
학습자료
✔️ Korea University - Unstructured Data Analysis (Text Analytics)
고려대 산업경영공학부 DBMS 연구실 유투브에서 올려준 NLP 영상을 바탕으로 쭉 정리하고자 한다. 3년 전에 올라온 영상으로, 추가적으로 다른 학습자료를 활용하여 내용을 추가할 예정이다.
텍스트 분석 활용
특허 분석 시스템
: 새로운 특허가 나왔을 때, 기존의 특허와는 차별되는 특허인지, 그렇지 않은지를 문서 클러스터링을 활용해 확인
토픽 추출
: LDA를 사용해서 토픽추출, 토픽 간의 유사성을 그래프로 표현도 가능
텍스트 분석 특징
언어 자체가 가지고 있는 모호성이 있다
반어법, 뉘앙스 등을 기계가 찾아내기 어렵다는 점이 존재
텍스트 전처리(Text Preprocessing)
텍스트 전처리 종류
텍스트는 용도에 맞게 아래 전처리 과정을 거친다.
1. 토큰화(tokenization)
코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업
2. 정제(cleaning)
갖고 있는 코퍼스로부터 노이즈 데이터를 제거
- 불용어 제거, 등장 빈도가 적은 단어 제거, 길이가 짧은 단어 제거,
3. 정규화(normalization)
표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만든다.
- Stemming, Lemmatization, 대/소문자 통합
Lemmatization & Stemming
1. Lemmatization(표제어 추출)
Lemmatization(표제어 추출)은 단어의 원형을 찾는 것을 말한다.
표제어(Lemma) 추출은 단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단한다.
예를 들어서 am, are, is를 이 단어들의 뿌리인 be라는 표제어로 바꾸는 걸 말한다.
NLTK에서 WordNetLemmatizer 라는 표제어 추출 도구를 사용할 수 있다.
표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 하는 것이다.
형태소란 "의미를 가진 가장 작은 단위"를 의미한다.
형태소의 종류
1) 어간(stem) : 단어의 의미를 담고 있는 핵심부분
2) 접사(affix) : 추가적인 의미를 주는 부분
2. Stemming(어간추출)
Stemming(어간추출)은 어간(Stem)을 추출하는 작업을 말하며, 이 작업은 섬세한 작업이 아니므로 어간 추출 후에 나오는 단어는 사전에 존재하지 않는 단어일 수 있다.
일반적으로 Stemming이 Lemmatization보다 빠르다.
포터 알고리즘(Poter Algoritm), NLTK의 랭커스터 스태머(Lancaster Stemmer)알고리즘 등을 사용할 수 있다.
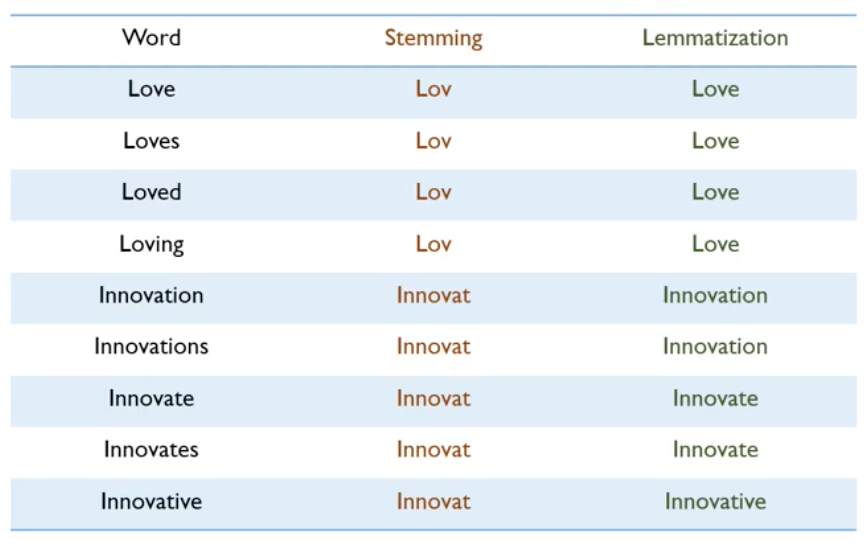
출처 : https://wikidocs.net/21707
Representation
문서/단어를 표현하는 여러 방법 중, 카운트 기반의 단어 표현(Count based word Representation) 방법인 DTM(Document Term Matrix)과 TF-IDF를 알아보자.
이 방법들을 통해 통계적 접근으로 어떤 단어가 문서 내에서 얼마나 중요한지, 문서의 핵심어 추출, 검색 엔진에서 검색 결과의 순위 결정, 문서들 간의 유사도를 구하는 등의 작업을 할 수 있다.
참고 ) TextRank를 이용한 키워드 및 핵심 문장 추출 | PageRank의 이해, TextRank 구현
단어의 표현
1. 국소표현(Local Representation)
국소표현(Local Representation)는 해당 단어 그 자체만 보고, 특정값을 맵핑하여 단어를 표현하는 방법이다.
이산표현(Discrete Representation)이라고도 한다.
2. 분산표현(Distributed Representation)
분산표현(Distributed Representation)은 해당 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법이다. 예를 들어 Puppy(강아지)라는 단어 근처에 cute, lovely 라는 단어가 자주 등장하면, puppy라는 단어는 cute, lovely한 느낌이다로 단어의 뉘앙스를 표현할 수 있다는 장점이 있다.
큰 범위에서연속표현(Continuous Represnetation)이라고도 한다.
연속표현 안에는 LSA, LDA가 있다.
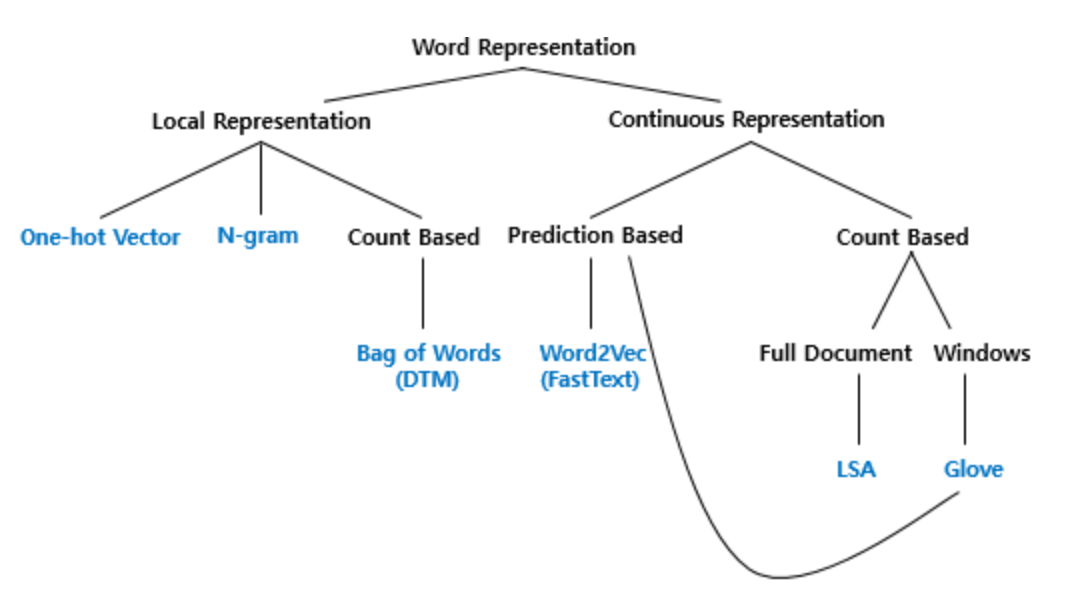
Bag of Words
고전적인 방법으로, 문서에서 사용된 단어의 빈도를 표현한다.
문서 안에서 단어들의 순서는 고려하지 않고, 오직 단어가 얼마나 등장했는지를 표현한다.
TF-IDF
Word Weighting
TF-IDF(단어 빈도-역 문서 빈도, Term Frequency - Inverse Document Frequency)
: 특정한 단어가 문서에서 얼마만큼 중요한지를 수치화 한 방법으로, TF-IDF가 대표적으로 많이 사용된다.

'단어 w가 문서 d에 중요하다(TF-IDF 값이 크다)' 라고 말한다면, 문서 d에서는 많이 나오고 Corpus에서는 적게 나온다고 볼 수 있다.
Word Vector
- One-hot representation : 단어 하나하나를 1로 표현
- Distributed representation : 단어 벡터를 실수로 표현. 의미가 비슷한 단어끼리 공간 상에 유의미한 벡터를 표현하게 됨. 단어 사이의 유사성을 표현할 수 있게 됨.
Pre-trained Language Model
-> GloVe
-> ELMO, GPT, BERT
- Feature Selection
- Feature Extraction : 차원축소 d > d'
- Latent Semantic Analysis (LSA)
- Latent Dirichlet Allocation (LDA)
- LDA 설명 참고 : https://wikidocs.net/30708
