
PARTITION BY
- PARTITION BY는 윈도우 함수(Window Function)와 함께 사용되며, 특정 기준(파티션)으로 데이터를 그룹화한 후 해당 그룹 내에서 연산을 수행하도록 해줌
기본 개념
-
원본 데이터의 행 수를 유지하며 데이터를 그룹화하고, 그룹 별 연산을 수행할 수 있도록 해줌
-
데이터를 그룹화한다는 점에선 GROUP BY와 동일하나, GROUP BY는 그룹별로 하나의 결과만 반환하는 반면, PARTITION BY는 원본 행 수를 유지하면서 그룹별 연산을 수행할 수 있음
-
특정 컬럼을 기준으로 데이터 그룹을 나누고, 해당 그룹 내에서 순위, 합계, 평균 등의 연산을 적용할 때 주로 사용됨
주요 기능
- PARTITION BY는 주로 윈도우 함수와 함께 사용되며, 다음과 같은 기능을 수행할 수 있음
(1) 그룹별 순위 계산
- 각 그룹 내에서 RANK(), DENSE_RANK(), ROW_NUMBER() 등을 사용하여 순위를 계산할 수 있음
SELECT
EmployeeID,
Department,
Salary,
RANK() OVER
(PARTITION BY Department ORDER BY Salary DESC) AS RankInDepartment
-- Department(부서)별로 데이터를 그룹화(파티션)하고
-- 각 파티션 내에서 Salary(급여)가 높은 순서대로 정렬했을 때의
-- 순위 담은 RankInDepartment 열 생성
FROM Employees;
(2) 그룹별 합계, 평균 등 집계 함수 적용
- SUM(), AVG(), COUNT(), MAX(), MIN() 등의 집계 함수를 그룹별로 계산할 수 있음
SELECT
EmployeeID,
Department,
Salary,
SUM(Salary) OVER (PARTITION BY Department ORDER BY EmployeeID) AS RunningTotal
-- Department(부서)별로 데이터를 그룹화(파티션)하고
-- 각 파티션 내에서 현재 레코드까지의 Salary 속성 합계 계산한 값
-- 담은 RunningTotal 열 생성
FROM Employees;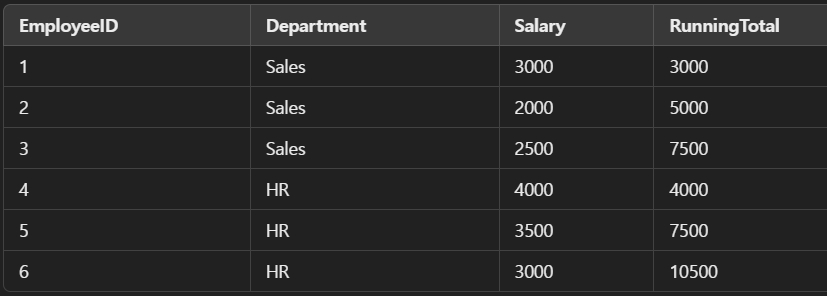
GROUP BY VS PARTITION BY
- GROUP BY는 생성된 그룹을 하나로 취급하기 때문에 그룹 별로 하나의 레코드만 존재할 수 있음
SELECT Department, SUM(Salary) AS TotalSalary
FROM Employees
GROUP BY Department;- PARTITION BY는 파티션을 생성하긴 하나, 파티션 내에서 각 레코드를 개별적으로 취급할 수 있음
SELECT EmployeeID, Department, Salary,
SUM(Salary) OVER (PARTITION BY Department) AS TotalSalary
FROM Employees;
-- 개별 직원 정보가 유지되면서 부서별 총급여를 확인할 수 있음PARTITION BY 절 내 ORDER BY의 역할
- PARTITION BY 절 내에 ORDER BY 가 들어가면 '누적' 기능을 수행하도록 바뀜

미야우