
메모리 / 디스크 비교
| 메모리 | 디스크 | |
|---|---|---|
| 속도 | 빠름 | 느림 |
| 영속성 | 전원이 공급되지 않으면 휘발 | 영속성이 있음 |
| 가격 | 비쌈 | 저렴함 |
데이터베이스의 데이터는 결국 디스크에 저장이 되어야한다. 하지만 디스크는 메모리에 비해 훨씬 느리다.
=> 결국 데이터베이스 성능의 핵심은 디스크 I/O(접근)을 최소화 하는 것이다.
디스크 접근 줄이는 방법
- 메모리에 올라온 데이터로 최대한 요청을 처리하는 것
=> 메모리 캐시 히트율을 높이는 것- 디스크에 바로 쓰지 않고 메모리에 쓰는 경우도 있다.
- 디스크에 접근하는 방법
- 랜덤 I/O: 무작위하게 데이터를 읽어온다.
- 순차 I/O: 연속된 블록의 데이터들을 한번에 읽어온다.
- 대부분의 트랜잭션은 무작위하게 Write가 발생한다. 랜덤 I/O 횟수를 줄이는 대신 순차적I/O를 발생시켜 정합성을 유지한다.
- 메모리의 데이터 유실을 고려해 WAL(Write Ahead Log)를 사용한다. 삽입하는 쿼리문을 로그에 남겼다가 서버가 다시 살았을때 순차적으로 실행을 하여 정합성을 유지할 수 있다.
인덱스
인덱스는 정렬된 자료구조로 이를 통해 탐색범위를 최소화한다. 인덱스도 데이터의 주소값을 가진 테이블이다.
인덱스의 자료구조
Hash Map
- 단건 검색 속도 O(1)
- 범위 탐색 속도 O(N)
- 전방 일치 탐색 불가 ex)LIKE 'AB%'
List
- 정렬되지 않은 리스트의 탐색은 O(N)
- 정렬된 리스트의 탐색은 O(logN)
- 정렬되지 않은 리스트의 정렬 시간 복잡도는 O(N) ~ O(N*logN)
- 삽입 / 삭제 비용이 매우 높음
Tree
- 트리 높이에 따라 복잡도가 결정됨
- 트리의 높이를 최소화하는 것이 중요!
- 한쪽으로 노드가 치우치지 않도록 균형을 잡아주는 트리 사용
ex) Red-Black Tree, B+Tree
B+Tree
- 삽입 / 삭제 시 항상 균형을 이룸
- 하나의 노드가 여러 개의 자식 노드를 가질 수 있음
- 리프노드에만 데이터 존재 => 연속적인 데이터 접근 시 유리
- B+Tree 동작
클러스터 인덱스
- 클러스터 인덱스는 데이터의 위치를 결정하는 키값이다.
- 클러스터 키는 정렬된 자료구조이고 클러스터 키 순서에 따라 데이터의 위치가 결정된다.
=> 클러스터 키 삽입 / 갱신 시 에 성능이슈 발생
- 클러스터 키는 정렬된 자료구조이고 클러스터 키 순서에 따라 데이터의 위치가 결정된다.
- MySQL의 PK는 클러스터 인덱스이다.
- PK 순서에 따라서 데이터 저장 위치가 변경된다.
=> PK 키 삽입 / 갱신 시에 성능이슈 발생 - PK로 Auto Increment vs UUID
이에 대한 이슈 찾아보기!
- PK 순서에 따라서 데이터 저장 위치가 변경된다.
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가진다.
장점
- PK를 활용한 검색이 빠름. 특히 범위 탐색에서 빠름
- 세컨더리 인덱스들이 PK를 가지고 있어 커버링(데이터 테이블까지 가지 않음)에 유리
실습
벌크인서트를 구현하기 실제로 300만건의 데이터가 있을 경우 SELECT 쿼리의 성능에 대해서 보자.
3번의 유저로 100만건, 4번 유저로 200만건의 데이터를 넣어주었다.
현재 프로젝트의 작성일자별 포스트의 갯수를 세는 쿼리를 날려보자.
SELECT DATE_FORMAT(createdAt,'%Y-%m-%d') createdDate, memberId, count(id) as count
FROM POST
WHERE memberId = 4 and createdAt between '2000-01-01' and '2023-05-01'
GROUP BY memberId, createdDate;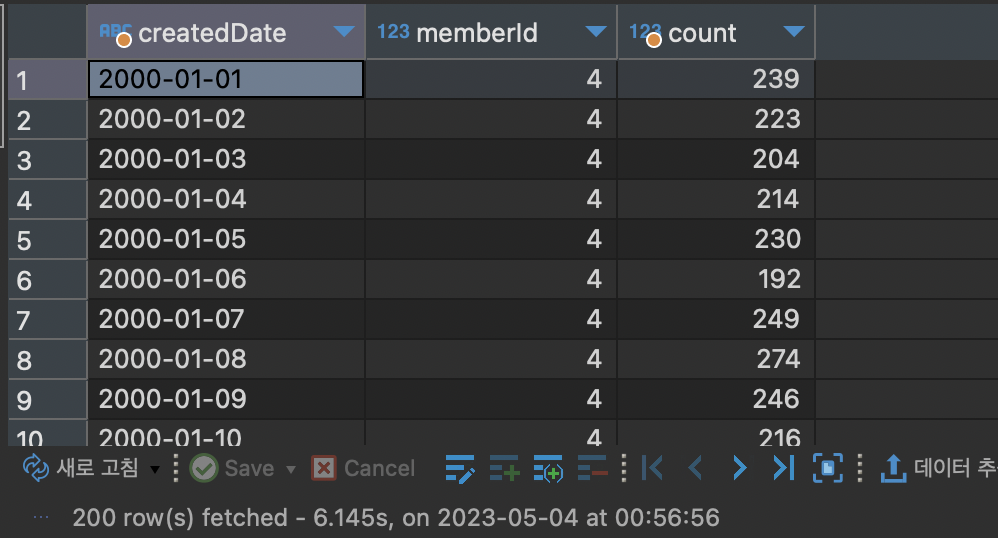
하단을 보면 6.145s가 걸렸다고 한다...마ㅓㅗ윰에매ㅓ야미
EXPLAIN 사용하기
EXPLAIN SELECT DATE_FORMAT(createdAt,'%Y-%m-%d') createdDate, memberId, count(id) as count
FROM POST
WHERE memberId = 4 and createdAt between '2000-01-01' and '2023-05-01'
GROUP BY memberId, createdDate;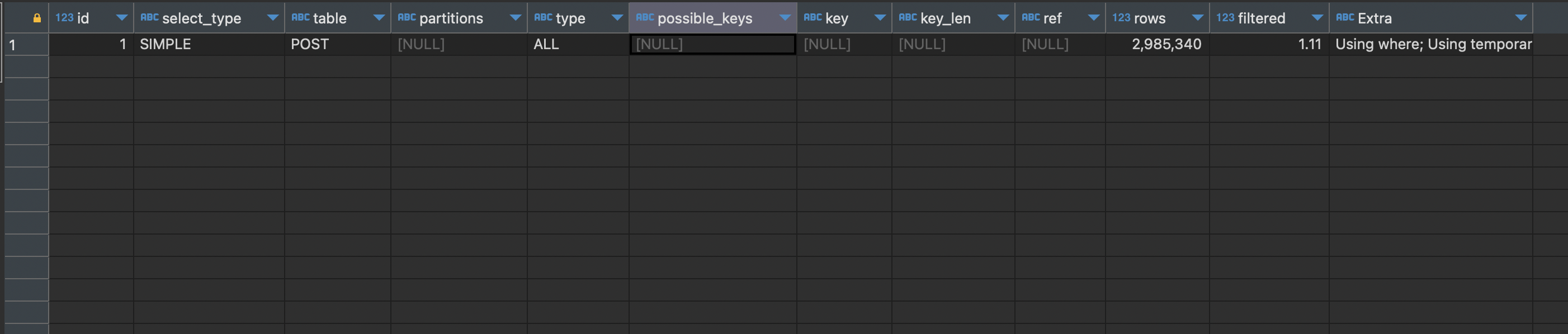
다른 부분은 나중에 다시 알아보기로 하고 일단 필요한 부분만 알아보자.
type은 테이블의 모든 데이터를 스캔 했다는 뜻이다. 디스크에 접근해서 데이터를 탐색했다.
rows는 몇건의 데이터를 스캔했는지를 나타낸다.
현재는 rows가 2985340의 건수를 스캔했는데 실제 데이터를 보면 4번 유저가 등록한 게시글은 200만건으로 넣어줬다. 굉장히 비효율적인것 같다는 생각이 마구 든다.
이제부터 인덱스를 걸어서 쿼리의 속도를 향상 시켜보자.
create index POST__index_member_id
on POST (memberId);
create index POST__index_created_at
on POST (createdAt);
// 복합인덱스
create index POST__index_member_id_created_at
on POST (memberId, createdAt);세개의 인덱스를 생성 후 하나씩 인덱스를 사용한 쿼리를 비교해보자.
memberId index
SELECT DATE_FORMAT(createdAt,'%Y-%m-%d') createdDate, memberId, count(id) as count
FROM POST use index (POST__index_member_id)
WHERE memberId = 4 and createdAt between '2000-01-01' and '2023-05-01'
GROUP BY memberId, createdDate;use index (POST__index_member_id)와 같이 인덱스를 강제 지정 할 수 있다.

결과는 ... 8초대로 더 늦어졌다...ㅠ

실행계획을 확인해보자.
type이 ref로 바뀌었다. ref는 인덱스를 타고 검색을 한 경우를 의미하며 possible_keys, key 가 사용
인덱스가 없었을때는 테이블을 쭈욱 스캔했는데
인덱스를 사용하면서 인덱스 테이블도 보고 물리 테이블도 봐야하면서 쿼리가 늦어진것이다.
memberId를 인덱스 키로 줬지만 4번에 해당하는 건수가 200만건이라 모두 확인 후 물리테이블도 보는 것이다.
방금의 쿼리를 memberId를 1로 준다면 엄청 빠르게 결과를 내려주는 것을 볼 수 있다.
1번에 인덱스 테이블에 아무것도 없다는 것을 확인했기 때문이다.
이와 같이 데이터 분포에 따라 같은 쿼리문이 성능이 달라질 수 있다.
복합 index
SELECT DATE_FORMAT(createdAt,'%Y-%m-%d') createdDate, memberId, count(id) as count
FROM POST use index (POST__index_member_id_created_at)
WHERE memberId = 4 and createdAt between '2000-01-01' and '2023-05-01'
GROUP BY memberId, createdDate;
이는 memberId가 1번이 와도 인덱스를 타고 빠르게 데이터를 검색할 수 있다.
groupby도 인덱스를 탈 수 있게 된다.
인덱스를 사용할 시 주의점
카디널리티가 높은 필드를 인덱스로 지정
카디널리티가 높다 = 중복될 가능성이 낮다.
예를 들어 주민등록번호는 유일한 값으로 중복되지 않는다. 이는 카디널리티가 높은 경우이다.
또한 남여의 경우 중복될 가능성이 높으므로 카디널리티가 낮은 경우이다.
그래서 MySQL이 PK(not null, 유일한 값, 중복X)를 인덱스로 기본으로 가진다.
인덱스 필드 가공
age가 인덱스로 지정되어있다고 해도 다음의 예시에서는 사용할 수 없다.
ex_1) 인덱스 키값을 연산하는 경우
// age는 int 타입
SELECT *
FROM member
WHERE age * 10 = 1;ex_2) 타입을 잘못 넣은 경우
// age는 int 타입
SELECT *
FROM member
WHERE age = '1';복합 인덱스
복합 인덱스를 줄 때 지정한 순서로 인덱스 정렬을 한다.
- 성적, 클래스로 인덱스를 준 경우
| 성적 | 클래스 | PK |
|---|---|---|
| A | ACE | 1 |
| B | NOMAL | 4 |
| B | ACE | 6 |
| C | NOMAL | 2 |
| D | ACE | 3 |
성적, 또는 성적, 클래스로는 인덱스를 탈 수 있지만 클래스로는 인덱스를 타기 어렵다.
하나의 쿼리에는 하나의 인덱스만
여러 인덱스 테이블을 동시에 탐색하지 않는다.
WHERE, ORDER BY, GROUP BY 혼합해서 사용할 때는 인덱스를 잘 고려해야한다.
그외
- 의도대로 인덱스가 동작하지 않을 수 있다.
- 인덱스는 쓰기를 희생하고 조회를 얻는 것이다.
- 인덱스가 아니라 다른 방법으로 해결할 수 있는 경우가 있을 것이다.
음 지금 생각나는 것은 년월일의 날짜값만 가지만 컬럼을 만들면 DATE_FORMAT(createdAt,'%Y-%m-%d') 이부분이 빠져서 더 보기 좋고 성능이 나올 것 같다.
마무리
예전에도 인덱스를 한번 공부한적있는데 그때도 인덱스를 사용하면 빠르다로 시작해서 결국에는 계속 어떤 경우는 느리다의 연속이었던 기억이 난다.
역시 뭐든 쓰기 나름인것 같다.
많은 테스트와 경험으로 어떤 때에 사용하는 것이 좋은 지 왜 좋은지를 파악할 수 있게 되는 것이 중요하다고 생각한다.
