Algorithm
1.Day1_대소문자 바꿔서 출력

내 풀이다른사람 풀이int i를 이용해서 str 길이를 도는 것보다auto c를 만들어서 str을 돌도록 하는 것이 더 깔끔.'a'랑 'A'를 10진수로 변경해서 계산하는 것보다 그냥 ' '(작은 따옴표) 사이에 넣어서 계산하면 간단함.
2.Day1_특수문자 출력하기
내 풀이다른 사람 풀이리터럴 사용한 예시따옴표('',"") 앞에만 역슬래쉬를 추가로 붙여서 출력하면 됨
3.Day2_홀짝 구분
내 풀이다른 사람 풀이삼항연산자를 잘 활용하자!
4.Day2_문자열 겹쳐쓰기
내 풀이다른 사람 풀이replace() 함수를 잘 활용해보기!
5.Day3_더 크게 합치기
내 풀이다른 사람 풀이string -> int : stoi() 함수int -> string : to_string() 함수max(a, b)를 이용하는 방법!!
6.Day4_홀짝에 따라 다른 값 반환
내 풀이다른 사람 풀이삼항연산자 이용while문에서 반대로 숫자 줄어드는 생각 하기
7.주사위 게임2
내 풀이다른 사람 풀이math.h와 set을 사용해서a, b, c를 값으로 갖는 set을 만들어 활용.이진트리 이용숫자든 문자든 입력값의 중복을 없앤다.삽입 순서에 상관없이 정렬해서 입력된다.(예제)set<자료형> 변수 기본적인 선언방법 set<자료형>
8.주사위 게임3
다른 사람 풀이C++ 표준 라이브러리의 헤더 파일들을 포함합니다. string, vector, cmath, algorithm 헤더 파일을 사용합니다.표준 네임스페이스(std)를 사용합니다.함수 solution을 정의합니다. 이 함수는 네 개의 정수 a, b, c, d를
9.9로 나눈 나머지
char → intstring → int
10.문자열 뒤집기
내 풀이다른 사람 풀이뒤집는 건 reverse 함수 이용하기!reverse(first, last) : first포함 ~ last바로 전 지점 까지 뒤집음
11.배열 만들기 5
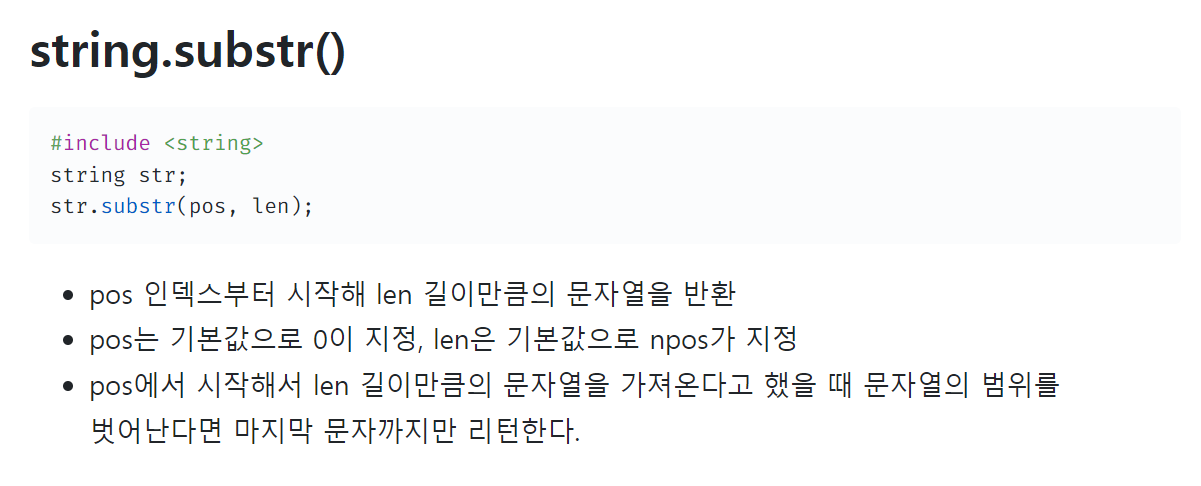
내 풀이다른 사람 풀이substr() 이라는 함수를 새롭게 알게 되었다. 굳이 배열 각 원소의 인덱스를 가져오지 않아도 간단히 풀 수 있었다.참고 블로그 https://velog.io/@doorbals_512/C-string.substr-%ED%95%A8%EC
12.접미사 배열
sort()함수로 오름차순 정렬이 가능하다.이 때, vector의 처음과 끝을 가져올 땐 인덱스로 가져오는 게 아니라begin(), end()로 사용하기
13.접미사인지 확인하기
내 풀이다른 사람 풀이굳이 길이를 계산할 필요없이, 어차피 해당 인덱스부터 끝까지 반환을 할거고my_string.size()에서 is_suffix.size()를 뺀 값을 인덱스로 가지면 결국is_suffix의 길이와 동일한 길이의 값이 나와서 굳이 반복문 쓸 필요없이
14.문자열 뒤집기
참고 블로그https://portable-paper.tistory.com/entry/%EB%AC%B8%EC%9E%90%EC%97%B4-%EB%92%A4%EC%A7%91%EA%B8%B0-C
15.세로 읽기
내 풀이=> string은 배열로 접근이 가능하다!!다른 사람 풀이c번째 열에서 m 간격 만큼의 문자들을 붙이는 걸로 생각해도 된다
16.문자 개수 세기
벡터를 초기화 할 땐, (길이, 이 값으로 초기화)문자열 아스키코드 값은 굳이 외우기보단 '문자' 이렇게 표현해도 (그래도 'A'=65, 'a'=97은 알아두기)참고 블로그 : https://googleyness.tistory.com/entry/C-STL-Ve
17.글자 지우기
내 풀이나는 아무 숫자나 공백을 덮어씌워서 그걸 나중에 빼고 넣는 방식으로 풀었지만다른 사람 풀이erase 함수를 이용해서 푸는 방법도 있다.
18.리스트 자르기
내 풀이다른 사람 풀이if문 대신 switch를 사용할 수 있다.for문 대신 vector의 기능을 활용하자 (begin(), end())
19.n번째 원소부터
내 풀이다른 사람 풀이answer에 부분을 잘라서 넣는 방식은 같지만, assign이라는 함수가 있다는 걸 알아두기!assgin(시작 위치, 끝 위치)참고 블로그 : https://boycoding.tistory.com/229
20.push_back과 emplace_back 차이점
push_back과 emplace_back은 C++의 std::vector, std::deque, std::list와 같은 컨테이너에서 요소를 추가할 때 사용하는 메서드이다. 두 메서드는 비슷한 역할을 하지만, 작동 방식에 차이가 있다.역할: push_back은 컨테이
21.원하는 문자열 찾기

내 풀이다른 사람 풀이first부터 end까지 범위 내에서, d_first부터의 값을 op함수를 적용한 값으로 변경transform(pat.begin(),pat.end(),pat.begin(),::toupper);이는 pat의 처음부터 끝까지 범위내에서, pat의 처음
22.특정 문자열로 끝나는 가장 긴 부분 문자열
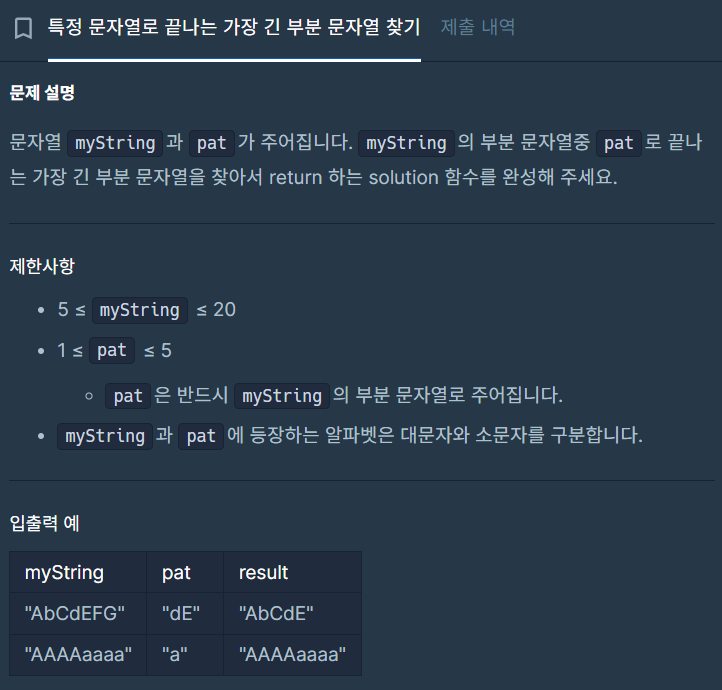
내 풀이나는 pat의 마지막 문자를 myString을 거꾸로 탐색해서 인덱스 값을 알아낸 다음, 0부터 그 인덱스까지의 값을 answer에 더했는데, 좀 복잡해서 다른 사람 풀이를 더 찾아봤다.다른 사람 풀이substr을 활용할 수 있다는 사실을 간과했다.그리고, 새롭
23.공백으로 구분하기 2
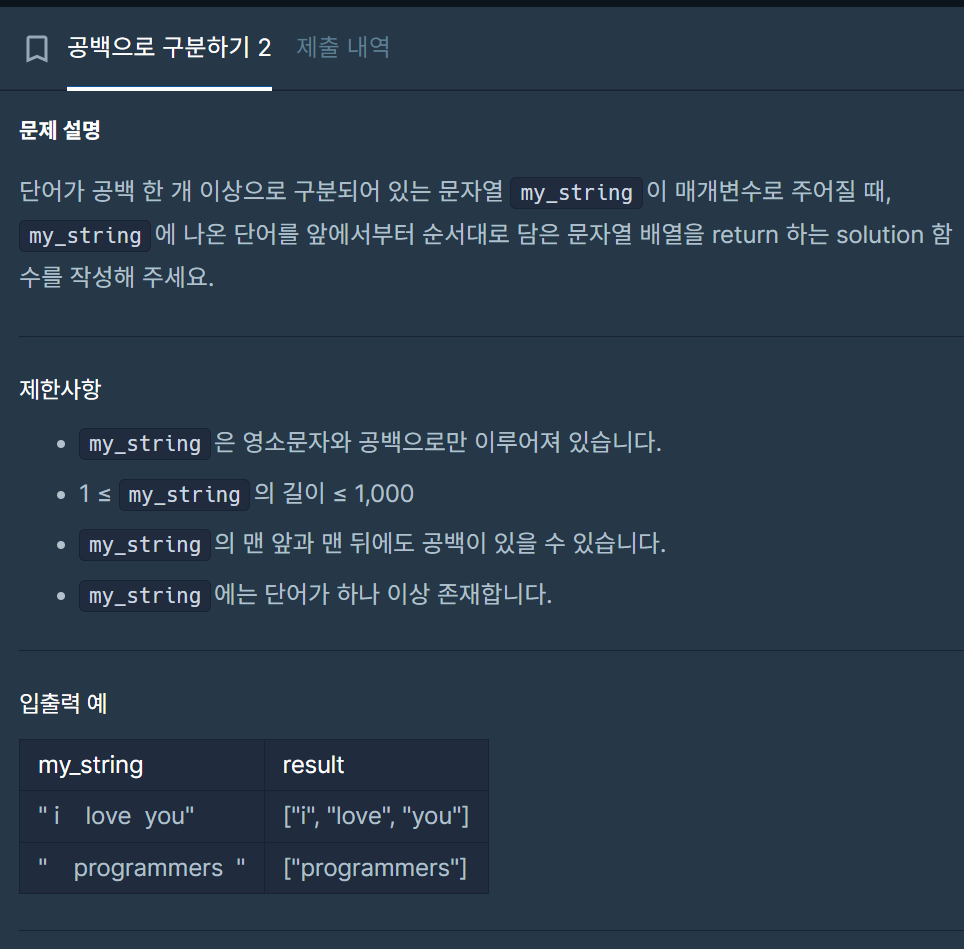
문자열 변수, 나중에 stringstream으로부터 단어를 하나씩 받아서 저장하는 데 사용됨stringstream 객체 ss를 선언, 문자열을 단어로 분리하기 위해 사용됨ss에 my_string을 초기화. ss는 my_string의 내용을 담고 있으며, 이 내용을
24.문자열 잘라서 정렬하기
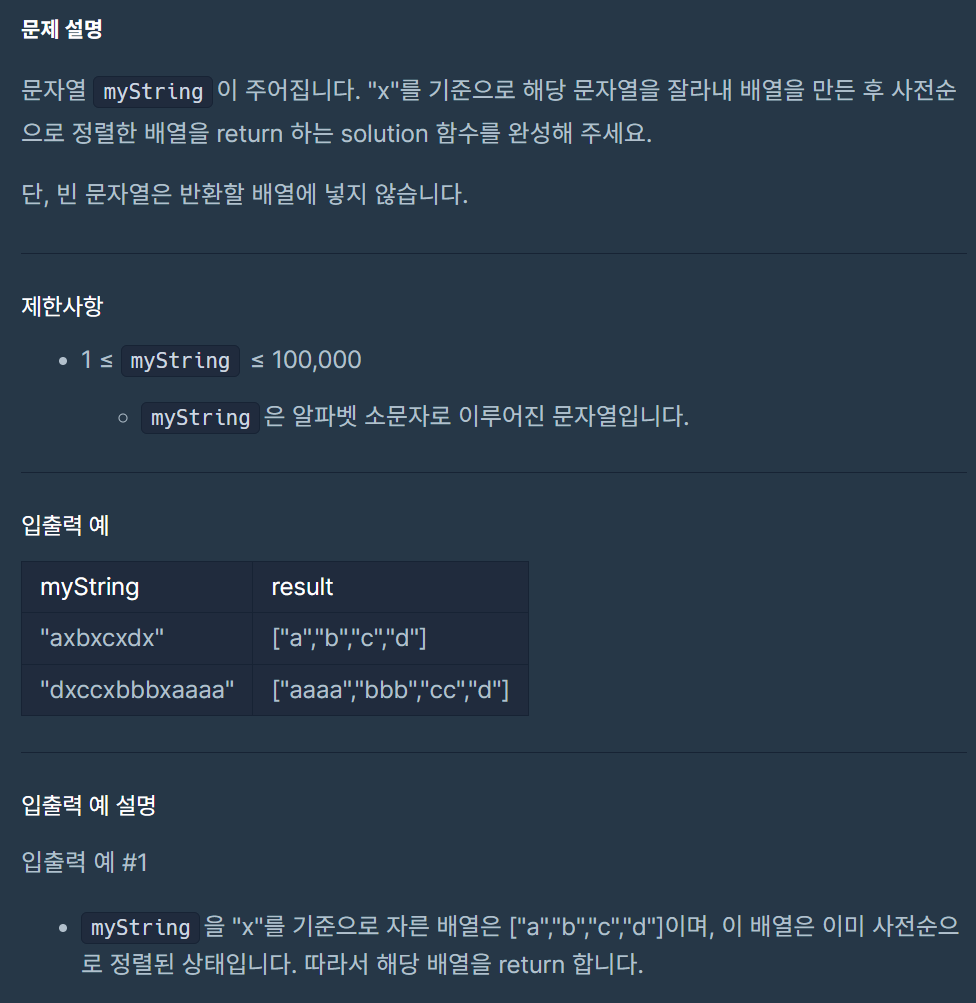
내 풀이다른 사람 풀이앞 게시물을 참고해서 stringstream을 활용하면, x자리를 공백으로 둬서 공백으로 단어를 구분해 answer에 넣은 다음 오름차순하는 방법도 있다!
25.따옴표 차이
C++에서는 문자열을 표현할 때 큰따옴표("")와 작은따옴표('')의 용도가 다르다. 이 두 가지는 서로 다른 타입의 데이터를 나타내기 위해 사용된다.큰따옴표는 문자열 리터럴을 정의할 때 사용된다. 문자열 리터럴은 std::string 또는 const char\* 타입
26.두 수의 합
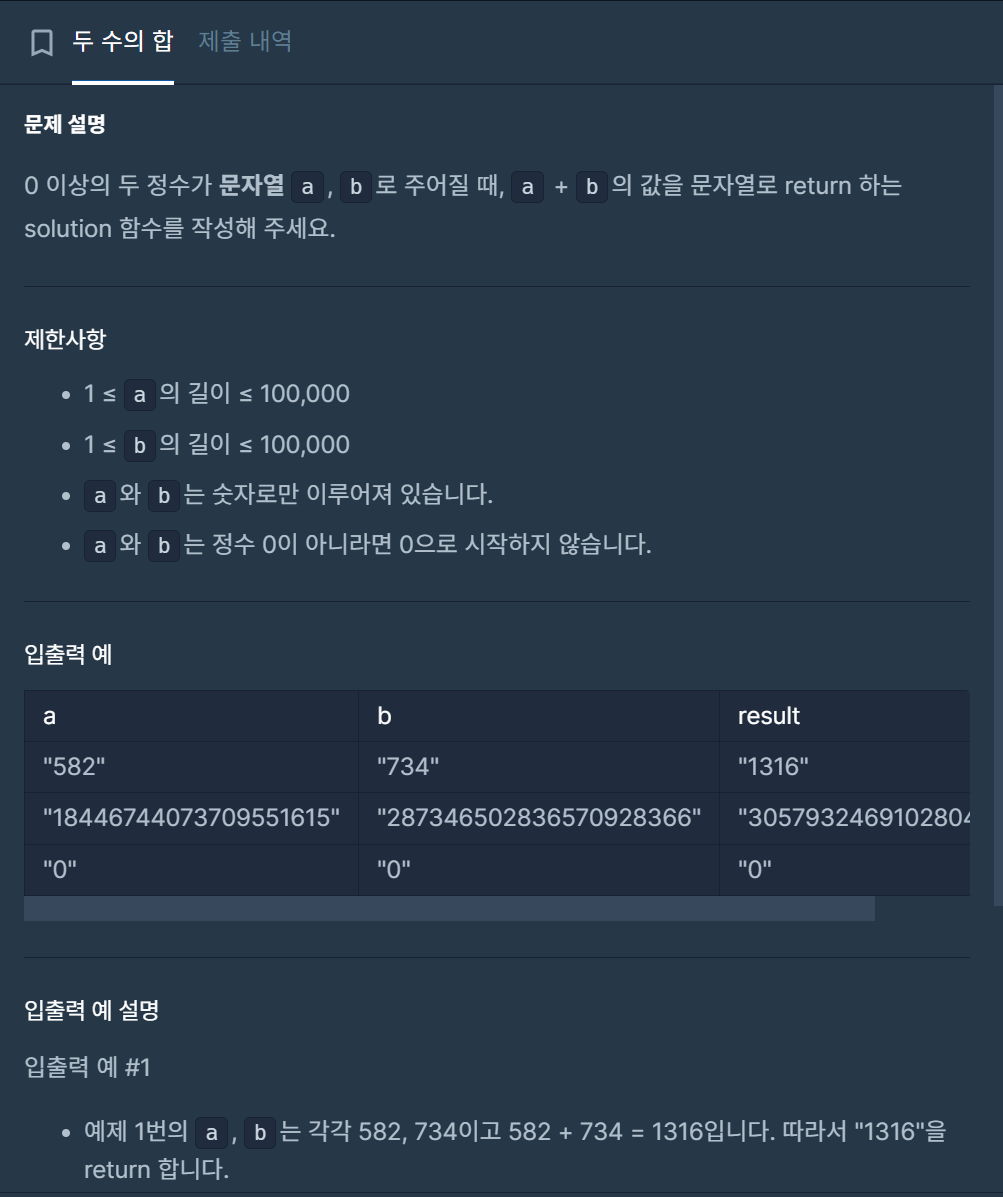
a와 b를 정수로 봤을 때 범위가 int, long, long long을 초과해서 문제 푸는 데에 어려움을 겪었던 문제다.
27.절대값
28.greater<>()
내 풀이다른 사람 풀이greater<>()은, sort 사용 시에 내림차순 할 때 compare을 도와주는 함수형 객제이다.<>안에 형 지정을 해줘야 했지만 지금은 비워둬도 자동으로 채워진다.을 추가해줘야 한다.
29.정사각형으로 만들기
max 함수로 가장 큰 사이즈를 구해서 결국 정사각형을 만드는 것이므로 그 크기만큼 벡터 크기를 초기화해주고그 안에 반복문 사용해서 arr값을 answer로 옮김 (남은 부분은 다 0이 되는 것)
30.erase(), min_element()
프로그래머스 문제를 풀다가..erase함수를 아무리 사용해도 오류가 생기길래 보니까remove함수로 구간 내 특정 수를 찾아서 지운다음, remove는 값만 지우고 배열의 실제 크기는 줄이지 않으므로 erase를 함께 써서 배열 크기를 조정해야 한다고 한다.min_el
31.내적 함수 inner_product()
내적하는 문제를 풀다가나는 이렇게 하나씩 돌면서 곱했는데이렇게 내적함수를 활용하는 방법이 있었다.inner_product(a.begin(),a.end(),b.begin(),0);
32.가우스 법칙 이용하기
n부터 n+a까지 더하는 문제를 풀었는데, 나는 반복문으로 풀었었다.근데 다른 사람 풀이를 보니, 가우스 법칙을 이용할 수 있는 문제였다.price x (1+2+...+count) = price x (count x (count+1))/2
33.isdigit()
문자를 찾기 위해서 숫자 0보다 작거나 9보다 큰 수를 판별했었는데,isdigit() 을 사용해서 판별해도 됐었다.isdigit(숫자) -> 0이 아닌 숫자가 나옴isdigit(문자열) -> 0이 나옴
34.unique()
같은 숫자는 벡터에 넣지 않고 다른 숫자들만 넣는 문제를 풀었다.나는 for문을 돌면서 현재 원소가 이전 원소랑 다를 때만 push_back을 해주었는데 unique()라는 함수가 있었다.unique(시작, 끝) -> 시작 위치부터 끝 위치까지 겹치는 수를 제거하고 하
35.완전탐색
완전탐색 문제들 중 하나를 풀었는데, 다른 방법이 있어서 기록한다.이 문제에서 나는 우선 명함 길이를 모두 가로>세로가 되도록 만들어둔 상태에서 가로의 최대값\* 세로의 최대값 을 구했는데내 풀이다른 사람은 굳이 정렬하지 않고, 아예 배열 중 작은 값을 가로로 삼아서,
36.가장 가까운 같은 글자
첫 접근이 어려웠지만, 나름 잘 풀었다고 생각했던 문제가 있었다.문자를 하나씩 검사하면서 앞에 같은 글자가 나왔는지, 나왔으면 몇 번째 앞인지를 배열에 담아 반환하는 문제였다.나는 2차원 벡터를 사용해서 풀었다.하지만, 다른 사람 풀이를 보니 map으로 더 간단히 풀
37.unordered_map< , >
문자와 숫자가 섞인 문자열을 다 숫자로 바꿔서 반환하는 문제를 풀었다.문자를 하나씩 저장해서 비교하는 방식은 같았지만, 하나씩 one, two, ... 를 비교하는 게 너무 비효율적이라고 생각했는데,unordered_map을 활용해서 string과 char형을 짝지어서
38.set<>
벡터 내 두 수를 더해서 나온 수들을 중복없이 벡터로 정렬해서 반환하는 문제를 풀었다.하지만, 다른 사람 풀이를 보니 set으로 간단히 풀 수 있었다.set은 중복 없이 값을 넣는다는 것을 이용했다.push_back은 vector, deque, list와 같은 순차 컨
39.람다 함수
문제를 풀다가, 람다 함수에 대해 제대로 알고 있다고 생각했는데 아니었다는 것을 깨달았다. 그래서 기록해본다.람다 함수란 익명 함수(이름이 없는 함수)로, 코드에서 간단히 함수 기능을 정의하고 사용하는 함수이다.vector<pair<char, string>>
40.비트 연산과 비트 마스크
&와 |의 개념을 이해하고 있었지만, 문제에서 등장하면 바로바로 써먹지 못 하는 것 같아서 다시 정리해본다.문제는 2018 KAKAO BLIND RECRUITMENT 1차 비밀지도 를 풀었었다.비트 연산과 비트 마스크를 활용하여 푼 결과는 다음과 같은데,여기서 int
41.최소 힙
set<>을 활용해서 3명만 명예의 전당에 있고, 매일 명예의 전당에 오른 사람들 중 최하위 점수를 answer 벡터에 담아서 반환하는 문제를 풀었다. 하지만 시간 복잡도를 따졌을 때, 최소 힙을 사용하는 것이 더 효율적이라는 사실을 알았다.priority_que
42.size_t
코드를 작성하다가, size_t라는 자료형이 있다는 것을 알게 됐다. 자주 못 본 자료형이라 정리해두고자 한다.size_t는 C++에서 사용하는 정수형 자료형으로, 크기나 길이를 표현할 때 주로 사용된다. 일반적으로 배열의 인덱스나 메모리 크기를 나타낼 때 사용되며,
43.#include <limits.h>
<limits.h>는 C와 C++에서 사용하는 헤더 파일로, 데이터 타입의 크기나 값의 범위와 관련된 상수들을 정의하고 있다. 이 헤더 파일을 통해 각 데이터 타입의 최대값과 최소값을 얻을 수 있으며, 이를 이용해 프로그램에서 다양한 계산을 안전하게 처리할 수 있
44.Greedy(그리디) 알고리즘
Greedy = 탐욕적인\-> 눈 앞의 가장 큰 이익을 추구하는 기법탐욕 알고리즘은, 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최정적인 해답에 도달한다
45.vector와 set의 시간복잡도 차이
문제를 풀다가, find함수를 사용해서 푸는 과정에서 vector와 set 사이에 시간복잡도 차이가 있다는 사실을 알게 됐다.find 함수는 O(n)의 시간이 걸리기 때문에, 벡터가 커질수록 시간이 많이 소요된다고 한다. 이를 개선하기 위해 set을 사용하면, set의
46.vector 활용하기
최근 푼 문제들에서, vector를 잘 활용하는 문제들이 있어서 정리를 해보고자 한다.보통 map을 사용해서 value값에 bool형태를 넣었는데, int를 사용해서 특정 key값을 가진 사람 수를 분류해두고자 할 때veci++;혹은mapi++;를 활용하는 경우가 많았
47.#include <cctype>
isalpha(ch)ch가 알파벳 문자이면 0이 아닌 값을, 그렇지 않으면 0을 리턴한다.ispunct(ch)ch가 콤마나 마침표 같은 구두점 문자이면 (이하동문)isdigit(ch)ch가 10진 숫자이면isspace(ch)ch가 개행, 빈칸, 탭, 캐리지 리턴과 같은
48..second의 사용
.first와 .second의 사용을 잘못하고 있었다.그래서 정리를 해두고자 한다..second는 여러 C++ 표준 라이브러리의 클래스에서 반환 타입으로 std::pair 객체를 사용하는 메서드에 쓰인다. 대표적으로 아래와 같은 메서드들이 .second를 반환값으로 사
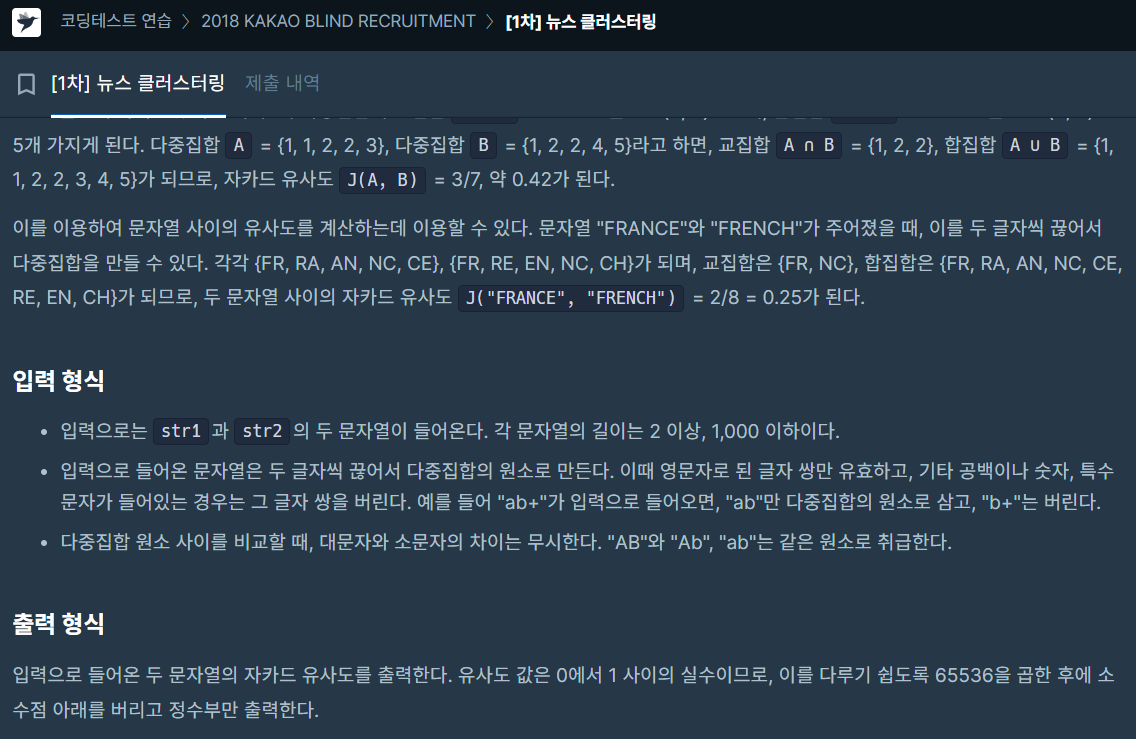
49.[2022 KAKAO BLIND RECRUITMENT] 신고 결과 받기
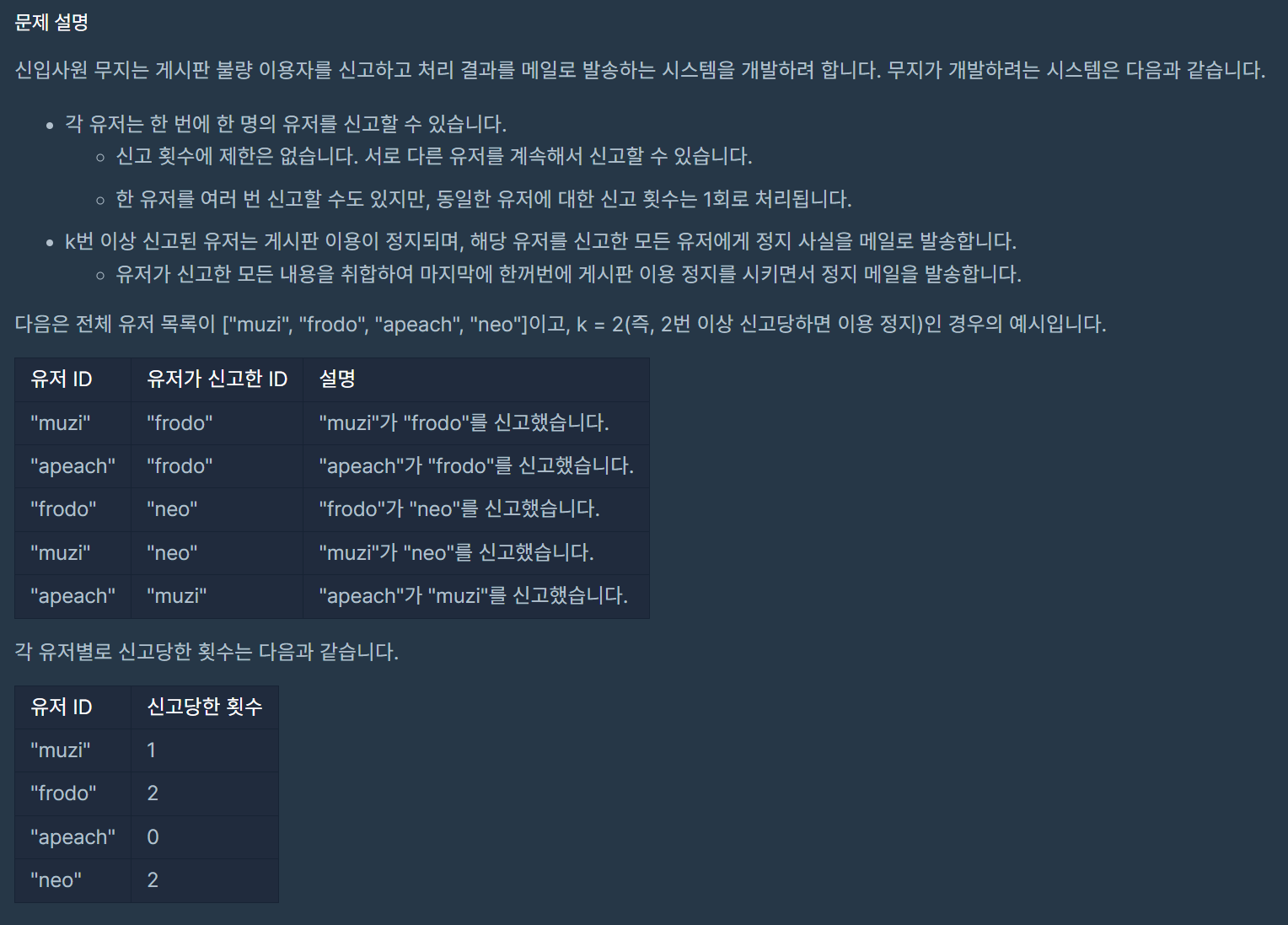
기록해두면 좋을 풀이법이 있어서 기록해둔다.
50.꼼꼼히 검토하는 연습
코테를 자주 볼 때마다 느끼는 거였지만, 항상 반례를 못 찾아서 절반정도만 맞췄다는거다. 이번에도 health의 최댓값을 max_health로 두어 상황마다 다르게 처리했어야 했는데 첫 문제만 적용되게 해버리는 바람에 틀렸었다. 꼼꼼히 검토하는 연습이 필요할 것 같다.
51.Dynamic Programming (DP)
오늘 푼 문제는 동적 계획법을 다루는 문제였다. 개념에 대해 다시 한 번 정리해보고자 한다.다이나믹 프로그래밍은, 시간 복잡도는 줄여주지만 공간 복잡도는 클 수 있다.동적 계획법은 복잡한 문제를 작은 하위 문제들로 나누고, 그 결과를 저장하여(메모이제이션) 중복 계산을
52.문자열에 문자를 더할 때
문자열에 문자를 더할 때, 문자를 '0' 이렇게 char형으로 더하지 않고 "0" 처럼 string형태로 더한다는 사실을 깨달았다. 이유가 궁금해서 정리해본다.'0'은 문자 리터럴이며, 단일 문자를 표현합니다.내부적으로는 ASCII 값 48을 의미합니다.예를 들어:숫자
53.들여쓰기를 줄이는 코드
문제를 풀다가, 나는 들여쓰기가 3개 이하로 잘 줄여지지 않아서 다른 사람의 풀이를 보았다.나는 벡터로 접근했지만, 다른 풀이는 단순 정수 연산을 사용했다.그러면서 초반에 정수가 음수로 변하는 순간 false로 처리하여, 굳이 연속 if문을 쓰지 않도록 했다.
54.발상의 전환, tolower/toupper() 에 대한 추가 지식
문자열 내 단어들에서, 첫 문자는 무조건 대문자로 나머지는 소문자로 변환하는 문제가 있었다.조건1. 단어 맨 앞엔 문자 대신 숫자도 가능, 숫자는 맨 앞에만 등장조건2. 공백은 연속으로 등장 가능나는 tolower()와 toupper()를 활용해서 풀었지만, 코드가 쓸
55.std::count 사용
for루프로 문자열을 전부 검사하여 특정 문자를 찾는 것보다,STL함수인 count를 사용하는 것이 효율적이다.
56.비트연산 활용한 코드
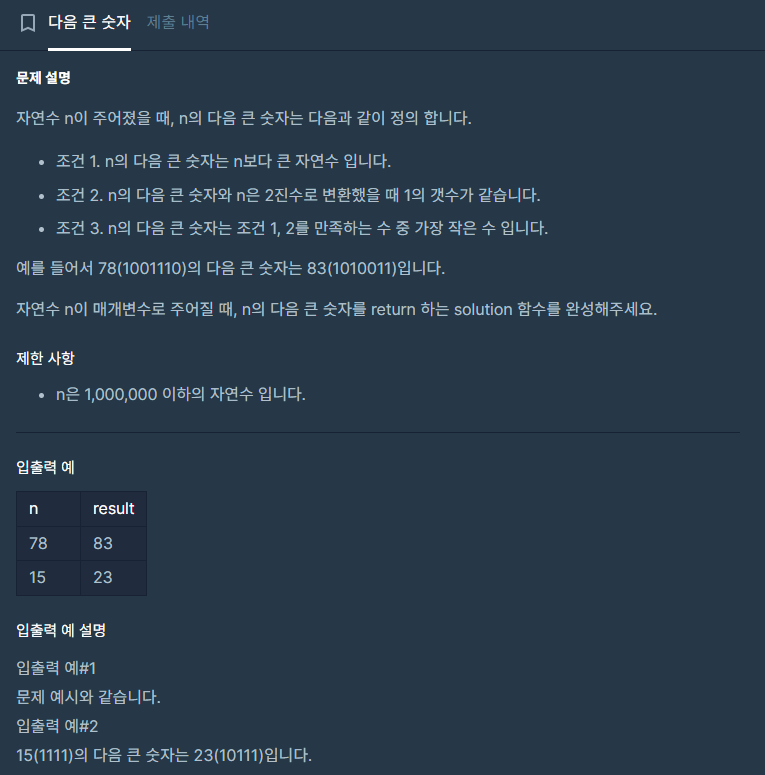
정리해뒀던 글에 덧붙여서..오늘 풀었던 문제가 비트 연산을 활용해 풀 수 있다는 것을 공부했고 여기에 정리해둔다.
57.최소공배수, 최대공약수
최소공배수와 최대공약수를 구하는 공식이 있다.유클리드 호제법이라는 건데,이를 코드로 구현된 내용을 복습하고자 한다.예를 들어, 6과 4의 최대공약수를 구하고자 한다면a = 6, b = 4(b가 0이 아니므로) c = 6 % 4 -> 2a = b -> 4b = c ->
58.원형 수열 풀이
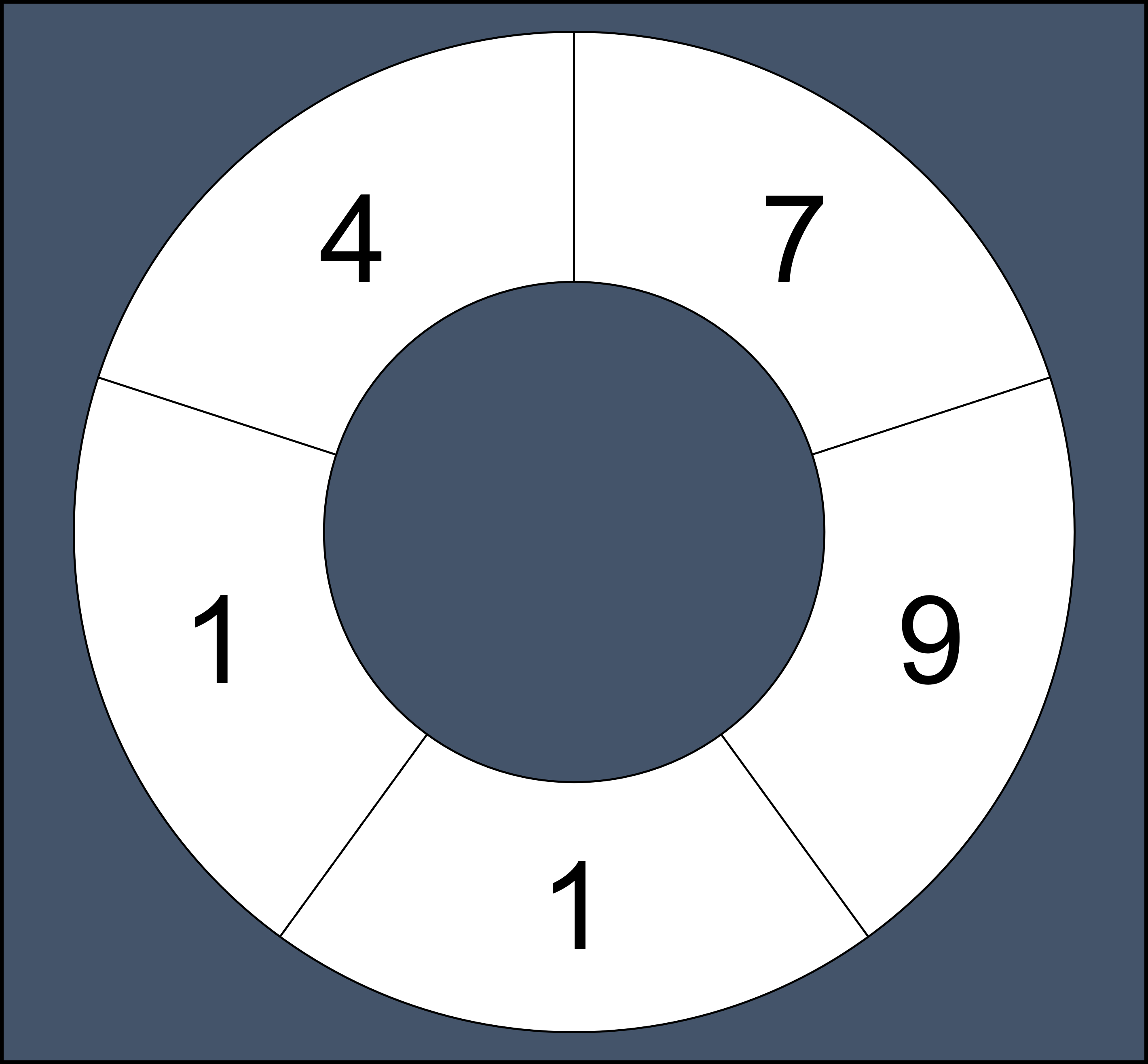
문제는수열 {1, 1, 4, 7, 9} 가 있을 때연속된 1개씩 더한 값: 1, 1, 4, 7, 9연속된 2개씩 더한 값: 2, 5, 11, 16, 10...연속된 5개씩 더한 값: 22했을 때 이 값들을 배열에 넣고, 중복된 수를 뺐을 때 총 몇 개인지를 반환하는 문
59.슬라이딩 윈도우 방식
문제를 풀다보니, 내가 푼 방식이 슬라이딩 윈도우 방식 (하나씩 인덱스를 뒤로 밀어서 그 값만 바로 계산하는 방식, 계속 모든 값을 검사하는 것보다 유리) 이었다.근데 이 방식을 제대로 쓰는 코드가 있어서 기록해둔다.위 코드의 핵심 변경점매번 새롭게 10일 간의 상태를
60.LRU(Least Recently Used) 알고리즘
문제를 풀던 중, LRU라는 개념에 대해 다시 복기할 수 있었다.그래서 개념을 정리해두고자 한다.https://dailylifeofdeveloper.tistory.com/355이 분의 블로그에 잘 정리되어 있어서 참고했다!간단히 정리해보자면리스트에 값(v)을
61.완전탐색, dfs
문제를 풀다가,재귀를 사용하여 dfs를 사용하는 부분이 완벽하게 정리된 것 같지 않아서 정리해본다.본 문제는 모든 경우의 수를 고려하여 탐험 가능한 던전의 최대 갯수를 반환하는 문제였다.visited\[]를 활용하여, 방문한 곳을 true, 방문하지 않은 곳을 fals
62.<map> vs. <unordered_map>
두 개의 차이점이 헷갈려서 정리해본다.unordered_map과 map의 차이는 정렬 여부와 성능에 있다. map: map은 키가 자동으로 정렬된 상태로 저장된다.내부적으로 이진 탐색 트리(예: 레드-블랙 트리)를 사용하여 데이터가 정렬된 순서대로 저장된다.삽입, 삭
63.우선순위 큐(priority_queue)

운영체제에서, 특정 프로세스의 실행 순서를 찾는 문제를 풀었다.맨 앞 프로세스를 다른 프로세스들의 우선순위와 비교해서 가장 큰 우선순위면 실행, 아니라면 맨 뒤로 다시 넣는 방식이었다.이 때 다른 사람이 max_element를 이용해서 우선순위를 비교했다.하지만 이는
64.map과 배열의 코드 효율성 비교
기존 코드(map<string, int> 사용)해시맵(map<string, int>)을 사용하므로, 키를 탐색하는 데 O(log K) 연산이 필요함.키를 비교할 때 string을 사용하기 때문에 상대적으로 연산이 느림.새로운 코드(short\[676] 배열
65.진법 변환 함수
나는 진법을 변환할 때 일일히 나머지를 string으로 변환해서 붙이고, 그 중 10~15는 A~F로 변환하였다.그런데, 다른 분의 풀이를 보니 배열에 string형태로 '0'~'9', 'A'~'F' 전부 포함해두고 그 배열을 활용하면 훨씬 코드가 단순할 수 있다는 걸
66.string(n, c)
answer가 모두 0으로만 이루어진 문자를 찾기 위해 사용된 함수였는데, 처음 봐서 정리해보려 한다.n : 문자열 길이, c : 채울 문자
67.set ↔ map
set과 map이 가끔 헷갈리는 걸 보니 완벽히 이해하지 못했었나보다.그래서 차이점을 표로 정리해보았다.
68.vector 대신 set
2022 KAKAO BLIND RECRUITMENT 주차 요금 계산문제를 풀다가, 개선의 여지가 있는 부분이 있는지 살펴보았다.여기서 vector<string> car_num 대신 set<string> 사용하기현재는 차량이 IN 상태인지 확인하기 위해 fin
69.vector<tuple<string, int, int>>
tuple<> 을 처음 알게되어 기록해본다.