https://www.w3schools.com/python/python_regex.asp
✅ 메타 문자(Meta Character)
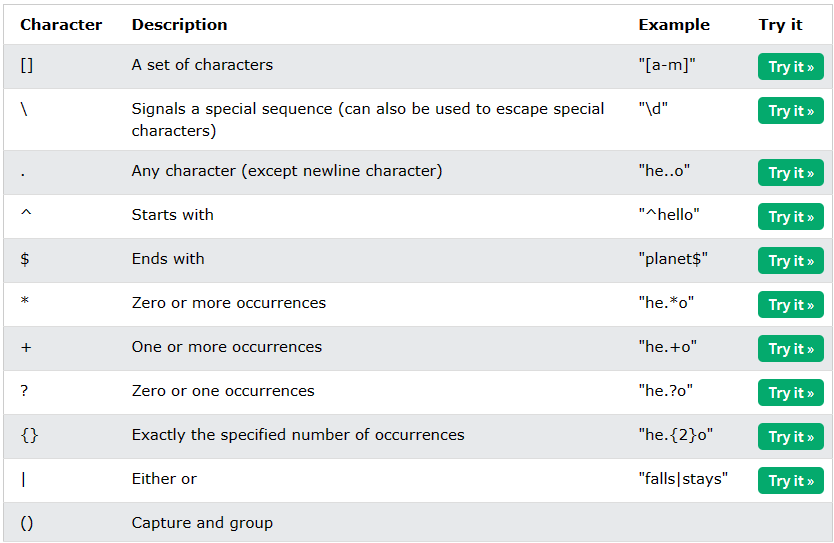
✅ 특수 시퀀스(Special Sequences)

✅ 정규식을 이용한 문자열 탐색

match와 search의 차이
주어진 문자열은 'defabc'이고, pattern은 'abc'이다. match는 문자열의 시작 부분부터 패턴과 일치하는 부분을 찾는데, 문자열의 시작 'def'는 'abc'와 일치하지 않으므로 일치하는 부분이 없다고 판단한다. 반면, search는 문자열 전체를 탐색하여 'abc'를 찾았으므로 이를 일치하는 부분으로 간주한다.
import re
# 정규식 패턴
pattern = 'abc'
# 주어진 문자열
text = 'defabc'
# match 사용 예시
match_result = re.match(pattern, text)
if match_result:
print("match 결과:", match_result.group())
else:
print("match 결과: 일치하는 부분이 없습니다.")
# search 사용 예시
search_result = re.search(pattern, text)
if search_result:
print("search 결과:", search_result.group())
else:
print("search 결과: 일치하는 부분이 없습니다.")
----
match 결과: 일치하는 부분이 없습니다.
search 결과: abc
✅ Python ReGex 연습 중 난이도 있었던 문제
Match
- 영문 대소문자 또는 숫자만 포함된 문장인지 검사하는 함수를 작성하라
def is_allowed_specific_char(string):
charRe = re.compile('[^a-zA-Z0-9]')
# 대괄호 안에 ^가 있으면 여집합, 일반적으로는 '시작'의 의미로 사용된다.
string = charRe.search(string)
return not bool(string) # 결과 전달 방식 주의, 한 번 더 꼬아 주었다.
print(is_allowed_specific_char("ABCDEFabcdef123450")) # True
print(is_allowed_specific_char("*&%@#!}{")) # False
print(is_allowed_specific_char("ABCDEFabcdef123450!")) # False- z가 포함된 단어를 포함하는지 검사
def text_match(text):
patterns = '\w*z.'
if re.search(patterns, text):
return 'Found a match!'
else:
return('Not matched!')
print(text_match("The quick brown fox jumps over the lazy dog.")) #T
print(text_match("Python Exercises joo.")) #F
print(text_match("Python Exercises z")) # F
# .\w*가 없으면 z가 포함된 게 아니라 z만 적어도 T가 된다.- 문자열이 단어로 끝나는지 검사(문자부호 _는 허용)
def text_match(text):
patterns = '\w+\S*$' # 정규식 패턴 작성 # *는 무슨 의미?
if re.search(patterns, text):
return 'Found a match!'
else:
return('Not matched!')
print(text_match("The quick brown fox jumps over the lazy dog.")) #T
print(text_match("The quick brown fox jumps over the lazy dog. ")) #F
print(text_match("The quick brown fox jumps over the lazy dog ")) #F- z가 포함된 단어를 포함하는지 검사
def text_match(text):
patterns = '\w*z.' # 정규식 패턴 작성
if re.search(patterns, text):
return 'Found a match!'
else:
return('Not matched!')
print(text_match("The quick brown fox jumps over the lazy dog.")) #T
print(text_match("Python Exercises joo.")) #F
print(text_match("Python Exercises z")) # .\w*가 없으면 z가 포함된 게 아니라 z만 적어도 T- z가 포함된 단어가 포함되어 있지만, 문자열의 끝 또는 마지막이 아닌 중간에 위치하는지 검사
def text_match(text):
patterns = '\Bz\B' # 정규식 패턴 작성
if re.search(patterns, text):
return 'Found a match!'
else:
return('Not matched!')
print(text_match("The quick brown fox jumps over the lazy dog.")) #T
print(text_match("Python Exercises zoo")) #F- 영문 대소문자, 숫자, 언더바만 포함하는지 검사
def text_match(text):
patterns = '^[a-zA-Z0-9_]*$' # 정규식 패턴 작성
if re.search(patterns, text):
return 'Found a match!'
else:
return('Not matched!')
print(text_match("The quick brown fox jumps over the lazy dog.")) #F
print(text_match("Python_Exercises_1")) #TSearch
문자열에서 특정 문자열들을 검색
- 문자열 : 'The quick brown fox jumps over the lazy dog.'
- 검색어 : 'fox', 'dog', 'horse'
patterns = [ 'fox', 'dog', 'horse' ]
text = 'The quick brown fox jumps over the lazy dog.'
for pattern in patterns:
print('Searching for "%s" in "%s" ->' % (pattern, text),)
if re.search(pattern, text):
print('Matched!')
else:
print('Not Matched!')Findall
- 문자열에서 특정 검색어를 모두 찾기.
문자열 : 'Python exercises, PHP exercises, C# exercises'
검색어 : 'exercises'
text = 'Python exercises, PHP exercises, C# exercises'
pattern = 'exercises'
for match in re.findall(pattern, text):
print('Found "%s"' % match)- URL에서 연, 월, 일을 추출하라
def extract_date(url):
return re.findall(r'/(\d{4})/(\d{2})/(\d{2})/', url) # 정규식 코드 작성
url1= "https://www.washingtonpost.com/news/football-insider/wp/2016/09/02/odell-beckhams-fame-rests-on-one-stupid-little-ball-josh-norman-tells-author/"
print(extract_date(url1))Finditer
- 문자열에서 특정 검색어를 모두 찾고, 등장 위치를 확인
text = 'Python exercises, PHP exercises, C# exercises'
pattern = 'exercises'
for match in re.finditer(pattern, text):
s = match.start()
e = match.end()
print('"%s"는 %d:%d 사이에 있다' % (text[s:e], s, e))Sub
- IP주소에서 선행 0(불필요한 0)을 제거
ip = "216.08.094.196" # ---> 216.8.94.196
string = re.sub('\.[0]*', '.', ip) # 정규식 패턴 작성
print(string)📖 참고
https://www.w3schools.com/python/python_regex.asp
https://wikidocs.net/4308

M.S. Student in Data Science @ Seoul National University