[Paper Review] AI 학습에 교육학을 더하다 : Pedagogically-Inspired Data Synthesis (2026.2.)
Paper Review

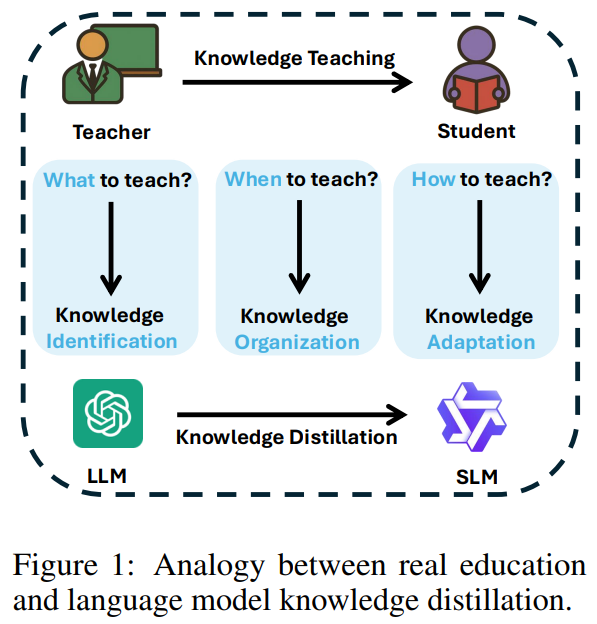
이번 포스팅에서는 최근 ICLR 2026에 채택된 Bowei He 등의 논문, Pedagogically-Inspired Data Synthesis for Language Model Knowledge Distillation를 소개하려 합니다.
제가 교육공학을 전공했다 보니 Pedagogically-Inspired라는 제목을 보고 확인해 볼 수밖에 없었는데요. 이 논문은 지식 증류(Knowledge Distillation)를 교육학적 관점에서 접근한 흥미로운 연구입니다. 교육학적 원리를 적용한 IOA 프레임워크를 통해 AI 모델의 지식 결합 진단, 단계적 커리큘럼 구성, 인지 수준 맞춤 데이터 생성을 수행하여 효율적인 지식 증류를 달성하는 방법을 제시합니다.
해당 논문은 arXiv 뉴스레터로 메일을 확인하다 발견하게 되었습니다. 해당 뉴스레터 개발기와 구독 방법이 궁금하시다면 이 포스팅도 함께 확인해 주세요 🙌
목차
🌟 Introduction
⚙ Methodology
✅ Conclusions and Future Works
📍 부록
💡 Insight
🌟 Introduction
지식 증류의 중요성
- 목표 : 대규모 교사 모델(Large Language Model, LLM)의 지식을 작은 학생 모델(smaller LLM, SLM)로 압축하여 효율적인 AI 시스템 배포
- 기존 방식 : 주료 교사-학생 모델 간 로짓 분포나 중간 레이어 표현의 불일치를 최소화하는 데 의존
- 최근 경향 : 독점 LLM(예. OpenAI o1, GPT-4) 접근 제한으로 인해 교사 모델이 생성한 합성 데이터를 사용하여 SLM을 훈련(예: Alpaca, DeepSeek-R1-Distill 등)
기존 합성 데이터 기반 증류의 문제점
- 교육학적 인식 부족 : 지식 전달을 체계적인 학습 과정이 아닌 일회성 데이터 학섭 및 훈련 작업으로 취급함
- 지식 격차 타겟팅 실패 : SLM이 필요로 하는 특정 지식을 식별하지 못하고 데이터 생성에 집중함
- 교육 과정 부재 : 지식 구성 요소의 순서와 적절한 교육 속도를 무시하여 SLM이 개념을 깊이 이해하기 어렵게 만듦
- 인지 수준 고려 부족 : SLM의 인지 수준에 맞게 지식 표현 방식을 조정하지 않아 최적의 지식 흡수를 방해함
교육학적 원리의 적용 필요성
핵심 원리
- 무엇을 가르칠 것인가 (What to teach) : 결정적인 지식 결핍을 식별하고 목표로 삼아야 한다.
- 언제 가르칠 것인가 (When to teach) : 점진적으로 복잡성이 증가하는 진보적인 커리큘럼을 통해 지식을 구성해야 한다.
- 어떻게 가르칠 것인가 (How to teach) : 학습자의 인지 수준에 맞게 지식 표현 방식을 조정해야 한다.
적용 이론
- 블룸(Bloom)의 완전 학습 이론 (1968) : 완전 학습(Mastery Learning)은 준거 참조 진행(criterion-referenced progress)을 강조합니다. 학습자는 선수 학습 내용을 충분히 숙달했음을 증명한 후에만 다음 단계로 나아가며, 그렇지 못할 경우 타겟팅된 보충 학습을 받습니다.
▶️ 매커니즘 적용 : 단계별 게이팅(Stage gating) + 보충 학습 루프 (기준 수준의 역량을 증명한 후에만 다음 단계로 진행) - 비고츠키(Vygotsky)의 근접 발달 영역 (1978): 근접 발달 영역(Zone of Proximal Development, ZPD)은 학습자가 현재 혼자서 해결할 수 있는 수준을 약간 넘어서는 과제를 제공하되, 비계(scaffolds, 학습 조력 구조)를 함께 지원함으로써 난이도의 '단계 크기'를 조절하는 것을 강조합니다.
▶️ 매커니즘 적용 : 제한된 난이도 증가 + 비계 설정(Scaffolding) (학습 가능한 단계를 유지하고, 표현 방식을 적응시키며 인지 부하를 줄임) - 커리큘럼 이론 + 선수 지식
▶️ 매커니즘 적용 : 지식 구조를 존중하기 위한 의존성 그래프 기반의 위상적 순차 구성(Topological sequencing)
제안 방법론 : IOA
- Identifier (식별자, 무엇을 가르칠지를 다룬다.)
- 학생 모델의 지식 결핍(Deficiency)을 정밀하게 진단한다.
- 지식 모듈 간의 의존성 그래프를 그려 어떤 지식을 먼저 채워야 하는지 타겟팅한다.
- Organizer (조직자, 언제 가르칠지를 다룬다.)
- Mastery Gating : 특정 단계를 마스터해야만 다음 단계로 넘어가는 규칙을 적용한다.
- 커리큘럼 설계 : 쉬운 개념에서 복잡한 개념으로 이어지는 학습 경로를 구축한다.
- Adapter (적용자, 어떻게 가르칠지를 다룬다.)
- 인지적 정렬 : 추상적인 개념을 비유나 직관적인 표현으로 반환한다.
- 추론 분해 : 복잡한 과정을 원자 단위의 단계로 쪼개어 학생 모델이 소화하기 쉽게 만든다.
성능 및 효율성
- 성능: 기존 증류 기법 대비 상당한 성능 향상을 달성했다.
- 효율성: 학생 모델은 교사 모델 성능의 94.7%를 유지하면서 파라미터는 1/10 미만을 사용한다.
- 특화 영역: 복잡한 추론 작업(MATH, HumanEval)에서 기존 SOTA 대비 19.2% ~ 22.3% 향상되었다.
⚙ Methodology
Identifier : Knowledge Deficiency Diagnosis and Targeting
Identifier 모듈은 학생 모델의 성능 격차를 체계적으로 평가하고 지식 의존성을 분석하여 가장 중요한 지식 격차를 우선순위화한다.
지식 모듈 분해
- 복잡한 도메인(예. 수학)을 구성 요소 지식 모듈로 분해하여 구체적인 결핍을 식별한다.
- 수학의 경우, 지식은 주요 범주 (예: 대수학, 기하학, 미적분학)와 그 안의 특정 지식 모듈 (예: 선형 방정식, 이차 함수, 삼각함수의 항등식)로 계층적으로 구성된다.
- 지식 계층 구조는 도메인별로 한 번 생성되면 고정된 상태를 유지한다.
성능 격차 평가
- 교사 모델 와 학생 모델 의 각 지식 모듈 에 대한 성능을 탐침 작업(Probe Task) 로 평가한다.
- 성능 격차 계산 : 교사와 학생의 해당 모듈 점수 차이를 교사 점수로 정규화한다.
- 결핍 모듈 분류 : (일반적으로 0.3)일 경우, 개입이 필요한 결핍 모듈로 분류한다.
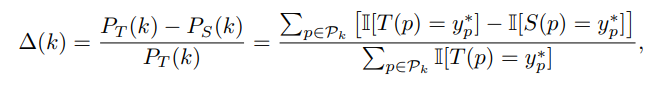
타겟 지식 선택 및 우선순위화
- 지식 의존성 그래프 구축
- 목표: 교육학적으로 건전한 학습 궤적을 설정하기 위해 선행 지식 관계를 이해한다.
- 의존성 강도 계산: 모듈 가 의 성능에 미치는 영향을 조건부 성능 분석을 통해 계산한다.
- DAG 보장: 순환 의존성이 발견되면 가장 약한 간선(낮은 의존성 점수)을 제거하여 방향성 비순환 그래프(DAG)를 유지한다.
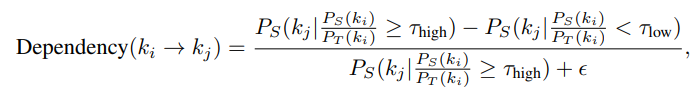
- 결핍 심각도 순위 지정
- 심각도 점수 계산: 절대 성능 격차와 지식 계층 내 상대적 중요도를 모두 고려한다.
는 0.7로 설정되어 성능 격차를 우선시한다.
- 심각도 점수 계산: 절대 성능 격차와 지식 계층 내 상대적 중요도를 모두 고려한다.
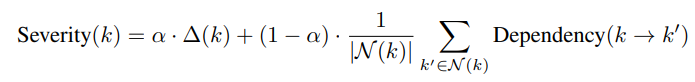
- 타겟 지식 선택
- Identifier는 심각도 점수로 순위가 매겨진 결핍 모듈 목록 를 출력한다.
- 는 심각도에 따라 상위 개 모듈로 선택되며, 이는 증류 효율성을 극대화한다.

Organizer : Progressive Curriculum Design with Mastery Learning
Organizer 모듈은 Identifier가 선정한 결핍 모듈을 Bloom의 숙달 학습 원리와 Vygotsky의 ZPD에 따라 교육학적으로 구조화된 학습 시퀀스로 변환한다.
커리큘럼 시퀀스 구성
- 학습 시퀀스 구성
- 와 의존성 그래프 를 기반으로 학습 단계 를 구성한다.
- 각 단계 는 의미적으로 유사한 지식 모듈의 부분 집합을 포함한다.
- 제약 조건: 위상 순서(Prerequisites)를 존중하여 선행 지식이 먼저 학습되도록 한다.
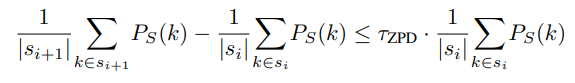
- ZPD 기반 난이도 제어
- 목표: 인지 과부하를 줄이고 부드러운 학습 곡선을 만들기 위해 연속된 학습 단계 간의 난이도 증가를 제어한다.
- 제약: 단계 간 평균 난이도 차이가 이하로 제한된다 ( ).
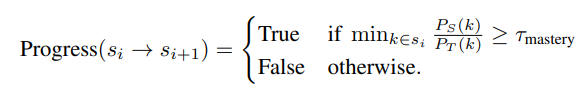
숙달 기반 점진적 학습
- 숙달 요구 사항
- Bloom의 기준 참조 평가에 따라 단계별로 엄격한 숙달 요구 사항을 적용한다.
- 각 모듈 에 대해 학생 모델 성능이 교사 모델 성능의 (기본값 0.9) 이상에 도달해야 다음 단계 로 진행할 수 있다.
- 교정 데이터 생성 및 반복
- 숙달에 도달하지 못하면, 해당 단계에서 숙달될 때까지 교정 데이터( )를 합성하여 훈련을 계속한다.
- 이는 지식 격차 누적을 방지하고 선행 개념을 충분히 숙달하도록 보장한다.
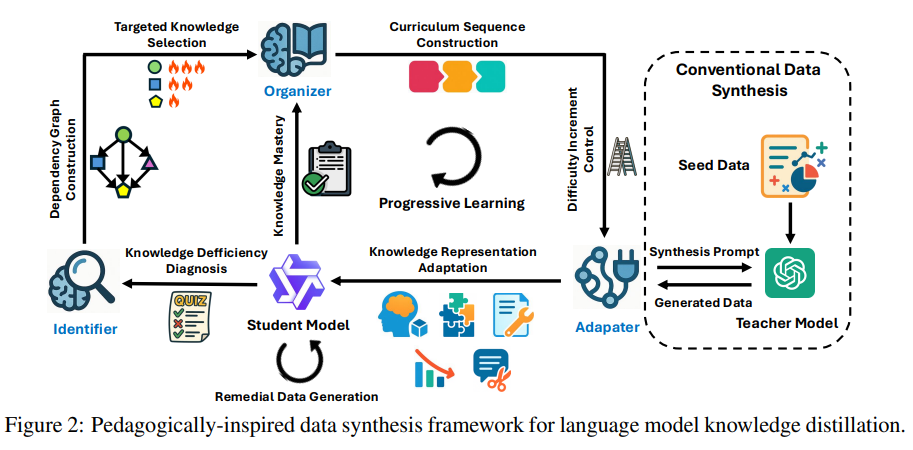
Adapter : Knowledge Representation Adaptation for Cognitive Alignment
Adapter 모듈은 Organizer가 구조화한 커리큘럼을 학생 모델의 학습 능력에 맞는 인지적으로 적절한 표현으로 변환하여 진정한 이해를 돕는다.
적응 목표
- 교사 모델에서 얻은 합성 데이터를 직접 사용하지 않고, 학생 모델의 인지 제약 조건에 맞게 콘텐츠 전달 방식을 체계적으로 수정한다.
- 현재 단계에서 예정된 지식 단위에 해당하는 의 하위 집합에 대해 적응을 수행한다.
다섯 가지 적응 관점
- 추상 개념 구체화 : 추상적인 수학 개념을 직관적인 표현(예: 자동차 속도 비유)으로 변환하여 개념을 정립한다.
- 복잡한 추론 분해 : 다단계 추론 과정을 정보 추출, 관계 식별, 공식화, 해결, 검증과 같은 원자적 인지 연산으로 분해한다.
- 인지 부하 관리 : 정보 밀도와 복잡성을 조절하여 SLM의 인지 제약에 맞춘다 (예: 2x2 정수 계수 시스템부터 시작).
- 표현 형식 최적화 : 템플릿화된 프레임워크와 구조화된 교육 형식을 사용하여 일관된 비계(scaffolding)를 제공한다.
- 언어 복잡성 감소 : 어휘, 구문, 담화 구조 전반에 걸쳐 내용을 체계적으로 단순화하고, 명확한 신호 단어("first", "therefore")를 통합한다.
전체 프레임워크 및 데이터 합성
통합 파이프라인
- IOA는 Identifier, Organizer, Adapter 모듈을 통합하여 구조화된 합성 데이터 생성을 통해 지식을 체계적으로 전달한다.
- 반복 주기 : 각 단계에서 학생 모델의 진행 상황에 따라 훈련 데이터를 지속적으로 조정한다.
단계별 프로세스
- 진단 및 타겟팅 (Identifier) : 성능 격차를 평가하고 가장 중요한 격차를 우선순위화한다.
- 커리큘럼 구성 (Organizer) : 선행 관계, ZPD, 숙달 요구 사항을 존중하는 진보적 커리큘럼을 구성한다.
- 데이터 생성 및 훈련 (Adapter) : 각 커리큘럼 단계에서 인지적으로 적절한 데이터를 생성하고, 숙달에 도달할 때까지 학생 모델을 훈련한다.
📈 Experiments
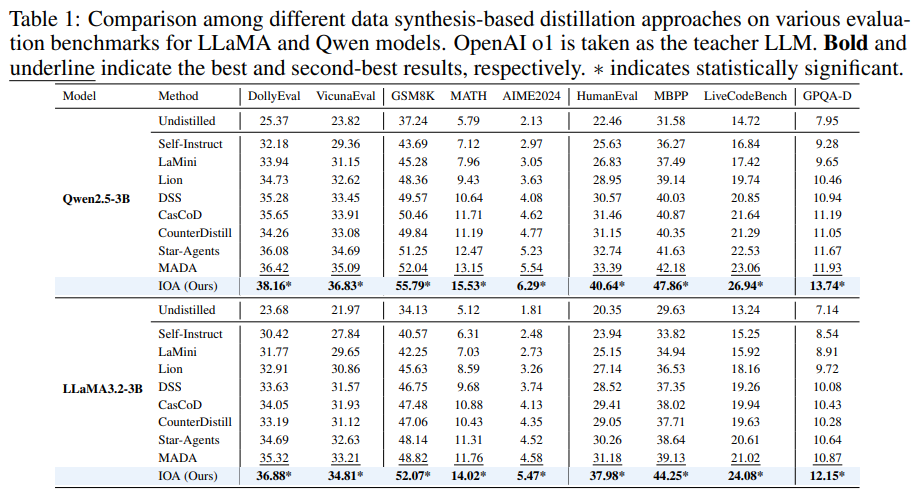
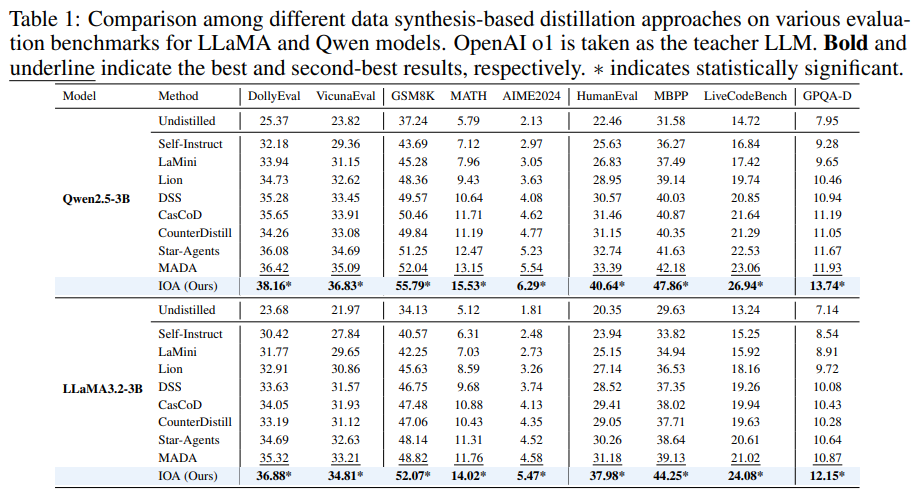
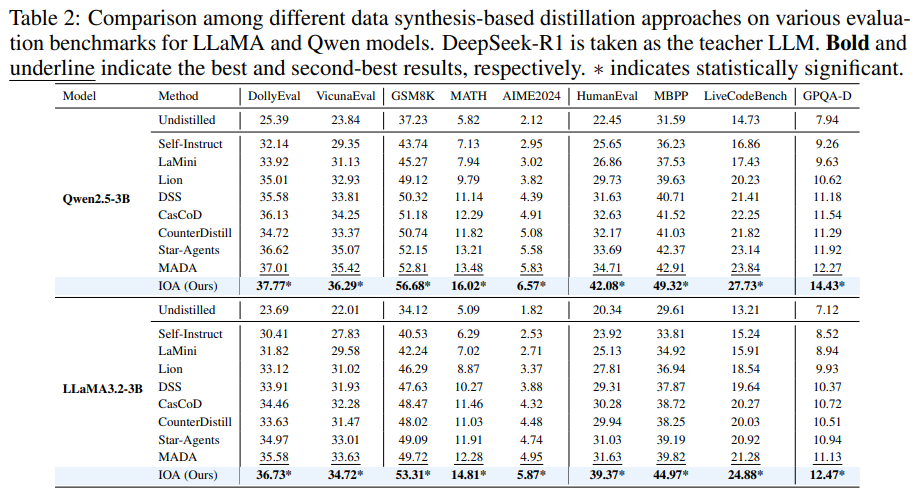
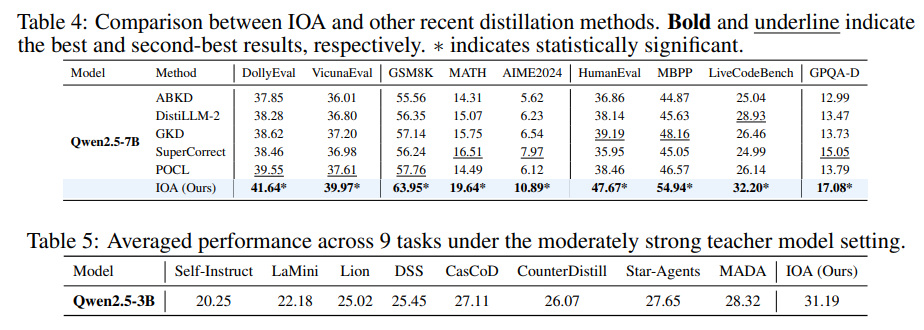
IOA 프레임워크는 다양한 학생 모델과 교사 모델에 걸쳐 기존의 데이터 합성 기반 증류 방법론들보다 일관되게 최고의 성능을 달성했으며, 특히 추론 및 코딩 작업에서 강점을 보였다.
실험 설정
| 분류 | 세부 내용 |
|---|---|
| 교사 및 학생 모델 | • 교사 모델: OpenAI o1, DeepSeek-R1 (보수적으로 100B 파라미터 이상 추정) • 학생 모델: Qwen2.5 (3B, 7B, 14B) 및 LLaMA3.1/3.2 (3B, 8B) |
| 평가 벤치마크 | • 지시 이행: DollyEval, VicunaEval • 추론: 수학 문제 해결 (GSM8K, MATH, AIME2024) • 코딩: HumanEval, MBPP, LiveCodeBench • 학술 지식 추론: GPQA-Diamond (GPQA-D) |
| 평가 지표 | • 지시 이행: ROUGE-L • 추론: Pass@k (k=1) |
| 비교 기준선 (Baselines) | • Vanilla Synthesis: Self-Instruct, LaMini • Adversarial Synthesis: Lion • CoT Synthesis: DSS, CasCoD • Counterfactual Synthesis: CounterDistill • Multi-Agent Synthesis: Star-Agents, MADA |
주요 결과 및 분석
전반적인 성능 비교
결론 : IOA는 지시 이행 및 추론 능력을 모두 효과적으로 전달하며, 특히 수학과 코딩에서 강력한 이점을 제공한다.
 |  |
|---|
Ablation Study
결론: 각 단계는 고유하게 긍정적으로 기여하며, 모든 구성 요소가 필수적이다.
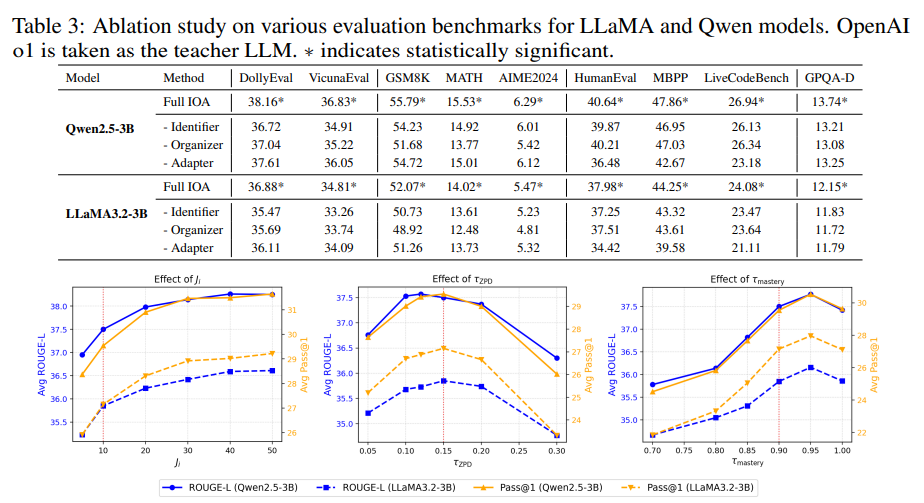
Hyperparameter Robustness
- (시드당 합성 데이터 양): 증가함에 따라 성능이 향상되다가 근처에서 정체되어 수확 체감 발생.
- (근접 발달 영역 임계값): 0.15 근처에서 정점을 찍는 비단조 추세를 보임 (너무 작으면 과소 도전, 너무 크면 단계 크기 초과).
- (숙달 임계값): 0.90–0.95 근처에서 정점을 찍으며, 너무 엄격하면 진행 속도가 느려짐.
- 결론: IOA는 기본 설정에서 강건하며 튜닝하기 쉽다.
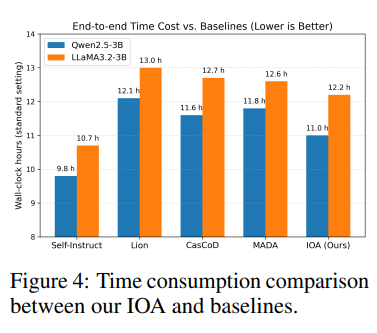
Time-Consumption Analysis
IOA는 Qwen2.5-3B에서 약 11.0시간, LLaMA3.2-3B에서 약 12.2시간이 소요된다. Lion이나 CasCoD보다 빠르거나 경쟁적이며, Self-Instruct보다는 느리지만 품질이 훨씬 우수하다.
효율성 요인
- Identifier가 지식 격차를 진단하여 합성 범위를 좁힌다.
- Organizer가 통제된 난이도 진행으로 불필요한 샘플 노출을 방지한다.
- Adapter가 구조화되고 단순화된 표현을 촉진하여 감독(supervision)을 압축한다.
추가 분석 및 결과
- 다른 증류 방법과의 비교
- ABKD, DistiLLM-2 (White-box), GKD (On-Policy Logit), SuperCorrect (RL-based), POCL (Curriculum-based)와 비교했다.
- IOA는 화이트박스 증류 및 온-폴리시/커리큘럼 기반 방법론에 대해서도 안정적으로 우위를 점했다.
- 중간 수준 교사 모델에서의 증류
- DeepSeek-R1-Distill-Qwen-7B를 교사로 사용했을 때도 IOA는 기준선 대비 일관된 개선을 제공했다.
- 시드 데이터 분석
- 품질 vs. 양 : 고품질 시드 데이터(3K 예제)를 사용했을 때 AIME2024에서 6.29점 대비 27.52점으로 크게 향상되었다.
- 결론 : 단순히 양을 늘리는 것보다 시드 품질(커버리지 및 분포)을 개선하는 것이 더 명확한 성능 이득을 가져온다.
✅ Conclusions and Future Works
IOA 프레임워크는 교육학적 원리를 활용하여 합성 데이터 생성을 구조화함으로써 LLM 지식 증류의 효율성과 효과를 크게 향상시켰다.
주요 기여
- IOA 프레임워크: 우선순위가 지정된 핵심 지식을 커리큘럼 구조화와 지식 표현 적응을 통해 점진적으로 전달한다.
- 효과 입증: 신중하게 설계된 합성 데이터가 LLM 증류의 효율성과 효과를 크게 향상시킬 수 있음을 광범위한 실험으로 입증했다.
향후 연구 방향
인지 과학 통찰력을 LLM에 통합하여 커리큘럼 설계에 대한 보다 체계적인 원칙을 수립할 계획이다.
📍 부록
IOA 메커니즘 요약
- Identifier ("무엇을 가르칠까"): 미세한 지식 격차를 진단하고 의존성 그래프를 구축하여 가장 중요한 격차를 목표로 한다.
( , , , ) - Organizer ("언제 가르칠까"): 의존성 그래프에 대한 위상적 커리큘럼을 구성하고, ZPD를 사용하여 난이도 증가를 제한한다.
( ). 숙달 전에는 다음 단계로 진행하지 않는다 ( ). - Adapter ("어떻게 가르칠까"): 구체화, 추론 분해, 인지 부하 관리, 템플릿 기반 형식, 언어 단순화를 통해 표현을 비계화한다.
교육학 원리가 증류를 개선하는 이유
인간의 학습과 신경망의 최적화 과정이 실질적으로 다름에도 불구하고 IOA의 교육학적 원칙들이 언어 모델 증류에 도움이 되는 이유는 무엇일까?
- 최적화 지형 재구성 : 커리큘럼 원리는 훈련 데이터 분포를 규제하여 경사도 분산 감소 및 수렴 안정성 향상에 기여한다.
- 난이도 제어 : 해결 불가능한 예제로 인한 경사도 지배를 방지하여 최적화 프로세스를 학습 가능한 영역에 유지한다.
- 숙달 임계값 : 선행 모듈 숙달 시에만 새 지식으로 진도: 표현 통합 촉진 및 간섭 감소.
- 구조화된 순서 : 의존성 그래프를 따르는 순서는 상충되는 경사도를 줄이고 파괴적 간섭을 감소시킨다.
- 적응형 표현 : 학생의 표현 능력에 맞게 데이터를 조정하여 더욱 정보력이 풍부한 경사도를 제공한다.
💡 Insight
이전에 수학 위계구조를 분석하여 직접 (1) 지식맵을 구축하고 (2) IRT와 지식추적을 활용하여 완전 학습이 달성되었는지 확인한 뒤 (3) 맞춤 학습 경로를 추천하는 코스웨어 개발을 진행한 적이 있습니다. 해당 프로젝트는 사람을 위한 지능형 튜터링 시스템(ITS), 이 논문은 AI 모델을 위한 ITS를 다룬다는 점에서 비슷하다고 느껴 흥미롭게 읽었습니다.
- 지식 위계구조 분석 & 지식맵 : 논문의 Identifier는 수학 도메인을 세부 지식 유닛(K)으로 쪼개고 의존성 그래프(Dependency Graph)를 그립니다. 이 과정은 지식맵 구축과 기술적으로 동일한 목적을 가집니다.
- IRT & 지식 추적 (Knowledge Tracing) : 논문의 Mastery Gating이 교사 모델 대비 90%( =0.9 )의 성능을 요구하는 로직은 IRT나 KT를 통해 학생의 이해도를 확률적으로 추정하고 다음 단계 진입 여부를 결정하는 '완전 학습' 판정 로직과 일치합니다.
- 맞춤 학습 경로 추천 : 논문의 Organizer는 위계 구조를 바탕으로 학습 시퀀스( )를 생성합니다. 이는 맞춤 학습 경로 추천을 한 코스웨어와 알고리즘적으로 유사합니다.
이러한 유사점으로 여러 가지 적용 방안이 떠올랐습니다.
- LLM 기반 적응형 비계(Adapter)
- 추상 개념 구체화 (Concretization) : 학생이 특정 개념(예: 미분)에서 계속 막힌다면 LLM이 실시간으로 그 학생이 좋아하는 분야(예: 자동차, 게임 등)에 비유해서 개념 설명을 새로 써서 보여주기. 학생의 관심사를 LLM 프롬프트에 반영하여 비유를 생성하면 논문에서도 지향하는 인지적 적합성(Cognitive Alignment)을 극대화할 것입니다.
- 언어적 단순화 (Linguistic Complexity Reduction) : 지식추적 결과 학생의 문해력이 낮다고 판단되면 LLM이 문제의 발문을 초등학생 수준으로 고쳐서(Linguistic Simplification) 제시하기.
- 데이터 기반 지식맵 검증
논문의 Dependency Strength 공식을 활용하여 "A를 마스터한 학생이 실제로 B 점수가 유의미하게 올랐는가?"를 프로젝트 데이터로 계산해 보면 직접 제작한 지식맵이 실제 학생들의 학습 데이터와 일치하는지 수치적으로 검증하고 수정하는 데 도움이 될 것입니다. - '근접 발달 영역(ZPD)' 기반의 진도 제어
논문에서 제안한 처럼 이전 단계의 평균 정답률 대비 다음 단계의 예상 난이도가 15% 이상 급격히 어려워지지 않도록 문제를 추천하는 알고리즘을 추가하면 학생의 '학습 포기'를 감소하기. 이는 학습자의 인지 부하 관리 (Cognitive Load Management) 측면에서도 효과적일 것입니다. - 실시간 보충 학습 생성 (Remedial Loop)
논문에서는 교사 모델 실력 대비 90% 달성을 하지 못하면 Remedial Data를 생성해 반복 학습 시킵니다. 기존 시스템은 "틀렸으니 다시 풀어봐" 수준이었다면, 학생이 틀린 문제의 오답 원인을 LLM이 분석하게 하고 그 원인을 해결하기 위해 가장 기초적인 단계로 돌아간 맞춤형 보충 문제를 실시간으로 생성하여 제공하는 생성형 보충 학습 루프 만들기. - 지식맵 자동 고도화
직접 구축했던 지식맵을 LLM을 활용해 더 세밀하게 쪼개거나 새로운 수학 도메인으로 확장할 때 논문의 Knowledge Hierarchy Generation 프롬프트를 활용해 자동화하기.
교육학을 전공하지 않은 연구진이 인간의 학습 원리를 모델 교육에 접목하려 고민한 흔적이 역력해 인상 깊게 다가왔습니다. 특히 이 논문은 본문만큼이나 절반 이상을 차지하는 방대한 부록이 재미있습니다. Case Study도 함께 살펴보시는 것을 추천 드립니다.
결국 모델을 학습시키는 과정도 인간을 교육하는 과정도 '어떻게 가르쳐야 잘 배울 수 있는가'라는 본질적인 질문에서 맞닿아 있음을 다시 한 번 확인했습니다. 이번 리뷰가 여러분께도 새로운 영감이 되었기를 바랍니다 🙌
