1. 손쉬운 반정형 데이터 처리
-
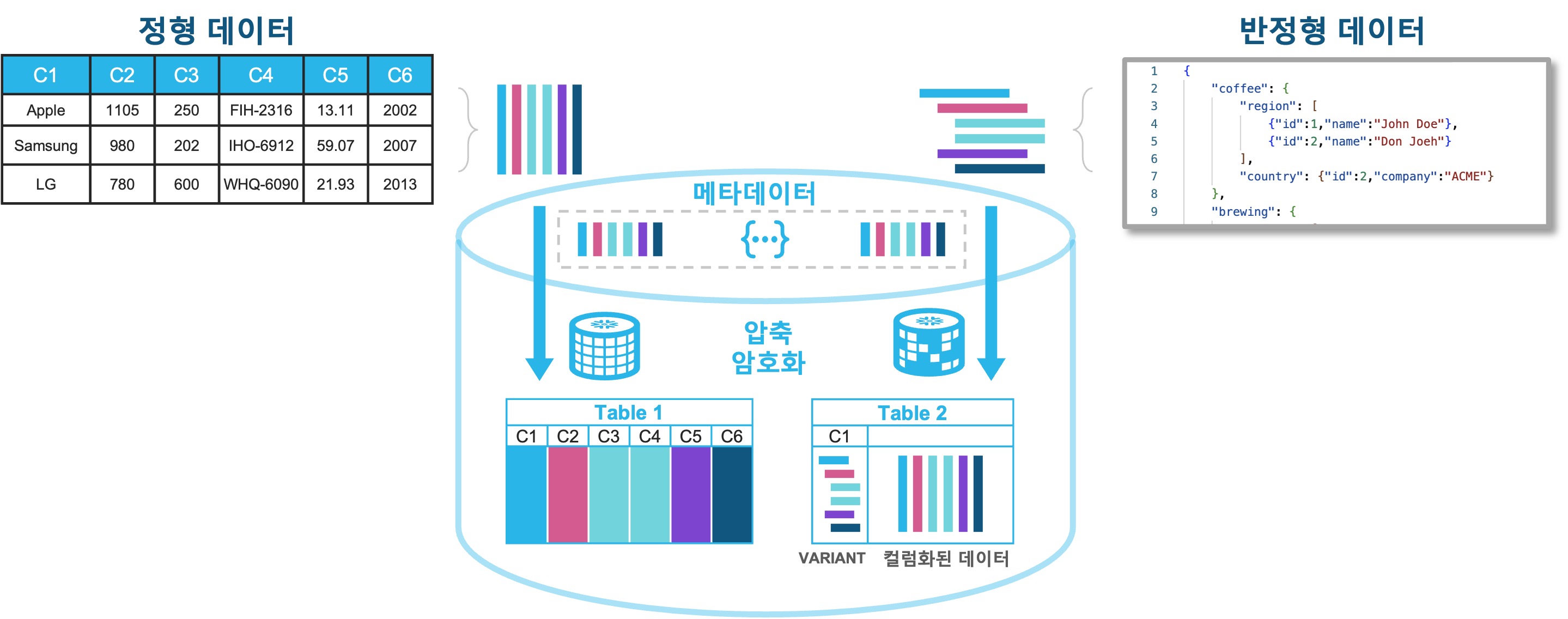
Snowflake는 단일 플랫폼에서 정형 및 반정형 데이터를 동시에 처리합니다.
- 다양한 데이터 유형에 대한 최적화된 스토리지 지원
- 유연한 스키마 – 정형 및 반정형 Native 지원
- 정형/반정형 데이터를 단일 플랫폼에서 처리
-
특히 반정형 데이터 처리에 대한 상세 내용은 다음과 같습니다
- 지원 데이터 유형 : JSON, Parquet, ORC, Avro, XML
- Snowflake 저장 타입 : Array, Object, Variant
- 반정형 처리 방식의 특징
- 기존 DB와 달리 반정형 데이터를 위한 복잡한 변환 과정 불필요
- VARIANT data type 지원
- 원본 데이터를 그대로 저장
- 데이터 수집시 데이터 컬럼화 및 메타데이터 생성
- SQL로 처리 가능: 점 표기법
SELECT c1:coffee.region.name as region FROM JSON_L0_Table;
2. Flatten
중첩된 반정형 데이터 분해
반정형 데이터를 구조화된 테이블 형태의 모양으로 보이기 위해서는 점 표기법(dot notation)을 사용합니다.
그런데, 배열이나 JSON과 같은 반정형 데이터 안에는 중첩된 형태로 또 다시 배열이나 JSON 형태의 데이터가 만들어 질 수 있습니다. 이런 경우, 단순히 점 표기법만으로 데이터를 구조화된 테이블 형태의 뷰로 보이도록 만들려면 점 표기법이 너무 많이 사용되어 가독성이 떨어지게 됩니다.
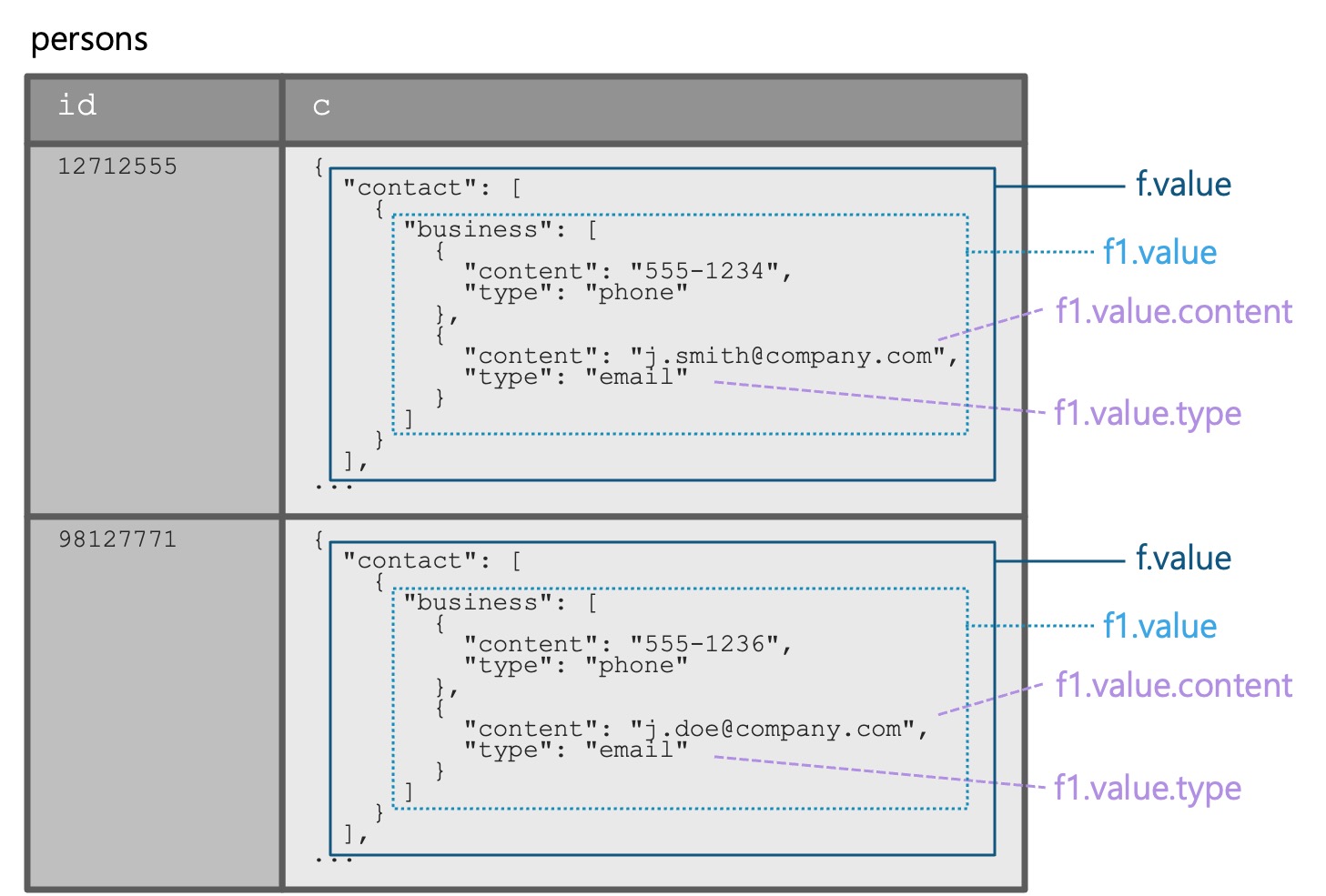
Flatten 함수는 중첩 형태의 반정형 데이터 값을 여러 행으로 분해하여 조회할 수 있도록 만듭니다
- 입력 : VARIANT, OBJECT 또는 ARRAY
- FROM 절에서 선행하는 다른 테이블을 참조하는 상관 관계를 포함한 인라인 뷰를 생성하는 테이블 함수
- 반정형 데이터를 관계형 표현으로 변환하는데 사용

- 사용 예시
왼쪽의 flatten 쿼리를 이용해서 오른쪽과 같은 정형화된 데이터 구조로 변환합니다. flatten 함수에서 사용된 input과 path는 아래 샘플 데이터의 구조에서 확인할 수 있습니다.

3. Infer_schema
반정형 데이터 파일의 스키마 자동 감지
내부 시스템에서 정형화된 형태로 데이터를 관리하는 경우가 아니라 외부의 데이터를 수집하고 통합하는 경우 컬럼 정보가 포함되어 있는 반정형 데이터를 주로 사용하게 됩니다. 이때 테이블화 시킬 수 있는 컬럼 정보를 별도로 제공받지 못하면 데이터 파일을 열어 테이블 구조를 만들 수 있는 컬럼 정보를 알아내야 합니다.
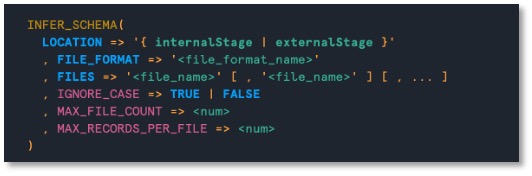
infer_schema 함수는 데이터 파일로부터 테이블 DDL을 만들 수 있도록 컬럼 정보를 추출합니다. 이를 이용하여 데이터가 저장될 타켓 테이블을 생성할 때 컬럼 정보를 자동 생성하게 만들 수 있습니다.
- 파일이 있는 스테이지의 경로와 파일명 지정
- 저장된 파일의 형식 지정
- Create table, create external table에서 using template 절에 infer_schema의 출력 결과를 사용하여 새 테이블의 DDL을 자동 생성 가능
-
사용예시
-
Stage에 있는 파일 정보 조회
SELECT * FROM TABLE ( INFER_SCHEMA ( LOCATION=>'@mystage/json/' , FILE_FORMAT=>'my_json_format' ) );데이터 파일을 읽어 컬럼 이름, 적절한 데이터 타입 등을 추출합니다 -
파일 정보를 이용하여 테이블 생성
CREATE TABLE mytable USING TEMPLATE ( SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*)) FROM TABLE ( INFER_SCHEMA( LOCATION=>'@mystage/json/', FILE_FORMAT=>'my_json_format' ) ) ); -
생성된 테이블에 데이터 적재 (자동으로 구조화)
COPY INTO mytable FROM @mystage/json/ FILE_FORMAT = ( FORMAT_NAME = my_json_format ) MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE ;
-
4. Schema Evolution
데이터 파일의 구조 변경 자동 감지로 테이블 스키마 진화
데이터 적재 시 파일 내의 변경된 스키마의 내용을 감지하여 테이블의 스키마를 자동으로 변경하는 Snowflake의 기능을 Schema evolution (스키마 진화)이라 합니다
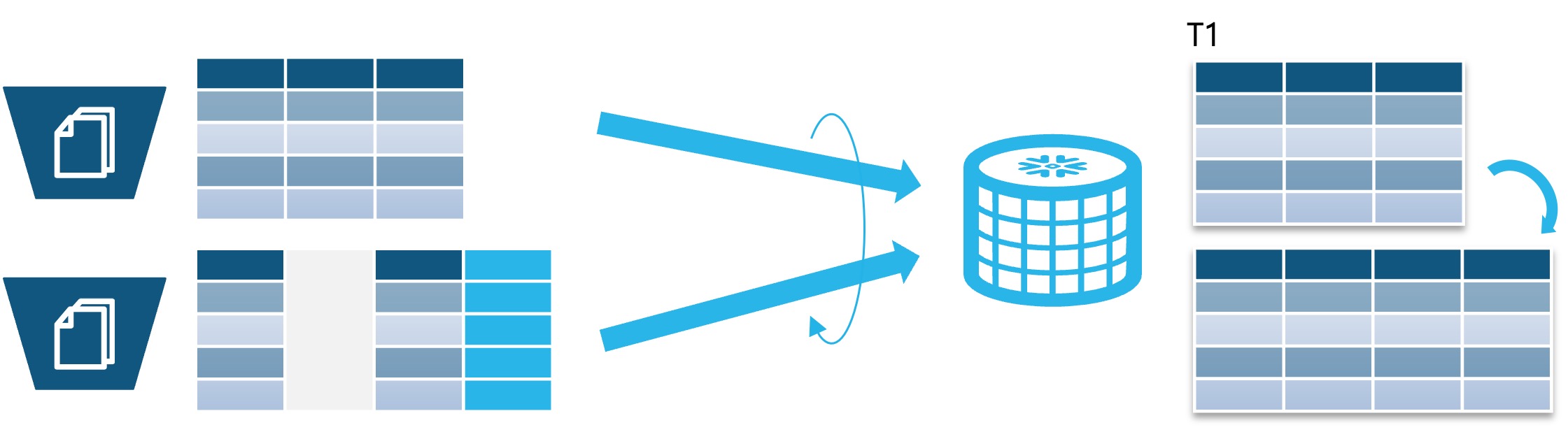
- 지원 파일 포맷 : Apache Avro, Apache Parquet, CSV, JSON, ORC
- Schema Evolution이 일어나는 시점
- copy문 수행
- Snowpipe 데이터 로드 중
- Snowpipe Stream 데이터 로드 중
- Schema Evolution을 사용하기 위한 설정
ALTER TABLE T1 SET ENABLE_SCHEMA_EVOLUTION = TRUE;
