
페이지네이션
컨텐츠를 여러개로 나누어 보여주는 사용자 인터페이스
클라이언트로부터 페이지, 사이즈, 정렬조건을 받아 어디서부터 몇개의 데이터를 내려줄지가 결정되도록 구현한다.
오프셋 기반 페이징 구현의 문제
- 마지막 페이지를 구하기 위해 전체 갯수를 알아야한다.
- LIMIT, OFFSET을 통해 데이터를 가져오면 불필요한 데이터 조회가 발생한다.
- ex) 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 와 같이 데이터가 있고
- LIMIT 5, OFFSET 4라고 한다면
- 0부터 3까지 데이터를 먼저 읽고 4번 부터 5개의 데이터를 반환하는데
- 이때와 같이 0 - 3까지 불필요한 데이터를 조회한다. 데이터가 많아질수록 부하 가능성이 높음
- 페이징을 하는 도중 새로운 데이터가 추가되면 다음 페이지에서 이전에 조회한 데이터를 중복으로 조회하는 경우가 있다.
MySQL의 LIMIT, OFFSET 을 통해 구현하며 필요한 데이터는 현재 페이지 번호, 각 페이지에 보이는 컨텐츠의 수, 컨텐츠 내용, 전체 컨텐츠의 수, 전체 페이지의 수 가 필요하다.
repository
public Page<Post> findAllByMemberId(Long memberId, Pageable pageable) {
var params = new MapSqlParameterSource()
.addValue("memberId", memberId)
.addValue("size", pageable.getPageSize())
.addValue("offset", pageable.getOffset());
var sql = String.format("""
SELECT *
FROM %s
WHERE memberId = :memberId
ORDER BY %s
LIMIT :size
OFFSET :offset;
""", TABLE, PageHelper.orderBy(pageable.getSort()));
var posts = namedParameterJdbcTemplate.query(sql, params, ROW_MAPPER);
return new PageImpl<>(posts, pageable, getCount(memberId));
}
private Long getCount(Long memberId) {
var sql = String.format("""
SELECT count(*)
FROM %s
WHERE memberId = :memberId
""", TABLE);
var params = new MapSqlParameterSource().addValue("memberId", memberId);
return namedParameterJdbcTemplate.queryForObject(sql, params, Long.class);
}service
public Page<Post> getPosts(Long memberId, Pageable pageable) {
return postRepository.findAllByMemberId(memberId, pageable);
}
}controller
@GetMapping("/members/{memberId}")
public Page<Post> getPosts(
@PathVariable Long memberId,
Pageable pageable
) {
return postReadService.getPosts(memberId, pageable);
}정렬추가
MySQL은 정렬 조건이 없으면 기본으로 id값을 정렬조건으로 갖는다.
클라이언트에서 받은 정렬조건에 대한 parameter를 PageHelper가 정렬조건을 sql 문에 넣어줄 수 있도록 Strig 객체를 반환한다.
package com.example.twittermysql.domain;
import java.util.List;
import org.springframework.data.domain.Sort;
public class PageHelper {
public static String orderBy(Sort sort) {
if (sort.isEmpty()) {
return "id DESC";
}
List<Sort.Order> orders = sort.toList();
var orderBys = sort.stream()
.map(order -> order.getProperty() + " " + order.getDirection())
.toList();
return String.join(", ", orderBys);
}
}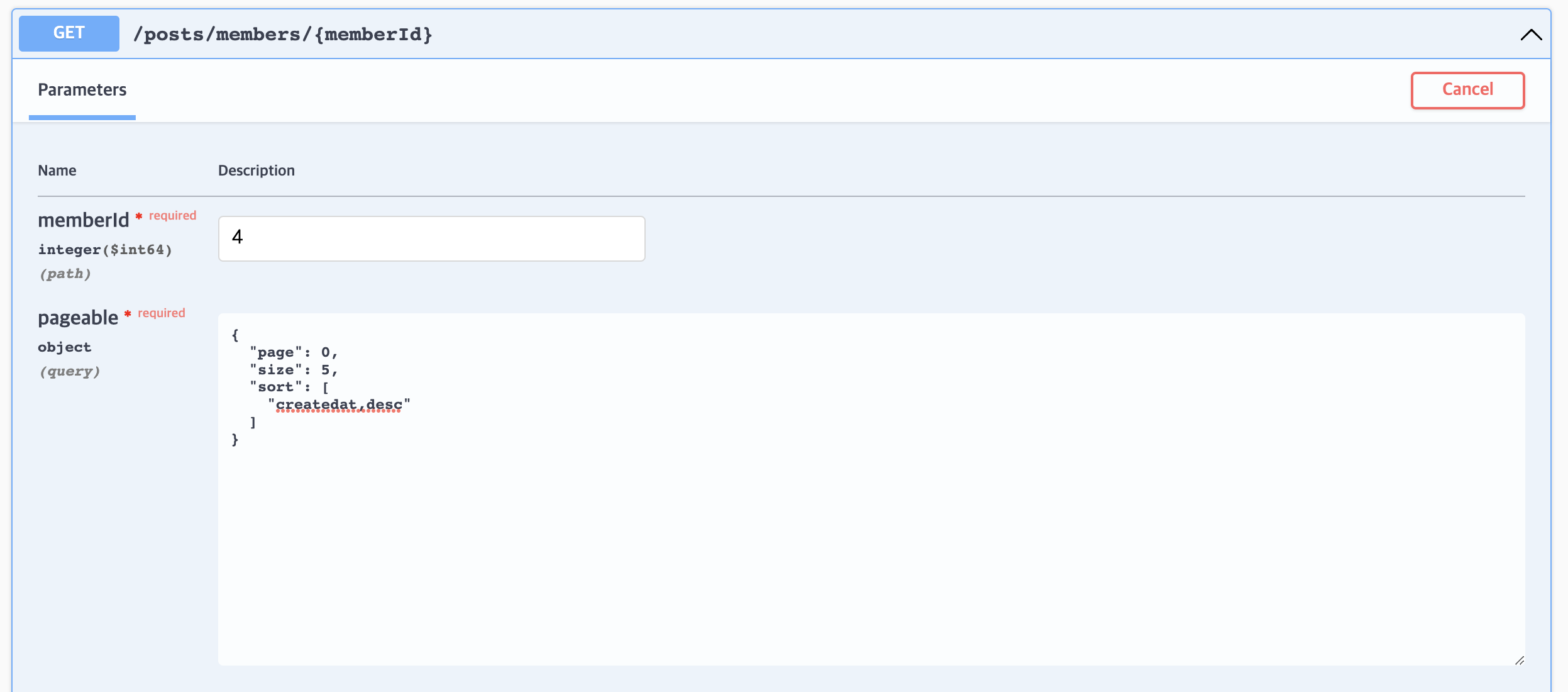
{
"content": [
{
"id": 2599774,
"memberId": 4,
"contents": "ZQjBPFPjIhzB",
"createdAt": "2023-02-01T23:51:54"
},
{
"id": 1599418,
"memberId": 4,
"contents": "XZkPDzvQJFUF",
"createdAt": "2023-02-01T23:51:54"
},
{
"id": 3846538,
"memberId": 4,
"contents": "pZHTLPDjeEexYJOtdzluTJwOAX",
"createdAt": "2023-02-01T23:48:53"
},
{
"id": 2971978,
"memberId": 4,
"contents": "DlXGnivdfC",
"createdAt": "2023-02-01T23:48:53"
},
{
"id": 1097500,
"memberId": 4,
"contents": "FeVRBRSnGzjIsegupE",
"createdAt": "2023-02-01T23:48:53"
}
],
"pageable": {
"sort": {
"empty": false,
"unsorted": false,
"sorted": true
},
"offset": 0,
"pageNumber": 0,
"pageSize": 5,
"paged": true,
"unpaged": false
},
"last": false,
"totalPages": 600000,
"totalElements": 3000000,
"first": true,
"size": 5,
"number": 0,
"sort": {
"empty": false,
"unsorted": false,
"sorted": true
},
"numberOfElements": 5,
"empty": false
}커서 기반 페이징
커서 기반 페이징은 key와 size를 클라이언트를 통해서 받고 데이터를 반환할때 마지막 키 번호를 줘서 다음 페이징을 조회할때 사용된다. 때문에 데이터 탐색 범위를 최소화할 수 있다.
ex) key 3, size 5 -> key 8 => 다음 조회 시 key 8, size 5 -> key 13 ...
키값은 유니크한 값이여야 한다.
마지막 키값을 내려주고 그 키값을 다음에서 사용하기 때문에 최신순의 경우 새로운 데이터 추가 되었을 시 중복으로 조회되지 않는다.
repository
// 키값이 없을 경우
public List<Post> findAllByMemberIdAndOrderByDesc(Long memberId, int size) {
var sql = String.format("""
SELECT *
FROM %s
WHERE memberId = :memberId
ORDER BY id DESC
LIMIT :size
""", TABLE);
var params = new MapSqlParameterSource()
.addValue("memberId", memberId)
.addValue("size", size);
return namedParameterJdbcTemplate.query(sql, params, ROW_MAPPER);
}
// 키값이 있을 경우
public List<Post> findAllByLessThanIdMemberIdAndOrderByIdDesc(Long id, Long memberId,
int size) {
var sql = String.format("""
SELECT *
FROM %s
WHERE memberId = :memberId AND id < :id
ORDER BY id DESC
LIMIT :size
""", TABLE);
var params = new MapSqlParameterSource()
.addValue("memberId", memberId)
.addValue("id", id)
.addValue("size", size);
return namedParameterJdbcTemplate.query(sql, params, ROW_MAPPER);
}service
public PageCursor<Post> getPosts(Long memberId, CursorRequest cursorRequest) {
var posts = findAllBy(memberId, cursorRequest);
var nextKey = posts.stream()
.mapToLong(Post::getId)
.min()
.orElse(CursorRequest.NONE_KEY);
return new PageCursor<>(cursorRequest.next(nextKey), posts);
}
public List<Post> findAllBy(Long memberId, CursorRequest cursorRequest) {
if (cursorRequest.hasKey()) {
return postRepository.findAllByLessThanIdMemberIdAndOrderByIdDesc(
cursorRequest.key(), memberId, cursorRequest.size());
}
return postRepository.findAllByMemberIdAndOrderByDesc(memberId, cursorRequest.size());
}controller
@GetMapping("/members/{memberId}/by-cursor")
public PageCursor<Post> getPostsByCursor(
@PathVariable Long memberId,
CursorRequest cursorRequest
) {
return postReadService.getPosts(memberId, cursorRequest);
}PageCursor record
package com.example.twittermysql.util;
import java.util.List;
public record PageCursor<T>(
CursorRequest nextCursorRequest,
List<T> body
) {
}CursorRequest record
package com.example.twittermysql.util;
public record CursorRequest(Long key, int size) {
public static final Long NONE_KEY = 1L;
public Boolean hasKey() {
return key != null;
}
public CursorRequest next(Long key) {
return new CursorRequest(key, size);
}
}키 값이 없으면 id DESC 조회
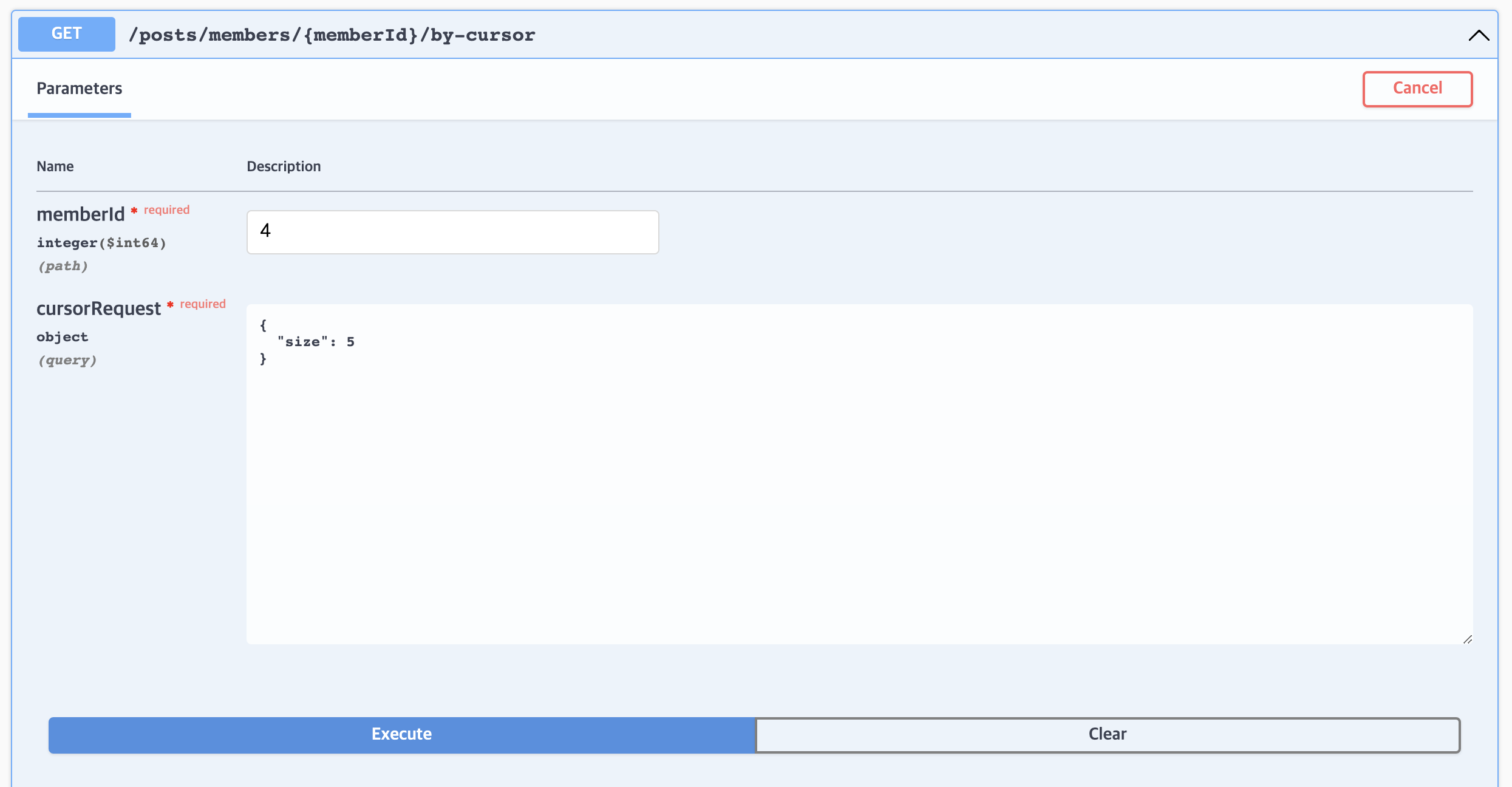
{
"nextCursorRequest": {
"key": 1999998, // 다음 키값
"size": 3
},
"body": [
{
"id": 2000000,
"memberId": 4,
"contents": "VsvjbWTTTGhAnF",
"createdDate": "2010-03-19",
"createdAt": "2000-12-22T09:21:57"
},
{
"id": 1999999,
"memberId": 4,
"contents": "YaRWWGVrWVvdoGPdyPH",
"createdDate": "2020-05-19",
"createdAt": "2010-05-03T18:45:31"
},
{
"id": 1999998,
"memberId": 4,
"contents": "xqQZnfGgpRFxV",
"createdDate": "2020-06-22",
"createdAt": "2000-11-03T15:09:43"
}
]
}위에서 준 키값 1999998로 조회 시
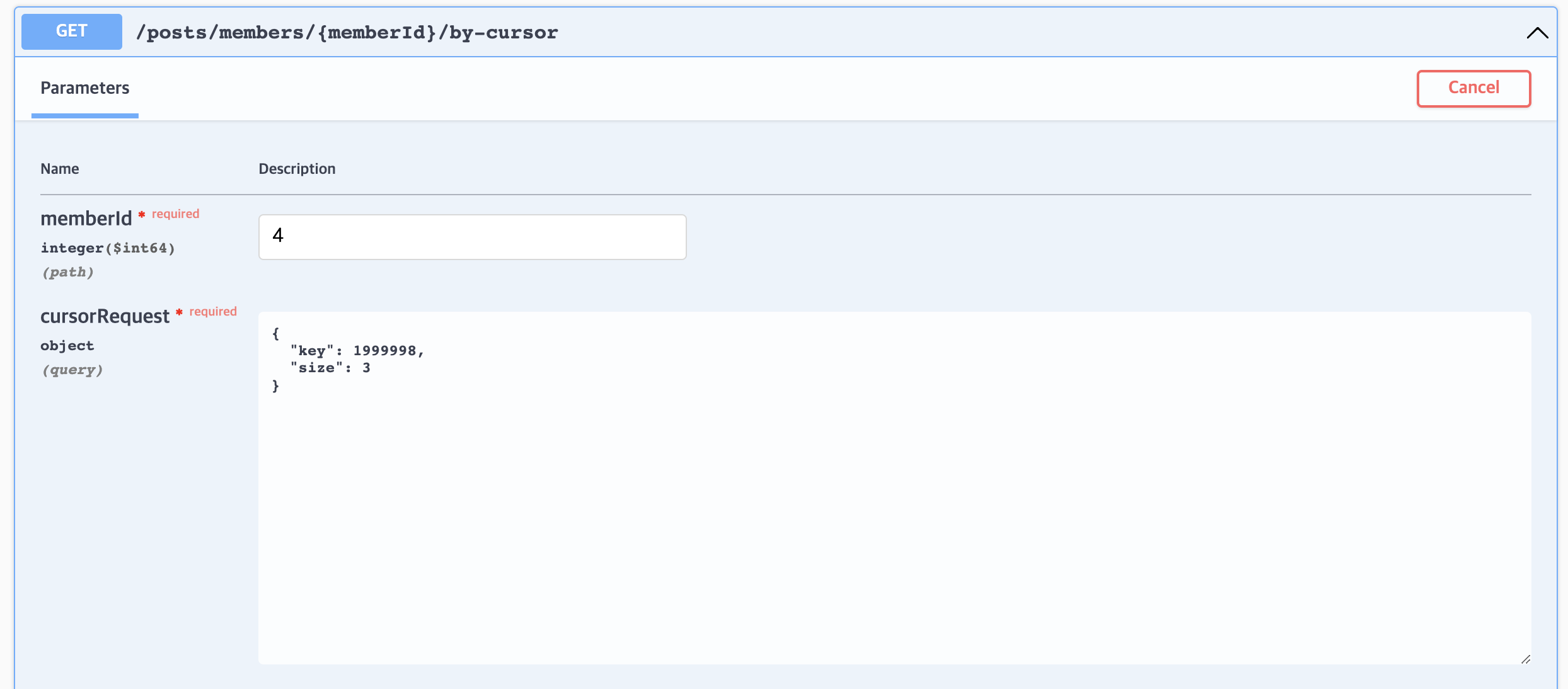
{
"nextCursorRequest": {
"key": 1999995,
"size": 3
},
"body": [
{
"id": 1999997,
"memberId": 4,
"contents": "vAvGcAdZ",
"createdDate": "2018-01-29",
"createdAt": "2015-07-03T06:51:17"
},
{
"id": 1999996,
"memberId": 4,
"contents": "dViYYAnghgrvMmiVqqnFURookqzRsLL",
"createdDate": "2022-09-25",
"createdAt": "2006-06-09T10:23:27"
},
{
"id": 1999995,
"memberId": 4,
"contents": "RUhcKaceBcUyH",
"createdDate": "2020-01-18",
"createdAt": "2002-03-24T21:29:49"
}
]
}1999997부터 의도대로 조회된다.
커버링 인덱스
검색 조건이 인덱스에 부합한다면 테이블에 바로 접근하지 않고
인덱스로만 데이터 응답을 내려주는 방식
MySQL에서 PK가 클러스터 인덱스이기 때문에 커버링 인덱스에 유리하다.
이렇게 빠르게 내릴 수 있는 커버링 인덱스를 이용한 페이지네이션 방법을 알아보자.
만약에 연봉이 5000만원 이하인 직원을 50명의 이름을 찾는 조건이 있을 때
LIMIT 절을 사용하게 될것이다.
연봉에 인덱스가 걸려있다고 가정하고 5000만원 이하의 직원들이 500명이라면 500명의 직원에 대한 데이터블럭 엑세스가 모두 일어나게 된다.
디스크의 랜덤 I/O가 발생하게 되는데 이를 줄여주는 것만으로도 성능을 올려줄 수 있다.
with 커버링 as (
SELECT id
FROM 사원
WHERE 연봉 <= 5000
LIMIT 50
)
// 연봉, id값은 인덱스만 타고 커버 가능
SELECT 이름
FROM 사원 INNER JOIN 커버링 ON 사원.id = 커버링.id위와 같은 사용으로 범위를 줄임으로써 불필요한 랜덤 접근을 줄일 수 있다.
order by, offset, limit 절로 인한 불필요한 데이터블록 접근을 커버링 인덱스를 통해 최소화한다.
