import pandas as pd #판다스 패키지 불러오기
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 모델 불러오기
from sklearn.tree import DecisionTreeClassifier # 의사결정 나무 모델 불러오기탐색적 자료 분석
train.head(10)
train.info()- PassengerId : 탑승객의 고유 아이디
- Survival : 생존여부(0: 사망, 1: 생존)
- Pclass : 등실의 등급(1: 1등급, 2: 2등급, 3: 3등급)
- Name : 이름
- Sex : 성별
- Age : 나이
- Sibsp : 함께 탑승한 형제자매, 아내 남편의 수
- Parch: 함께 탑승한 부모, 자식의 수
- Ticket: 티켓번호
- Fare: 티켓의 요금
- Cabin: 객실번호
- Embarked: 배에 탑승한 위치(C = Cherbourg, Q = Queenstown, S = Southampton)
결측치 확인하기
pd.DataFrame.fillna()
- 결측치를 채우고자 하는 column과 결측치를 대신하여 넣고자 하는 값을 명시해주어야 한디.(대부분은 평균 혹은 중앙값으로 채워놓음)
- 범주형 변수일 경우, 최빈값으로 대체할 수 있다.
train.isna().sum()결측치를 확인했을 때, Age의 결측치가 177개가 나왔다. 결측치에 나이의 중앙값을 넣어주었다.
단, 여기서 inplace=true 를 하지 않으면 변경된 값으로 저장되지 않는다.
train['Age'].median() #중앙값 28
train['Age'] = train['Age'].fillna(28) Embarked(배에 탑승한 위치)에 대한 결측치는 가장 많이 등장하는 문자열로 대체한다.
S위치의 값이 가장 많음으로 결측값을 S로 대체한다.
#Embarked칼럼에 들어있는 데이터의 갯수 확인
train['Embarked'].value_counts()
#'S'데이터로 결측값 대체
train['Embarked'] = train['Embarked'].fillna('S')pd.Series.map()
시리즈 내 값을 변환할 때 사용하는 함수.
Sex칼럼의 문자형 데이터를 정수형으로 바꾸기 위해 사용한다.
train['Sex'] = train['Sex'].map({'male':0, 'female':1}) #남자는 0, 여자는 1상관관계 구하기
필요한 데이터의 결측값은 채우고, 문자형은 정수형으로 바꾸었으니 상관관계를 구해보자.
!pip install seaborn
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as npDtype값이 Object인 칼럼은 제외.
corr = train[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].corr(method = 'pearson')
fig, ax = plt.subplots(figsize=(7,7)) #표사이즈
mask = np.zeros_like(corr.values, dtype = np.bool_)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(corr, mask = mask,
annot = True, linewidth=.5,
cmap = 'RdYlBu_r', cbar_kws = {"shrink": .3}, # shrink cbar(cmap)
vmin = -1, vmax = 1)
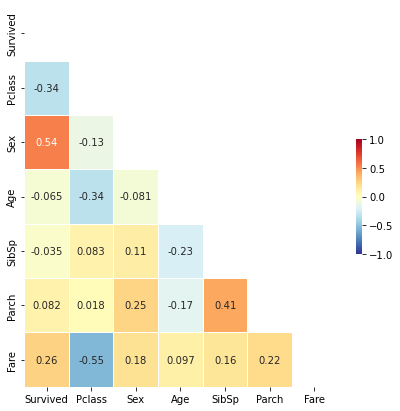
plt.show()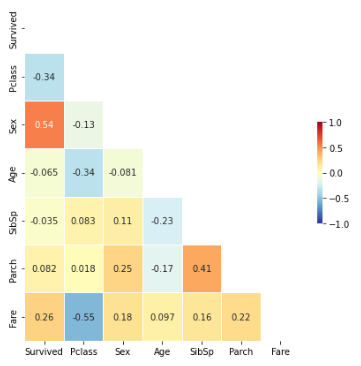
분석결과 생존확률(Survived)은 성별(Sex), 등실의 등급(Pclass), 티켓 요금(Fare)와 큰 관계가 있다는 것을 확인 할 수 있다.
성별의 평균
train.groupby('Sex').mean() 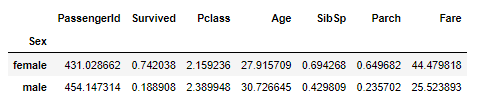
성별 평균의 값을 구했을 때 female의 survived은 0.742038, male은 0.188908이었다. 이를 통해 여성의 생존확률이 더 높았다는 것을 확인 할 수 있다. Pclass와 Age도 비슷한 것을 보면 단순히 '여성' 이었기 때문에 더 많이 살아남은 것이다.
좌석등급의 평균
train.groupby('Pclass').mean() #좌석등급의 평균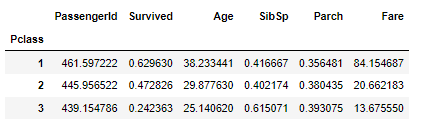
예상했듯, 좌석 등급이 좋을 수록 생존확률이 높았다.
train.groupby('Pclass').mean()['Survived'].plot(kind = "bar", rot = 2)
#여기서 인덱스는 Pclass 숫자 value는 생존률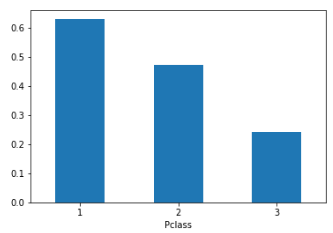
나이의 분포
train['Age'].plot(kind = 'hist', bins = 30, grid = True)
#bins : 막대 그래프 사이의 간격으로 숫자를 늘릴수록 간격이 많아진다.
#grid : 표의 그리드를 표현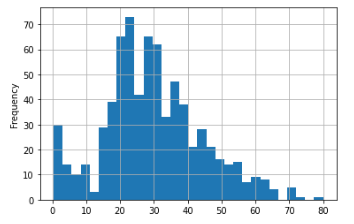
train.plot(x = 'Age', y = 'Fare', kind = 'scatter')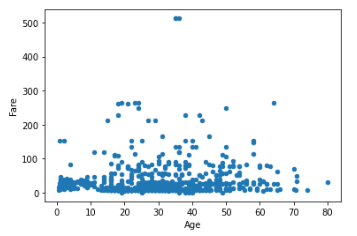
티켓의 요금과 나이는 상관이 없다는 것을 분포도를 통해 확인할 수 있다. 20대의 생존확률이 높다는 것은 단순히 20대가 많았기 때문이다.
모델 구축
탑승객의 인적사항 정보(성별, 탑승 등급)를 바탕으로 생존률을 예측해 보는 모델을 구축.
X_train = train[['Sex', 'Pclass']]
Y_train = train['Survived']
test['Sex'] = test['Sex'].map({'male':0, 'female':1})
X_test = test[['Sex', 'Pclass']]lr = LogisticRegression()
dt = DecisionTreeClassifier()
#모델 데이터를 학습시킨다.
lr.fit(X_train, Y_train)
dt.fit(X_train, Y_train)모델 예측
Ir_pred = lr.predict_proba(X_test)[:,1]
dt_pred = dt.predict_proba(X_test)[:,1]
lr.predict_proba(X_test) #첫번째는 사망확률 두번째는 생존확률#우리에겐 생존확률만 필요하므로 뒤에 [:, 1]을 붙임
lr_pred = lr.predict_proba(X_test)[:, 1]
dt_pred = dt.predict_proba(X_test)[:, 1]탑승객별 생존확률
submission['Survived'] = lr_pred
submissionCSV파일 저장
submission.to_csv('logistic_regression_pred.csv', index = False) #index = False를 안할시 인덱스도 같이 저장되면서 오류가 생길 수 있음
submission['Survived'] = dt_pred
submission.to_csv('decision_tree_pred.csv', index = False)
로그를 남겨보자