윈도우함수 분석함수 집계함수
OVER(PARTITION BY 그룹영역 ORDER BY 누적값 표시)
ORDER BY는 PK처럼 유니크한 값이여야 함
UNBOUNDED PRECEDING : 맨처음부터
SUM(v) OVER(ORDER BY n ROWS UNBOUNDED PRECEDING) x
SUM(v) OVER(ORDER BY n RANGE UNBOUNDED PRECEDING) yN열을 기준으로 ROWS(1개열)한 x
->1씩 차곡차곡 더해짐 SUM(v)
N열을 기준으로 RANGE(범위)한 y
같은 범위는 서로 합쳐서SUM(v) 보여줌
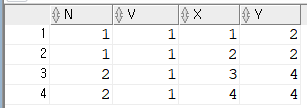
ORDER BY N1 RANGE
N1의 범위...
rows 는 행별로 각각 sum 하지만
range 는 같은 값이면 함께 sum 합니다.
단일 preceding은 "이전의"라고 해석하시면 될거예여
UNBOUNDED PRECEDING : PARTITION의 첫 번째 로우에서 윈도우가 시작
n PRECEDING : n 번째 로우에서 시작
PRECEIDING : 이전 로우
range between 100 preceding and 200 following
-100번째 로우부터 현재까지, 현재부터 200번째 로우까지
SELECT 상품분류코드 , AVG(상품가격) AS 상품가격
,COUNT(*) OVER(ORDER BY AVG(상품가격)
RANGE BETWEEN 10000 PRECEDING
AND 10000 FOLLOWING) AS 유사계수
FROM 상품
GROUP BY 상품분류코드
코드 가격평균
사과 10만원
포도 11만원
키위 12만원
망고 20만원
집계 결과에 위 분석함수 수행 결과를 추가하면
코드 가격평균 유사건수
사과 10만원 2건 - 10만원에서 만원 차이 나는 건수(9만원~11만원)
포도 11만원 3건 - (10~12만원)
키위 12만원 2건 - (11~13만원)
망고 20만원 1건 - (19~20만원)
출처 : https://cafe.naver.com/sqlpd/38873
ANY
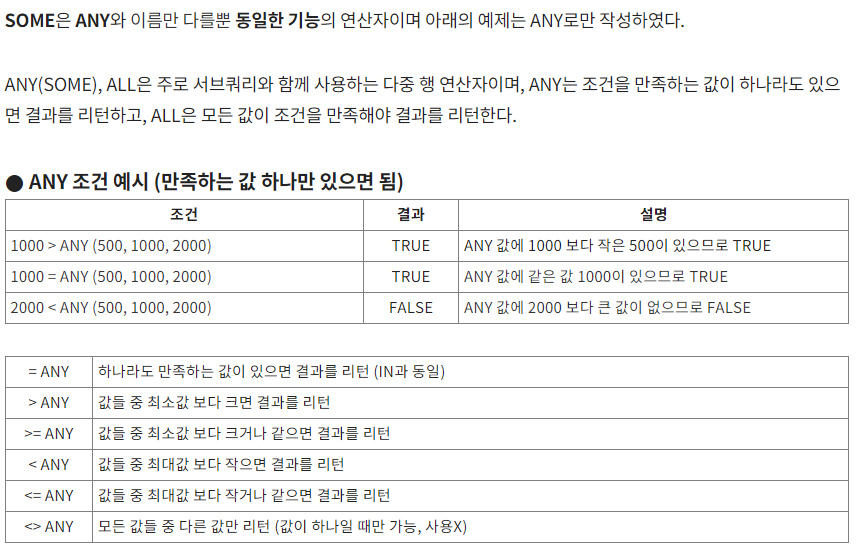
출처 https://gent.tistory.com/287
GROUPING SETS 및 ROLLUP 관련 질문들을 살펴보니 논란이 많은 듯 하여 정리해 봅니다.
GROUP BY GROUPING SETS (a, (a, b)) 는
GROUP BY a, ROLLUP(b) 와 동일합니다.
GROUP BY GROUPING SETS ((a, b, c), (a, b), (b), ())
GROUP BY ROLLUP (b, a, c) 와 동일합니다.
○ 그룹 소계 함수 비교
1. ROLLUP 은 단계별 합계
2. CUBE 는 가능한 모든 조합별 합계
3. GROUPING SETS 는 지정한 조합별 합계
4. 괄호는 묶음 처리
○ 사용 예시
1. ROLLUP(a, b, c) <- 우측 항목을 하나씩 단계별로 제거
- (a, b, c)
- (a, b)
- (a)
- ()
- CUBE(a, b)
- (a, b)
- (a)
- (b)
- ()
- ROLLUP(a, (b, c), d) <- (b,c) 를 한 묶음으로 처리
- (a, (b, c), d)
- (a, (b, c))
- (a)
- ()
- GROUPING SETS (a, (b, c))
- (a)
- (b, c)
출처 https://cafe.naver.com/sqlpd/24282
총합행 제외하고 null이 있는 칼럼이 하나면 롤업 둘이면 큐브요
총합행 null null이 없으면 grouping sets!!
