RAG
🔎 Retrieval-Augmented Generation(검색 기반 증강 생성 방식)
RAG는 검색 기반 증강 생성 방식이다.
이는 모델 파라미터(Parametric Memory)와 외부 지식 베이스(Non-Parametric Memory)를 결합하여, 질의 시점에 관련 문서를 검색하여 Language Model(이하 LM)으로 응답을 생성하는 방식을 통합적으로 수행하는 프레임워크이다.
Retriever&Generator을 활용한 Jointly Fine-tune(즉, Full Fine-tuning)과 비교하여 보았을 때,
해당 기술의 장점은 다음과 같다.:
- 자원의 제약이 덜하다.
- LM의 Hallucination(환각) 문제를 완화한다.
- 추가 지식 업데이트 시, 전체 모델을 다시 훈련시키지 않고 검색 인덱스만 교체하면 최신 정보를 효과적으로 쉽게 반영한다.
RAG는 단순히 문서를 잘게 쪼개어 프롬프트에 붙여 쓰는 것을 넘어, Retriever과 Generator 두 개의 모듈을 통해 End-to-End로 진행하는 아키텍쳐를 제공한다.
NLP에서의 RAG 기법을 처음 제안한 논문인 'Retrieval-Augmented Generation for
Knowledge-Intensive NLP Tasks'의 아키텍처도는 다음과 같다.
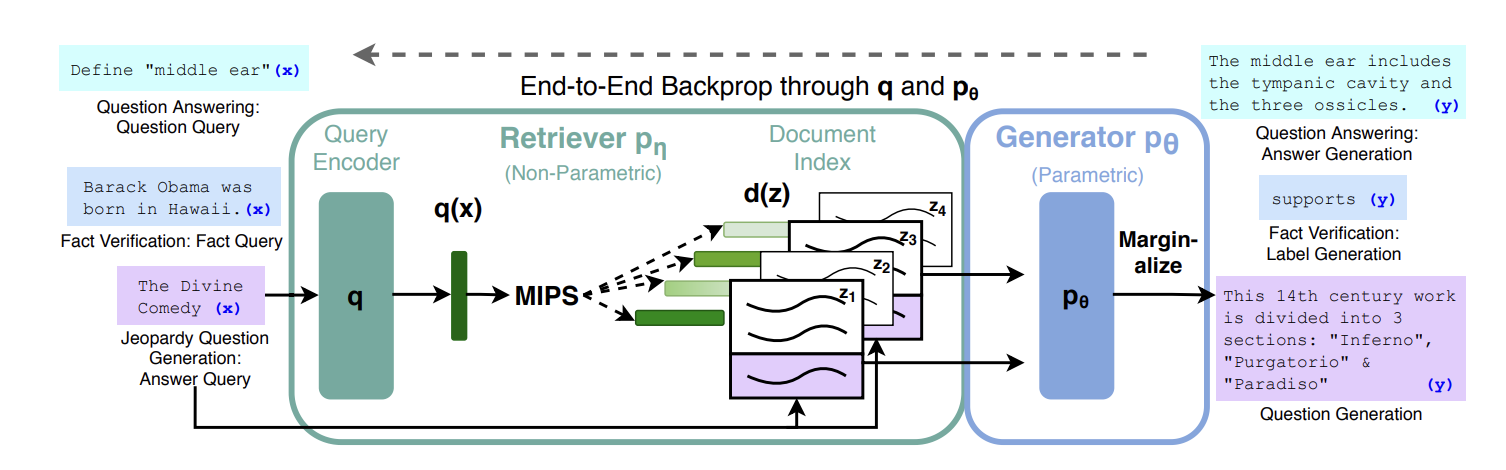 그림1. RAG 논문 제안 구조도
그림1. RAG 논문 제안 구조도
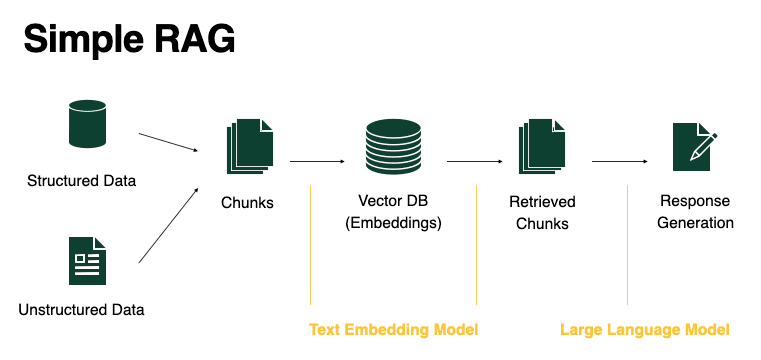 그림2. 간략화된 Simple RAG 구조도
그림2. 간략화된 Simple RAG 구조도
RAG 기술은 LM Full Fine-tuning을 위한 고도화된 지식은 필요하지 않으나, 전반적인 LM에 대한 이해는 필요한 분야이다.
- Retriever(검색기): 문서에 대해 벡터화 및 임베딩으로 효과적인 검색을 도움
- 역할: 문서에 대한 벡터 인덱스 구축
→ Encoder-Only 사용(e.g., BERT, DPR) - Generator(생성기): 쿼리에 대한 응답을 만들기 위해 Retrieval 결과를 기반으로 응답 생성
- 역할: 쿼리와 관련된 문서 기반 응답 생성
→ Encoder-Decoder Model: 입력과 검색 결과를 한 번에 인코딩한 후, 디코더가 생성을 진행(e.g., T5, BART)
→ Decoder-Only Model: Retrieval 결과를 prompt 맨 앞에 붙여 응답 생성(e.g., GPT 계열 모델)
해당 포스트는 전반적인 RAG에 대한 내용은 아니므로 RAG의 세부적인 기법들에 대해서는 언급하지 않을 예정이며, 추후 전반적 RAG에 대한 공부 내용도 게시할 예정이다.
다만, 해당 포스트는 RAG의 많은 기법들 중, 기본 RAG에 대한 플로우를 제시한 후 Proposition RAG에 사용되는 Propositional Chunking을 중심적으로 공부한 내용을 진행할 예정이다.
RAG Flow
1. 문서 준비
(e.g., pdf, docx, txt 등의 형식)
2. 문서 Parsing 및 Chunking
(e.g., Chunking by Line, Chunking by Grammatical Structures..)
3. 임베딩(Vector Embedding)
4. Retrieval
- Top-k: FAISS의 코사인 유사도 기반 상위 근거 문장 선택
- Re-Ranking: Cross-Encoder나 BM25 후처리
- Chain-of-Retrieval: 1차 검색 → 2차 맥락 확장 검색
- graphRAG/KG: 규칙 간 관계를 Knowledge Graph(지식 그래프)로 저장 후 활용
5. 답변을 위한 근거 후보 Selection
- Evidence Scoring: 유사도+정확도 가중합 방식~(현재 프로젝트에서는 아마 이거 사용할 예정)~
6. LM Train (Fine-Tuning)
7. LM Inference
(수정 중)
여담으로... 나는 Retriving이라는 말은 한국어로 하면 '검색'이지만.. 단순한 searching의 돋보기 아이콘이 아니라 뭐랄까 모든 문서를 샅샅이 훑으며 관련된 문서를 찾는 그런 그림이 생각이 난다..
전체 문서 네트워크에서 의미 기반으로 연관 문서를 수색하는..... 그런.. 느낌...
근데 그런 아이콘이 잘 없어서 gpt로 생성을 해봤다 ^.^..
 내가 만들었슨
내가 만들었슨
출처
- 그림1, RAG 논문 제안 구조도: Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeuralPS 2020(https://arxiv.org/pdf/2005.11401)
- 그림2, 간략화된 Simple RAG 구조도: https://www.bentoml.com/blog/building-rag-with-open-source-and-custom-ai-models
- https://medium.com/@med.el.harchaoui/rag-evaluation-metrics-explained-a-complete-guide-dbd7a3b571a8
