이전 내용에 이어 이번에는 실제 파이썬 코드를 통해 카프카를 실행해보자.
이번에는 로컬에서 파이썬 코드로 테이블에 데이터를 insert한다.
1. 파이썬-카프카 라이브러리 설치
먼저, 파이썬에서 카프카를 사용하기 위해 라이브러리를 설치한다.
pip install kafka-python2. producer 생성
토픽으로 데이터를 전송할 프로듀서를 생성한다.
여기서는 new-topic.txt 파일의 값을 보내는 방식으로 적용한다.
(참고: 나는 카프카 테스트를 프로젝트 루트의 test 폴더에서 작업하였다.)
👀 브로커를 'localhost:9092'라고 세팅해주었으니, 당연히 로컬에서 zookeeper와 kafka를 실행한 상태에서 진행한다.
로컬에서 zookeeper와 kafka 실행하는 방법은 이전 게시글을 참고한다.
# 전송할 데이터 파일
# test/new-topic.txt
-----start-----
1
2
3
..
..
9998
9999
10000
-----end-----# test/producer.py
from kafka import KafkaProducer
import json
import time
from csv import reader
class MessageProducer:
broker = ""
topic = ""
producer = None
def __init__(self, broker, topic):
self.broker = broker
self.topic = topic
self.producer = KafkaProducer(bootstrap_servers=self.broker,
value_serializer=lambda x: json.dumps(x).encode('utf-8'),
acks=0,
api_version=(2,5,0),
retries=3
)
def send_message(self, msg):
try:
future = self.producer.send(self.topic, msg)
self.producer.flush() # 비우는 작업
future.get(timeout=60)
return {'status_code': 200, 'error': None}
except Exception as e:
print("error:::::",e)
return e
# 브로커와 토픽명을 지정한다.
broker = 'localhost:9092'
topic = 'new-topic'
message_producer = MessageProducer(broker, topic)
with open('test/'+topic+'.txt', 'r', encoding='utf-8') as file:
for data in file:
print("send-data: ", data)
res = message_producer.send_message(data)
3. consumer 생성, 가져온 데이터 처리(테이블 insert)
토픽으로부터 데이터를 가져올 컨슈머를 생성하고, 컨슈머에서 데이터 처리를 한다.
수집한 데이터는 TblKafkaTest 테이블에 row 단위로 insert 한다.
테이블은 임시로 다음과 같이 생성하였다.
# test/models.py
from django.db import models
class TblKafkaTest(models.Model):
idx = models.BigAutoField(primary_key=True)
name = models.CharField(max_length=50, blank=True, null=True)
col_a = models.CharField(max_length=50, blank=True, null=True)
col_b = models.CharField(max_length=50, blank=True, null=True)
col_c = models.CharField(max_length=50, blank=True, null=True)
col_d = models.CharField(max_length=50, blank=True, null=True)
create_date = models.DateTimeField()
class Meta:
managed = False
db_table = "tbl_kafka_test"# test/consumer.py
from kafka import KafkaConsumer
import time
import json
import datetime
from models import *
class MessageConsumer:
broker = ""
topic = ""
group_id = ""
logger = None
def __init__(self, broker, topic, group_id):
self.broker = broker
self.topic = topic
self.group_id = group_id
def activate_listener(self):
# 처리 시간 등의 결과 확인을 위해 kafka_output.txt 파일에 값을 이어 출력한다.
sys.stdout = open('kafka_output.txt','a', encoding='utf-8')
consumer = KafkaConsumer(
bootstrap_servers=self.broker,
group_id=self.group_id,
consumer_timeout_ms=2000,
auto_offset_reset='latest',
enable_auto_commit=False,
value_deserializer=lambda m: json.loads(m.decode('ascii'))
)
consumer.subscribe(self.topic)
tot_start = time.time()
start = time.time()
i = 0
try:
with open(self.topic+'.txt', 'a', encoding='utf-8') as file:
for message in consumer:
message = message.value
file.write(str(message))
i = i + 1
data = {
'name': topic,
'col_a': i,
'col_b': message,
'create_date': datetime.datetime.now()
}
TblKafkaTest.objects.create(**data)
consumer.commit()
tot_end = time.time()
tot_elapsed = tot_end - tot_start
per_time_value = i / tot_elapsed
print("=====================================================")
print("총 처리 시간: ", tot_elapsed)
print("총 처리 건수: ", i)
print("초당 처리 건수: ", per_time_value)
except KeyboardInterrupt:
print("Aborted by user...")
broker = 'localhost:9092'
topic = 'new-topic'
group_id = 'consumer-1'
consumer1 = MessageConsumer(broker, topic, group_id)
consumer1.activate_listener()
consumer2 = MessageConsumer(broker, topic, group_id)
consumer2.activate_listener()4. 실행 및 결과 확인
파이썬 인터프리터에서 producer.py 파일을 실행하였다.
전송 데이터 확인을 위해 print문을 넣었고, 터미널에 다음과 같이 출력되었다.
new-topic.txt 파일에 1~10,000까지의 값이 순차적으로 모두 전송되었음을 확인할 수 있다.
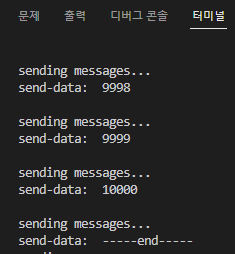
데이터 전송은 완료되었으니, 컨슈머에서 확인을 해보자.
이번에는 consumer.py 를 실행하였고, kafka_output.txt 에서 출력 결과를 확인하였다.
# test/kafka_output.txt
=====================================================
총 처리 시간: 10.073350191116333
총 처리 건수: 20003
초당 처리 건수: 1985.7345987674096
=====================================================
총 처리 시간: 9.726698160171509
총 처리 건수: 0
초당 처리 건수: 0.0
✍ 나는 컨슈머를 2개로 설정해서 2번의 출력 결과를 얻었다.
그리고 consumer1 이 문제 없이 데이터를 모두 수집하였기 때문에, consumer2가 이어 받아 할 작업은 따로 없어 consumer2의 처리 건수는 0이 된다.
결과를 확인해보니 총 약 20,000 건의 데이터가 10초동안 처리되었다.
평균적으로 초당 1,985개의 데이터가 처리된 것이다. 엄청난 속도인 것 같다. 😱
테이블에 insert도 잘 되었을까? 🤔
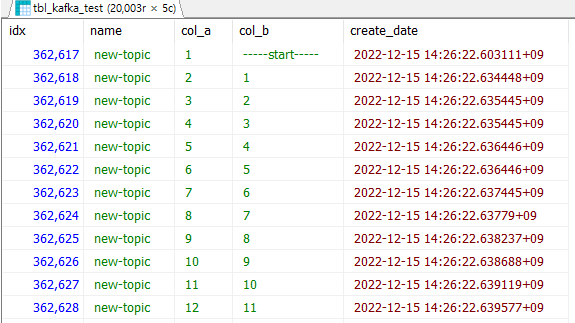 역시 20,003개의 row 모두 잘 저장되었음을 확인할 수 있다.
역시 20,003개의 row 모두 잘 저장되었음을 확인할 수 있다.
추가적으로
나는 컨슈머 그룹을 설정하고 동일한 그룹ID로 consumer1 , consumer2를 생성하였다.
이렇게 하면 consumer1이 작업을 진행하다가 중단되어도 consumer2가 이어 받아 작업할 수 있게 된다.
단, 여기서 컨슈머 옵션은 auto_offset_reset='latest' 이어야 한다.
기타 컨슈머의 옵션은 잘 정리된 링크가 있어 첨부한다.
컨슈머 옵션 관련 링크
데이터 가져와 테이블에 저장하기 실습으로 간단하게 확인해보았지만, 실제로 수만 개의 데이터 처리를 할 때에는 매우 효과적이고 빠를 것 같다는 생각이 들었다.
