Pagerank 구하는 방법
Eigenvector Method
주어진 그래프로 확률론적 인접행렬을 구할수 있다.
구한 확률론적 인접행렬이 M일때, 구글행렬 G는
(d는 보통 0.85)
구글행렬의 고유벡터중 가장 큰값을 가지는 고유값를 이용(가장 큰 고유값는 1을 넘지 않음)
가장큰 고유값에 대응하는 고유벡터인 dominant eigenvector가 pagerank가 됨
Power Iteration Method
벡터 v를 1/N으로 모두 같게 초기화 시킨다
(N은 노드의 수, v=[1/N , 1/N, 1/N , ... 1/N])
결정한 iteration수만큼 다음 식을 반복시킨다
(G는 구글행렬, v_k는 k번째의 v값)
iteration만큼 반복한후 구한 이 pagerank가 됨
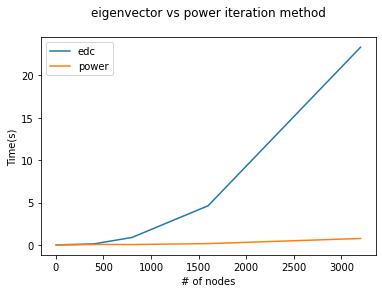
결론: power iteration이 훨씬 효과적인 방법임을 알 수 있다.
Algorithm 소개
1단계. Map 함수의 입력데이터
-pageId,{set of outgoing links}
2단계. Reduce함수의 키값
-PageID (pageid를 키값으로 reducebykey를 이용해 랭크값 더할예정)
3단계.맵 함수에서 출력할 키-값 쌍 정의
-(linked PageID,PageRank credit to distribute)
4단계.리듀스 함수를 정의
-(PageID,PageRank of the current iteration)
Flow->
입력데이터는 페이지아이디와 페이지아이디가 향하는 다른 페이지아이디들인 target으로 구성 (key,target sets)
flatMap으로 키값마다 (target,target노드가 가지는 가중치)페어로 바꾼후 reducebykey이용해 모든 rank값을 더함
dead-end와 spider trap의 문제를 해결하기 위해 teleport기능이 필요함.
teleport를 하기 위해 mapvalues이용해 키별로 페이지 랭크값에 dv+1/N(1-d) 적용시킴
수렴값은 현재 페이지랭크값의 평균에서 이전 페이지 랭크값의 평균을 빼고
maxIter를 20으로 두고 지정한 수렴값보다 적으면 반복문을 종료하고 아니면 계속 실행
구현 코드는 아래와 같다.
N=30000
d=0.85
convergenceTol=1e-12
compare_convergence=[]
maxIter=20
pr=sc.broadcast([1./float(N) for _ in range(N)])
for i in range(maxIter):
data_result=pro_data.flatMap(lambda x:[(target,pr.value[x[0]]/len(x[1])) for target in x[1]])\
.reduceByKey(lambda x,y:x+y).sortBy(lambda x: x[0]).mapValues(lambda v:d*v+1/N*(1-d))
pr_new=data_result.map(lambda t:t[1]).collect()
pr_new.insert(0,0)
err=sum(pr.value)/N-sum(pr_new)/N
if err<convergenceTol:
break
pr=sc.broadcast(pr_new)
compare_convergence.append(err)
iteration이 진행됨에 따라 수렴값이 줄어드는것을 알 수 있다.
기존의 페이지 랭크를 개선하기 위해 텔레포트를 다른 방식으로 적용해 볼 수 있다.
Teleport
기존방식
spider trap과 dead end를 피하기 위해 사용한 기존방식은 랜덤워커가 일정한 작은 확률로는 다른곳으로 텔레포트 할수있는데
이 확률이 어떤 페이지든지 동일한 확률을 가진다.
새로운방식
모든 페이지가 동일한 확률을 가져서 랜덤으로 가는거말고 bias를 주어서 주제에 따라 좀더 개인화된 텔레포트를 가능하게 할수있다
random walk마다 bias를 주면 텔레포트 할때 현재 페이지가 속해있는 집합에서 같은 집합내에 다른 페이지로 텔레포트 하기 때문에 이방식을 선택했다.
집합은 해당 주제와 관련된 페이지만을 포함하고 집합으로 텔레포트 발생마다 다른 벡터를 얻는다.
주어진 데이터는 숫자들로만 이루어져 있기 때문에 같은 집합인지 아닌지 판별하는 기준을 jaccard coefficient를 이용해 구별했다.
pagerank에서 bias 주는방법
dv+1/N(1-d)에서 N을 전체페이지길이에서 도착할 노드가 속한 집합S의 길이로 바꿔주어서 teleport 집합에 있는 모든 페이지에 같은 가중치를 부여한다.
->
outlink가 0인경우에는 기존방식을 사용
구현 방법
page id별로 가지고있는 outgoing link들 끼리의 유사도를 계산하기 위해 jaccard similarity를 이용했고
주어진 threshhold보다 높은 outgoing link들을 같은 집합으로 취급해 키별로 각 집합의 길이를 구했으며 이를 S의 길이로 사용했다.
jaccard_result=pro_data.flatMap(lambda x:[(x[0],y,jaccard(x[1],dictionary.value[y])) for y in x[1]])\
.filter(lambda x:x[2]>=0.205).map(lambda x:(x[0],1)).reduceByKey(lambda x,y:x+y).collect()
set2=jaccard_result.copy()
set2.append((17094,1))
result=sc.parallelize(set2).sortByKey().map(lambda x:x[1]).collect()
set_len=sc.broadcast(result)
N=30000
d=0.85
convergenceTol=1e-25
compare_convergence=[]
maxIter=20
pr=sc.broadcast([1./float(N) for _ in range(N)])
for i in range(maxIter):
data_result=pro_data.flatMap(lambda x:[(target,pr.value[x[0]]/len(x[1])) for target in x[1]])\
.reduceByKey(lambda x,y:x+y).sortBy(lambda x: x[0]).map(lambda v:(v[0],d*v[1]+(1/set_len.value[v[0]])*(1-d)))
pr_new=data_result.map(lambda t:t[1]).collect()
pr_new.insert(0,0)
pr=sc.broadcast(pr_new)
compare_convergence.append(abs(err))최종 결과
random teleport와 bias를 줘 topic specific teleport를 했을때 차이점에 대한 결과입니다.
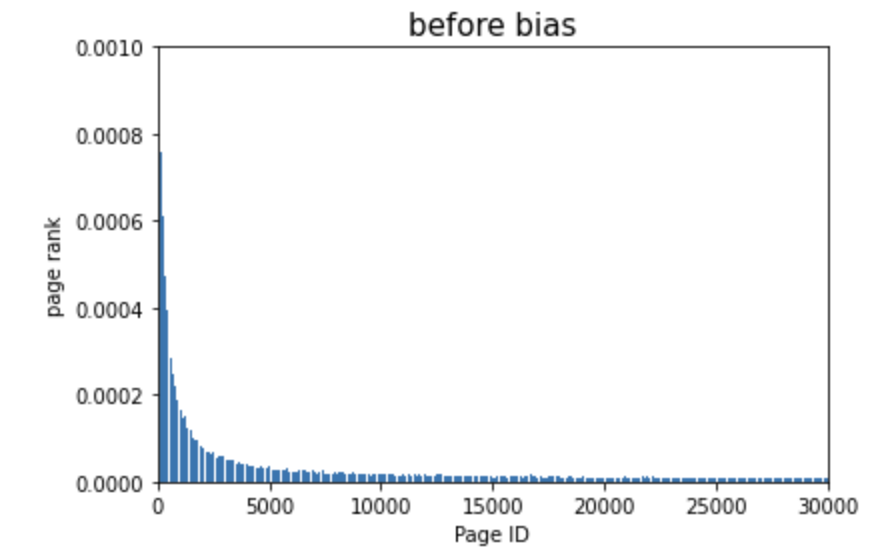
Before
After
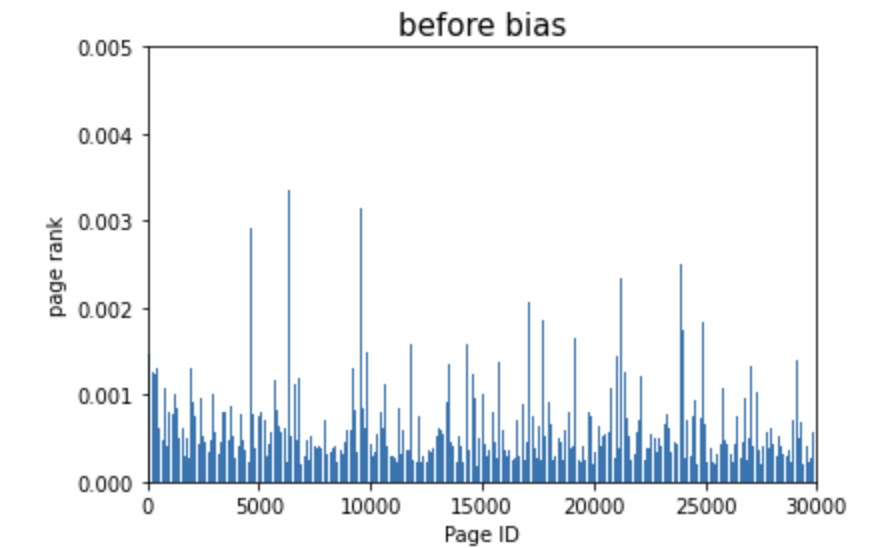
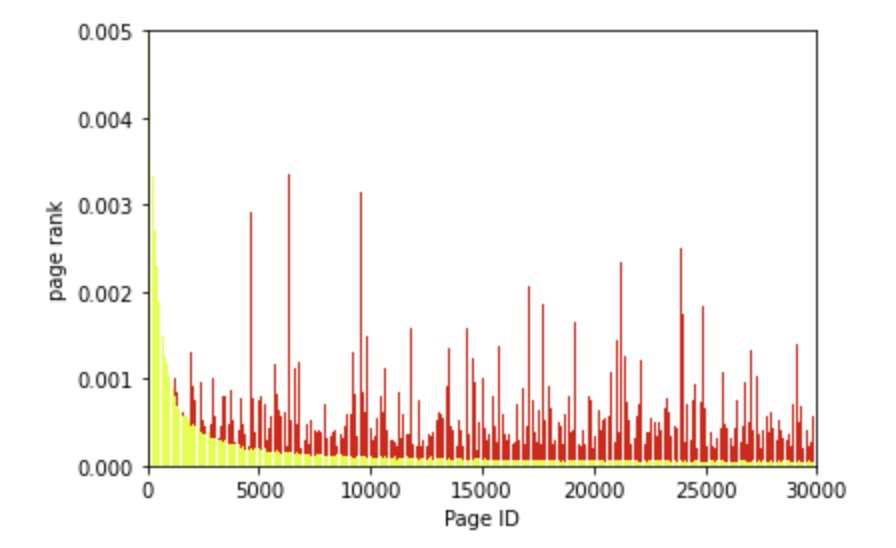
bias 적용전에는 초반부의 페이지들에 페이지 랭크값이 집중되어있었지만
bias 적용후에 개인화된 페이지 랭크값이 적용되어서 다양하게 분포되어 있음을 확인할 수 있다.
bias 적용전과 후를 한눈에 보기 위해서 하나의 그래프로 표현하면 다음과 같다.