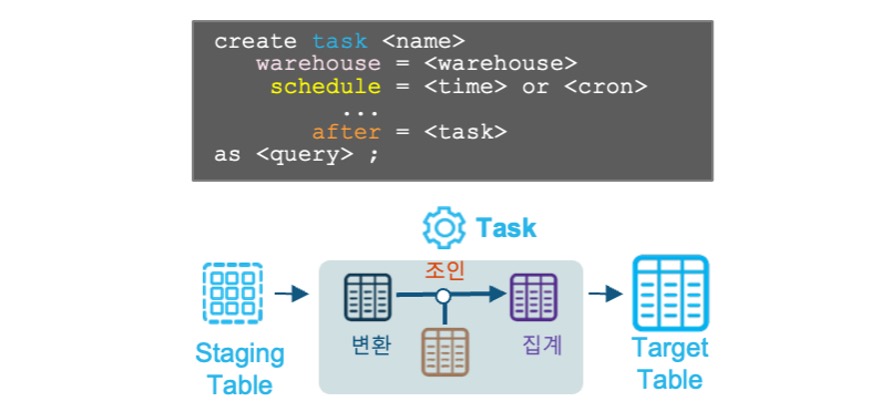
Task를 활용하여 Job 스케줄링
- 작업 스케줄링이 가능하므로 별도의 외부 스케줄러 설정 불필요
- SQL 또는 Procedure를 정한 스케줄에 실행
- 다수의 Task가 종속성을 가지고 선,후행 관계의 데이터 파이프라인 자동화 가능
- 수행 웨어하우스 지정하거나 서버리스 수행
- 작업 스케줄 지정 방법
- 시간 주기
- Cron 구문 설정
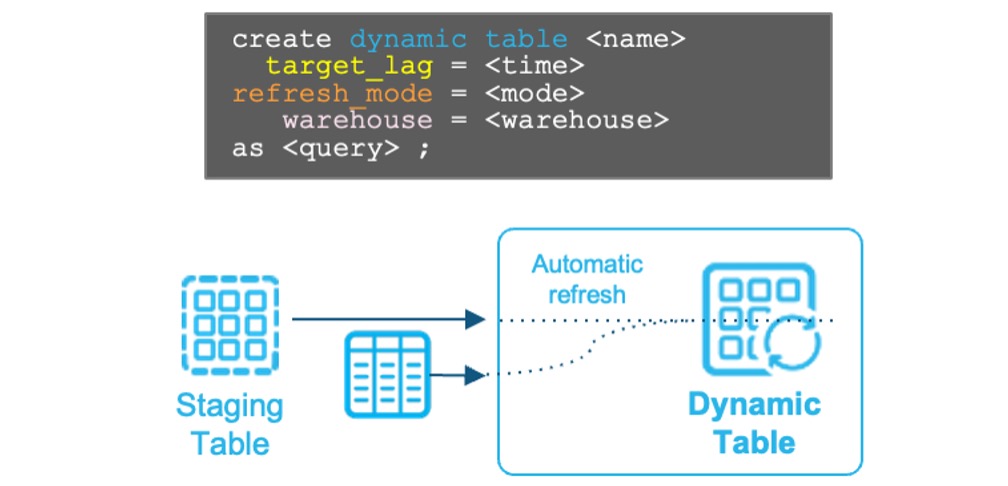
Dynamic Table 파이프라인
복잡한 데이터 파이프라인을 Dynamic Table로 간소화
- 선언적 접근 방법으로 복잡한 파이프라인을 쉽게 생성
- 낮은 레이턴시로 증분 데이터 자동 새로 고침
- 데이터 변환 로직을 쿼리 또는 프로시저로 쉽게 작성
3. 예시
Snowpipe, Stream, Task 예시
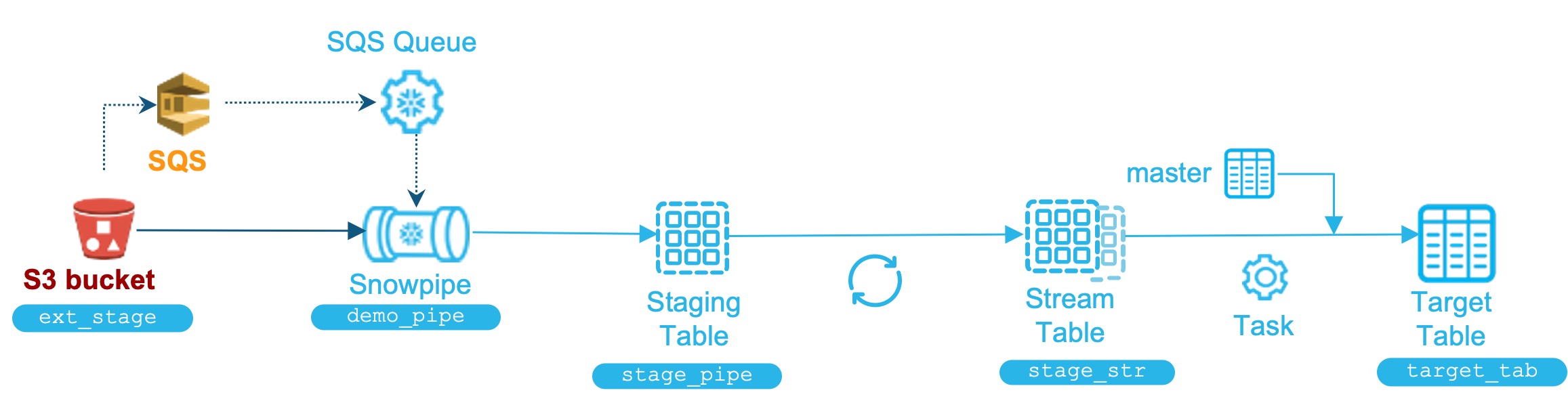
- Stage 테이블 생성
create table stage_pipe ( file_name varchar, file_row_num number, data variant ) ; - Snowpipe 생성
create pipe demo_pipe auto_ingest=true as copy into stage_pipe from (select metadata$filename, metadata$file_row_number, $1 from @ext_stage(file_format => my_json_format)); - Stream 테이블 생성
create stream stage_str on table stage_pipe ; - Task 생성
create task task_stream_to_target warehouse = task_wh schedule = '5 minute' when SYSTEM$STREAM_HAS_DATA('stage_str') as insert into target_tab select file_name, file_row_num, data:"lat"::STRING AS latitude, data:"lon"::STRING AS longitude, -- 중략 -- data:"hex_id"::STRING AS hex_id, m.model_name from stage_str left join master m on hex_id = m.code where METADATA$ACTION = 'INSERT' ; alter task task_stream_to_target resume ;
Dynamic Table 예시
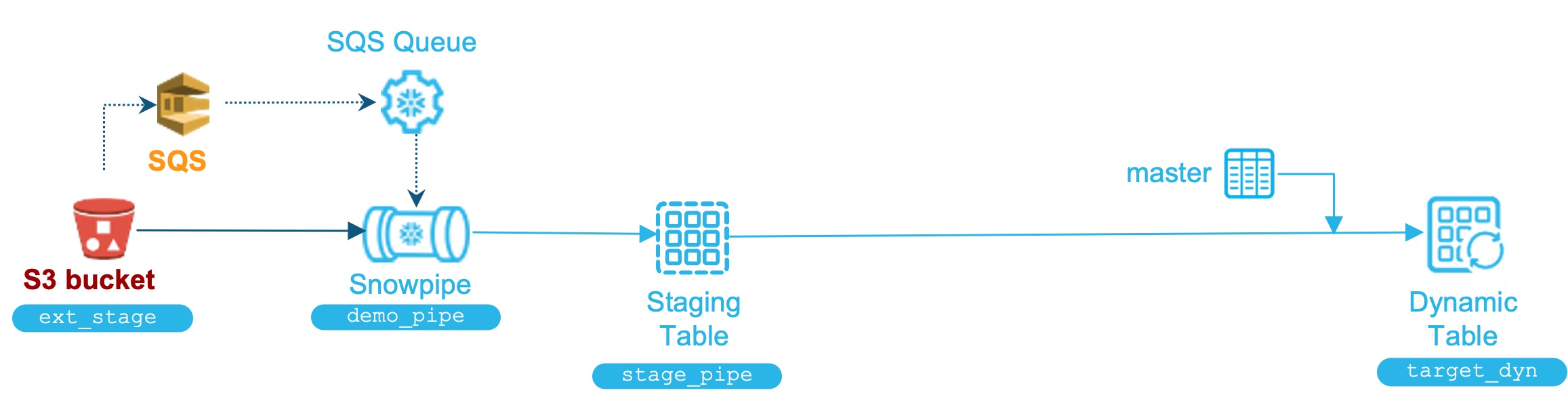
- Dynamic 테이블 생성
create dynamic table target_dyn target_lag = '5 minute' refresh_mode = incremental warehouse = dynamic_wh as select file_name, file_row_num, data:"lat"::STRING AS latitude, data:"lon"::STRING AS longitude, -- 중략 -- data:"hex_id"::STRING AS hex_id, m.model_name from stage_pipe left join master m on hex_id = m.code ;

Snowflake Korea SE