
그래프 DFS/BFS
- 노드(vertex)와 간선(edge)을 이용한 비선형 데이터 구조
인접 행렬 그래프
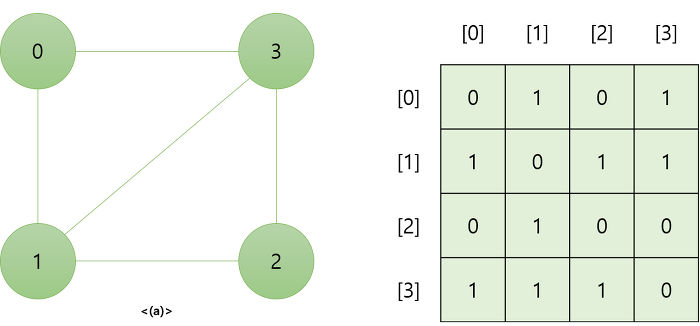
- 그래프의 정점을 2차원 배열로 만든 것
- 정점의 개수가 N개라면 N*N 형태의 2차원 배열로 나타냄
- 행과 열은 정점을 의미하고, 각 원소들은 정점 간의 간선의 유무(가중치)를 나타냄
장점
- 정점을 연결하는 간선의 존재 여부를 O(1) 안에 알 수 있음
- 정점의 차수는 O(N) 안에 알 수 있음
단점
- 해당 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 순회해야 함
- 그래프에 존재하는 모든 간선의 수는 O(N*N) 안에 알 수 있음
인접 리스트 그래프
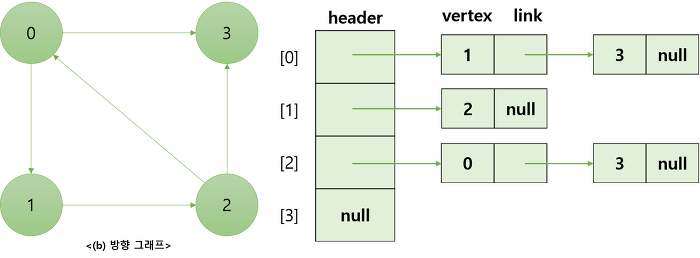
-
정점의 개수만큼 인접 리스트가 존재하며, 각각의 인접 리스트에는 인접한 정점 정보가 저장되는 것
⇒ 각 정점에 인접한 정점들을 연결리스트(Linked List)로 표현
-
그래프는 각 인접 리스트에 대한 헤드 포인터를 배열로 갖음
-
무방향 그래프의 경우 간선이 추가되면 각각의 정점의 인접 리스트에 반대편 정점의 노드를 추가해야 함
장점
-
실제 연결된 노드들에 대한 정보만 저장하기에 그래프의 간선의 개수와 리스트의 원소의 개수가 같음
⇒ 간선의 개수에 비례하는 메모리만 차지
-
각 노드마다 연결된 노드만 확인하는 것 가능
단점
- 모든 노드를 방문해야 하는 경우 리스트의 간선을 확인해봐야 하기에 시간복잡도가 높음
🔠 DFS 개념
- 스택 혹은 재귀를 통해서 구현 가능
재귀함수를 활용
- 시작 정점을 인자로 받는 DFS 함수 정의
- 현재 정점을 방문 처리
- 현재 정점과 연결된 인접 정점들을 확인
- 인접 정점 중 방문하지 않은 정점을 재귀적으로 DFS에 호출
📍 DFS를 활용해야 하는 경우
- 경로의 특징을 저장해 둬야 하는 문제
- 검색 대상 그래프가 큰 경우(노드와 간선이 많은 경우)
⌨️ 구현하기
스택을 활용한 DFS
const dfs = (graph, start, visited) => {
const stack = [];
stack.push(start);
while (stack.length) {
let v = stack.pop();
if (!visited[v]) {
console.log(v);
visited[v] = true;
for (let node of graph[v]) {
if (!visited[node]) stack.push(node);
}
}
}
}
const graph = [[1, 2, 4], [0, 5], [0, 5], [4], [0, 3], [1, 2]];
const visited = Array(7).fill(false);
dfs(graph, 0, visited);
// 0 4 3 2 5 1재귀를 활용한 DFS
const dfs = (graph, v, visited) => {
// 현재 노드를 방문 처리
visited[v] = true;
console.log(v);
// 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for (let node of graph[v]) {
if (!visited[node]) dfs(graph, node, visited);
}
}
const graph = [[1, 2, 4], [0, 5], [0, 5], [4], [0, 3], [1, 2]];
const visited = Array(7).fill(false);
dfs(graph, 0, visited);
// 0 1 5 2 4 3
🔠 BFS 개념
- 출발점을 먼저 큐에 넣고, 큐가 빌 때까지 아래 과정을 반복
- 탐색 스택, 방문 배열을 생성
- 탐색을 시작하는 정점을 탐색 스택에 쌓음
- 탐색 스택의 length가 0이 아닐 때까지 아래 과정 반복
- 스택 최상단에 있는 것을 없애고, 이를 탐색
- 탐색 시에 방문했는지 체크, 했다면 패스
- 방문 안했다면 이를 방문 배열에 넣고 그 정점과 이어진 정점들을 다시 배열에 쌓음
📍 BFS를 활용해야 하는 경우
- 최단거리 문제
⌨️ 구현하기
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"]
};
// graph 자료구조와 startNode를 입력
const BFS = (graph, startNode) => {
let visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) { // 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // 가장 오래 남아있던 정점을 뽑아냄.
if (!visited.includes(node)) { // 해당 노드 방문이 처음이라면,
visited.push(node);
needVisit = [...needVisit, ...graph[node]];
}
}
return visited;
};
console.log(BFS(graph, "A"));
// ["A", "B", "C", "D", "G", "H", "I", "E", "F", "J"]⏱️ 시간복잡도
- 인접 행렬: O(1)
- 인접 리스트: O(M) (M은 간선의 개수)
- DFS, BFS: O(n) (노드 수 + 간선 수)
📍 문제에서 노드의 개수가 1000개 미만일 때는 인접 행렬 사용
📍 참고

세상은 호락호락하지 않다. 괜찮다. 나도 호락호락하지 않으니까.