Cross-Encoder vs. Bi-Encoder
기초를 잘 다집시다 🥺😅
..
(Dear myself..)

기본적으로 어떤 내용일까?
언어 모델 중 하나인 "BERT"에 사용되는 기본적인 내용으로, 언어 모델에 관심이 있고, 특히 NLU 과정에 대해 공부하고자 하는 학생이라면 꼭 알고 넘어가야되는 내용이다.
언어 모델에는 대개 input을 받아들이는 부분인 Encoder가 있다.
따라서, Encoder는 간단히 말해 "텍스트를 숫자로 이루어진 벡터로 변환하여 모델이 이해할 수 있도록 하는 역할"을 한다.
이를테면, 자연어를 컴퓨터가 처리할 수 있는 형태로 번역하는 과정일 것이다.
이름만 봐도 직관적으로 알 수 있듯,
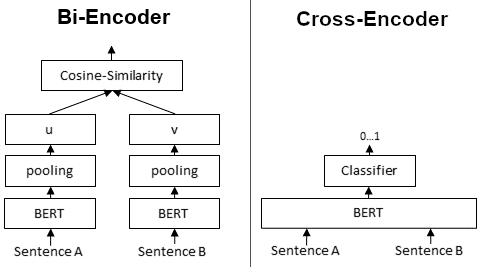
Single Encoder(Cross Encoder)는 Encoder가 하나 있다. 즉 input도 "하나"여야된다.
그에 반해, Dual Encoder(Bi Encoer)는 Encoder가 두 개로, input도 "두 개" 들어간다.
조금 더 깊게 알아보겠다.
공통 전제:
- 두 문장이 주어진다. (이를 각각 '문장 A', '문장 B'로 칭하겠다.)
- 해당 두 문장을 비교하기 위해 언어 모델에 입력을 넣는다.
Cross Encoder(Single Encoder)
두 문장을 동시에 Transformer Network에 전달한다.
입력 문장 쌍의 유사성을 나타내는 [0~1] 사이의 출력 값을 먼저 생성한다.
이때, 두 개의 문장을 모델에 넣어 내부에서 문장 간의 "문장 간 관계"를 파악한다.
-
입력: 문장 A, 문장 B를 하나의 입력으로 결합하여 입력
‣ 이후, 모델 내부에서 두 문장 간의 interaction을 직접적으로 학습하여 유사도를 계산 -
장점:
- 높은 정확도
: 문장 A와 문장 B가 함께 입력되므로, 문장 간의 관계와 맥락을 깊이 있게 파악할 수 있음
- 적은 정보 손실
: 문장이 변형되지 않은 상태에서 비교하기 때문에 단어 간의 미묘한 관계나 문맥적 손실이 최소화된다.
-
단점:
- 느린 속도
: 가령 100개의 문장이 있다면, 의 연산을 모두 수행(Dual Encoder는 각 개별적인 input이 들어가므로, 단순 비교, 즉 100회만 진행)
🦾 Note!
이때, 문장 쌍을 구성하는 방식은 크게 다음과 같다:
- pairwise
- triplet
: 두 문장뿐만 아닌, 'positive pair(긍정쌍)', 'negative pair(부정쌍)', 'anchor(기준 문장)'을 고려한다. '기준 문장'과 '긍정쌍'은 최대한 거리적으로 가깝게, '부정쌍'과는 거리적으로 멀게하는 방식이다.
거리적으로 가까움은 곧 '의미적 유사도'를 의미하기 때문이다.
Bi Encoder(Dual Encoder)
두 문장, A와 B를 비교하기 위해 각각 독립적으로 두 개의 Encoder에 입력하여 개별적인 문장 임베딩을 생성한다. 이후, 생성된 두 벡터에 대해 Cosine Similarity를 계산하여 두 문장의 유사도를 판단한다.
- 장점:
- 빠른 연산 처리
: 각 문장들을 임베딩 해둔 다음, 독립적으로 각 문장을 단순 벡터 연산으로 처리(효율성 측면에서 굉장히 좋음)
- 확장성
: 미리 계산된 임베딩을 cache 등에 저장하고 검색에 활용하는 등 다양한 적용 방식이 있다. - 단점:
- 상대적 정확도 저하
: 두 문장을 독립적으로 처리하기에, 문장 간의 상호작용을 직접적으로 고려하지 못한다. 따라서 임베딩 과정에서의 정보 손실 위험이 있으며, 임베딩 모델의 성능에 따라 최종 성능이 달라지는 경우도 다소 있다.
아래부터는 대략적인 적용 가능 분야의 예시이다.
...
해당 개념은 굉장히 기본적인 내용이기에 다양한 접근법의 초석이 되기도 한다.
특히, Reranker 기반 모델 학습을 위해 자주 사용된다.
Reranker 또한 n개의 문장을 비교하여 어떤 기준에 따라 재순위화를 하는 과정이니 문장 간의 비교가 필수적이다. 초기 검색 결과를 바탕으로 문장 간의 Relavant를 더 정확하게 평가하여 재순위화를 하는 과정이기 때문이다.
대개 Encoder 종류에 따른 tradeoff가 명확히 존재하기 때문에 Reranking Task에서는 다음과 같은 문제가 있다.
가령, 하나의 입력에 대해 문장 5개를 비교해야하는 상황에서 각각의 문장을 Cross Encoder로 연산을 하도록 할지(입력 하나에 10번의 연산이지만, input이 수천개인 경우나 6개 이상의 후보가 있다면 연산 속도는 명확히 차이날 것이다.), 더 많은 문장을 효율적으로 비교하기 위해 Bi Encoder로 비교를 하게 할지가 관건이다.
추가로... 요즘 흥미로운 분야가 정말 다양한데,
- 모델 최적화 및 경량화
- 언어 임베딩
- 강화학습
이렇게 세 가지다..
근데 벌써 방학이 다 끝나간다~
이번 8월 마지막 주, 공부해온 내용들을 기반으로 정리도 할겸 많은 업데이트를 해보도록 하겠다.
