이전 포스팅에서는 다양한 한글 형태소 분석기와 BM25, FAISS를 앙상블 리트리버로 묶어 간단한 성능 테스트를 해보았습니다.
🤗 한글 검색 성능 테스트 l 한글 형태소 분석기(Kiwi, Kkma, Okt) + BM25, FAISS 리트리버
테스트 결과를 바탕으로 좀 더 나은 유사도 챗봇을 만들어 보았습니다.
✅ 배경
📌 토크나이저 : 형태소 분석기 Kiwi
한글에서는 한 단어가 여러 형태소로 구성되기 때문에 단순 공백 기준 토크나이징은 한계를 갖습니다. 예를 들어, "우리나라의 정부"라는 문장은 "우리나라", "의", "정부"로 분해됩니다. 형태소 분석기는 문장에서 각 단어의 형태와 역할을 분석해, 의미 단위로 정확하게 나누기 때문에 더 세밀한 처리가 가능합니다. 예를 들어, "갔습니다"라는 단어는 "가", "ㅆ", "습니다"로 분리되어, 동사와 어미를 정확히 분석할 수 있습니다.
📌 임베딩 모델 : intfloat/multilingual-e5-large
Contextualized embedding model을 사용하였습니다. 전통적인 임베딩 방식에서는 단어에 고정된 벡터를 할당하지만 컨텍스트 기반 임베딩 모델은 단어가 사용되는 문맥에 따라 벡터를 달리 할당합니다. BERT, GPT와 같은 모델들은 컨텍스트 기반 임베딩을 생성합니다.
현재 한국어 임베딩 모델 벤치마킹으로는 infloat/multilingual-e5, BAAI/bge-m5 많이 쓰인다고 합니다.
📌 검색 모델 : BM25+Faiss 앙상블 모델
EnsembleRetriever에서는 FAISS가 문서 임베딩 기반 검색을 담당하며, BM25와 결합하여 다중 검색 방식을 사용합니다. FAISS는 의미적 유사성을 바탕으로 검색하는 반면, BM25는 키워드 기반의 토큰 유사성을 바탕으로 검색합니다. 두 검색기의 결과는 가중치(0.3 vs 0.7)를 기반으로 결합됩니다. FAISS는 문서 임베딩을 사용해 문서 간 의미적 유사성을 비교합니다. 따라서 단순 키워드 일치보다 질문과 문서의 의미가 비슷한지 판단하는 데 유리합니다. 다만 FAISS만 사용하여 유사도 챗봇을 만든 경우 키워드를 놓치는 경우가 있어서 앙상블 모델을 활용하게 되었습니다.
BM25
BM25는 정보 검색의 전통적인 방법 중 하나로, 문서의 텍스트 기반 유사도를 계산하여 관련성을 평가한다. 점수 계산 요소는 다음과 같습니다.
- Term Frequency (TF): 문서 내 특정 단어의 빈도수. 단어가 문서에서 자주 등장할수록 점수가 높아집니다.
- Inverse Document Frequency (IDF): 단어가 전체 문서 집합에서 얼마나 희귀한지를 측정합니다. 희귀한 단어가 문서에 포함되어 있으면 점수가 높아집니다.
- Document Length Normalization: 문서의 길이에 따라 점수를 조정합니다. 긴 문서에서는 단어 빈도에 의한 점수를 줄이는 역할을 합니다.
FAISS
FAISS(Facebook AI Similarity Search)는 효율적인 벡터 검색 라이브러리로, 주로 대규모 데이터에서 빠르게 유사한 벡터(문서 임베딩)를 찾는 데 사용됩니다.
- 임베딩 모델에서 변환된 임베딩 벡터들을 인덱싱하여 FAISS 인덱스에 저장
- 임베딩 벡터로 변환된 학습자의 질문을 FAISS 인덱스의 벡터들과 유사도 계산하여 가장 비슷한 벡터 반환
MMR
앙상블 모델의 search_type="mmr"로 설정하였습니다. MMR은 Maximal Marginal Relevance로, 관련성이 높은 문서부터 선택하되 이미 선택된 문서들과 유사성이 낮은 문서를 추가하여 결과의 다양성을 증가시킵니다.
✅ 구현
데이터셋은 공개할 수 없어 첨부하지 않았습니다.
📌 앙상블 모델
!pip install langchain langchain_community kiwipiepy rank_bm25 sentence_transformers faiss-gpu datasets transformers질의응답 데이터셋 문서를 불러와서 질문과 답변 리스트를 생성해 줍니다. 제가 가지고 있는 데이터셋의 각 컬럼 내용 예시입니다. 참고해 주세요.
df['SENT_CONTENT'] 다양한 말투의 질문 : 우리나라 정부 형태가 뭐야?
df['INT_SENTENTCE'] 정제된 말투의 질문 : 우리나라 정부 형태에 대해 알려주세요.
df['INT_RESPONSE'] 답변 : 우리나라의 정부 형태는 의원내각제적 요소를 가미한 대통령제 입니다.import pandas as pd
# Excel 파일 경로 지정
file_path = '중학사회(취합).xlsx'
# Excel 파일 읽기
df = pd.read_excel(file_path, engine='openpyxl')
# 질문과 답변 리스트 생성
questions = df['SENT_CONTENT'].tolist()
int_sentences = df['INT_SENTENCE'].tolist()
int_responses = df['INT_RESPONSE'].tolist()
print("총 질문 개수:", len(questions))사용자의 질문과 데이터셋의 질문 간 유사도 검색을 수행하였습니다.
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
from sentence_transformers import SentenceTransformer
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import torch
import pandas as pd
import numpy as np
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain.vectorstores import FAISS
from langchain.schema import Document
from kiwipiepy import Kiwi
# Kiwi 형태소 분석기 설정
kiwi = Kiwi()
# 형태소 분석을 통해 문서를 토큰화하는 함수
def kiwi_tokenize(text):
return [token.form for token in kiwi.tokenize(text)]
# 문서와 쿼리를 토큰화
tokenized_questions = [kiwi_tokenize(question) for question in questions]
documents = [Document(page_content=question, metadata={'index': i}) for i, question in enumerate(questions)]
# BM25 모델 설정
kiwi_bm25 = BM25Retriever.from_documents(documents, preprocess_func=kiwi_tokenize)
# FAISS 설정
hf_model_name = "intfloat/multilingual-e5-large" # contextualized embedding model 사용
hf_embeddings = HuggingFaceEmbeddings(model_name=hf_model_name)
faiss = FAISS.from_documents(documents, hf_embeddings).as_retriever()
# EnsembleRetriever에서 검색 수행
retriever = EnsembleRetriever(
retrievers=[kiwi_bm25, faiss],
weights=[0.3, 0.7],
search_type="mmr",
)학습자의 질문은 "우리나라 정부 형태가 뭐야?"입니다. 학습자의 질문과 유사도가 높은 데이터셋 질문 3가지, 그리고 그에 대한 답변을 출력했습니다.
query = "우리나라 정부 형태가 뭐야?"
# 검색 수행
results = retriever.invoke(query)
# 중복되지 않은 int_sentence를 저장할 set
unique_sentences = set()
# 상위 3개의 중복되지 않은 int_sentence를 찾는 리스트
top_results = []
# 결과에서 중복되지 않은 int_sentence만 저장
for result in results:
index = result.metadata['index'] # 검색된 결과의 인덱스
if int_sentences[index] not in unique_sentences:
unique_sentences.add(int_sentences[index]) # 중복 제거
top_results.append(result)
if len(top_results) == 3: # 3개의 고유한 int_sentence가 채워지면 종료
break
# 결과 출력
print("사용자 질문:", query)
print("\n상위 3개 결과:")
for result in top_results:
index = result.metadata['index']
print(f"질문: {int_sentences[index]}")
print(f"답변: {int_responses[index]}")
print()
----------
사용자 질문: 우리나라 정부 형태가 뭐야?
상위 3개 결과:
질문: 우리나라의 정부 형태에 대해 알려주세요.
답변: 우리나라의 정부 형태는 의원내각제적 요소를 가미한 대통령제 입니다.
질문: 우리나라 대통령제에서의 의원내각제적 요소는 무엇인가요?
답변: 1. 국무총리제, 2. 국회의원의 장관직 겸직 가능, 3. 행정부의 법률안 제출권입니다.
질문: 총재 정부란 무엇인가요?
답변: 총재 정부는 프랑스 혁명 당시 로베스피에르의 가혹한 공포 정치에 반발하여 일어난 정부로 5명의 총재가 행정을 담당하였습니다.학습자의 질문과 데이터셋의 답변 간 유사도 검색을 수행하는 경우도 있습니다. 아래와 같이 리스트만 아래와 같이 다르게 지정해주면 됩니다. 데이터셋의 질문과 답변 중 무엇과 학습자의 질문을 유사도 검색 할 것이냐에 따라 출력 결과가 다르기에 선택이 필요합니다.
# 문서와 쿼리를 토큰화
tokenized_questions = [kiwi_tokenize(question) for question in questions]
documents = [Document(page_content=question, metadata={'index': i}) for i, question in enumerate(questions)]
----------
사용자 질문: 우리나라 정부 형태가 뭐야?
상위 3개 결과:
질문: 우리나라의 정부 형태에 대해 알려주세요.
답변: 우리나라의 정부 형태는 의원내각제적 요소를 가미한 대통령제 입니다.
질문: 대통령제와 의원 내각제의 차이점이 무엇인가요?
답변: 대통령제는 입법부와 행정부가 엄격하게 분리된 정부 형태입니다.
의원 내각제는 입법부와 행정부의 권한이 융합된 정부 형태입니다.
대통령제와 의원 내각제를 구분하는 방법은 정부와 의회의 융합 정도를 보면 됩니다.
정부와 의회가 철저하게 구분되어 있으면 대통령제, 정부와 의회가 융합되어 있으면 의원 내각제입니다.📌 앙상블 모델 카테고리 분류 ver
좀 더 사용자가 원하는 답변을 내놓게 할 수는 없을까 고민하던 중 시도해 본 방법입니다. 같은 단어지만 의미가 다르게 사용되는 경우에 데이터셋과 학습자의 질문에 카테고리를 지정할 수 있는 과목에 대해서는 시도해 보면 효과가 있을 것으로 기대합니다. 여기서 같은 단어지만 의미가 다르게 사용되는 경우란 사회 과목에서는 "조선시대의 시장" → 역사 / "주식 시장" → 경제, 과학 과목에서는 "뉴턴의 제2법칙에서 힘" → 물리 / "근육의 수축력" → 생물의 경우가 있겠네요.
허깅페이스의 제로샷 분류 모델 중 한국어 지원 모델을 사용하여 무료로 쉽게 카테고리 분류를 진행했습니다. 정확률이 상당히 괜찮았지만 검토가 필요할 것 같긴 합니다.
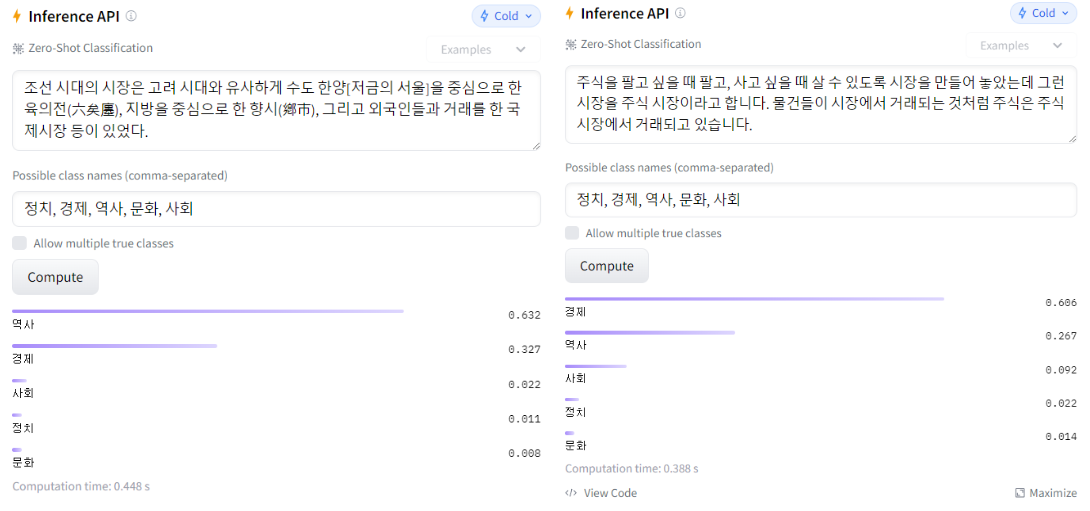
import pandas as pd
from datasets import Dataset
from transformers import pipeline
# 파이프라인 설정 (GPU 사용)
pipe = pipeline("zero-shot-classification", model="MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7", device=0)
# JSON 파일 경로 지정
file_path = '중학사회(취합).xlsx'
df = pd.read_excel(file_path, engine='openpyxl')
# pandas DataFrame을 Hugging Face Dataset으로 변환
dataset = Dataset.from_pandas(df)
# 카테고리 후보들
candidate_labels = ["정치", "경제", "사회", "문화"]
# 배치 처리로 카테고리 할당
def categorize_batch(examples):
result = pipe(examples['INT_RESPONSE'], candidate_labels)
return {"CATEGORY": [res['labels'][0] for res in result]} # 각 입력에 대해 가장 높은 점수의 카테고리 선택
# dataset에 파이프라인 적용
dataset = dataset.map(categorize_batch, batched=True)
# 결과를 DataFrame으로 변환 후 엑셀로 저장
df_result = dataset.to_pandas()
df_result.to_excel('./중학사회(취합)_카테고리 추가.xlsx', index=False, engine='openpyxl')이후 학습자가 질문을 작성하고 카테고리를 지정하는 것으로 가정하고, 학습자 질문과 같은 카테고리의 데이터셋에서 검색을 수행하도록 하였습니다.
# 사용자 질문에 대한 카테고리 결정
query = "우리나라 정부 형태가 뭐야?"
category = '정치'
# 특정 카테고리에 해당하는 문서만 필터링
filtered_documents = []
for i, question in enumerate(questions):
doc_category = df.loc[i, 'CATEGORY']
if doc_category == category:
filtered_documents.append(Document(page_content=question, metadata={'index': i, 'category': doc_category}))
----------
사용자 질문: 우리나라 정부 형태가 뭐야?
상위 3개 결과:
질문: 우리나라의 정부 형태에 대해 알려주세요.
답변: 우리나라의 정부 형태는 의원내각제적 요소를 가미한 대통령제 입니다.
질문: 우리나라 대통령제에서의 의원내각제적 요소는 무엇인가요?
답변: 1. 국무총리제, 2. 국회의원의 장관직 겸직 가능, 3. 행정부의 법률안 제출권입니다.
질문: 총재 정부란 무엇인가요?
답변: 총재 정부는 프랑스 혁명 당시 로베스피에르의 가혹한 공포 정치에 반발하여 일어난 정부로 5명의 총재가 행정을 담당하였습니다.✅ 결과
기존 유사도 기반 학습 챗봇(BM25 단독)과 비교한 결과입니다.
📌 앙상블 모델
1. 학습자 질문 : 대류가 뭐야?
1-1. BM25 단독
대류란 무엇인가요?1-2. 앙상블 모델

2. 학습자 질문 : 삼투압이 뭐야?
2-1. BM25 단독
대기압이란 무엇인가요?2-2. 앙상블 모델

📌 앙상블 모델 카테고리 분류 ver
1. 학습자 질문 : 우리나라 정치체제는?
1-1. BM25 단독
스파르타의 정치체제는 어떤 특징을 지녔나요?
우리나라의 정부 형태에 대해 알려주세요.
우리나라의 큰 하천은 어디로 흘러가나요?1-2. 앙상블 모델
유사도 TOP3 목록 순서가 바뀌었습니다. 데이터 부족이 아쉽긴 하지만 깔끔하네요.
우리나라의 정부 형태에 대해 알려주세요.
조선의 통치 체제는 어떻게 구성되었나요?
스파르타의 정치체제는 어떤 특징을 지녔나요?2. 학습자 질문 : 의원내각제가 뭐야?
2-1. BM25 단독
의원 내각제가 무엇인가요?
의원 내각제와 입헌 군주제는 어떻게 다른가요?
투표 용지를 따로 만들어 비례 대표 국회 의원을 선출하는 이유는 무엇인가요?2-2. 앙상블 모델
마지막 출력 결과가 마음에 들게 바뀌었습니다.
의원 내각제가 무엇인가요?
의원 내각제와 입헌 군주제는 어떻게 다른가요?
대통령제와 의원 내각제의 차이점이 무엇인가요?3. 학습자 질문 : 대통령제가 뭐야?
3-1. BM25 단독
대통령제가 무엇인가요?
장원제가 무엇인가요?
대통령제를 실시하는 나라에는 어떤 나라들이 있나요?3-2. 앙상블 모델
유사도 TOP3 목록 순서가 바뀌었습니다.
대통령제가 무엇인가요?
대통령제를 실시하는 나라에는 어떤 나라들이 있나요?
수니파는 무엇인가요?4. 학습자 질문 : 우리나라 대통령 누구야?
4-1. BM25 단독
대통령제를 실시하는 나라에는 어떤 나라들이 있나요?
우리나라 대통령제에서의 의원내각제적 요소는 무엇인가요?
우리나라의 정부 형태에 대해 알려주세요.4-2. 앙상블 모델
최근 데이터가 업데이트되지 않아 한계가 있지만 "누구"를 묻는 질문에 사람과 관련된 질문을 반환합니다.
노무현은 누구인가요?
문재인은 누구인가요?
우리나라의 정부 형태에 대해 알려주세요.5. 학습자 질문 : 이승만이 누구야?
5-1. BM25 단독
이승만은 누구인가요?5-2. 앙상블 모델
다양한 선택지를 주네요.
이승만은 누구인가요?
이승만의 정읍 발언에 대해 알려주세요.
처칠은 누구인가요?✅ 느낀점
유사도 챗봇도 다양한 시도를 해보니 교육 업계에서 간단한 학습 챗봇으로 사용하기에 괜찮다는 생각이 듭니다. 다양한 방법을 적용해보며 더 나은 결과가 도출되는 것을 보니 재밌네요. 다만 오늘 포스팅한 내용을 적용할 때에는 다양한 고민과 시도를 통해 결정해야 할 것 같습니다. 여러 결과도 직접 확인해 보고 싶네요.
- 어떤 형태소 분석기를 사용할 것인가
- 사용자 쿼리와 데이터셋의 질문/답변 중 어느 것과 유사도 분석을 할 것인가
- 어떤 임베딩 모델을 사용할 것인가
*한국어 임베딩 모델 벤치마킹으로는 infloat/multilingual-e5, BAAI/bge-m5 많이 쓰임- 앙상블 모델의 비율은 어떻게 설정할 것인가
코드 전문
*링크 접속하셔서 파일 다운 받으시면 코드를 확인할 수 있습니다.
