명령어 병렬 처리 기법
- 명령어 파이프라인
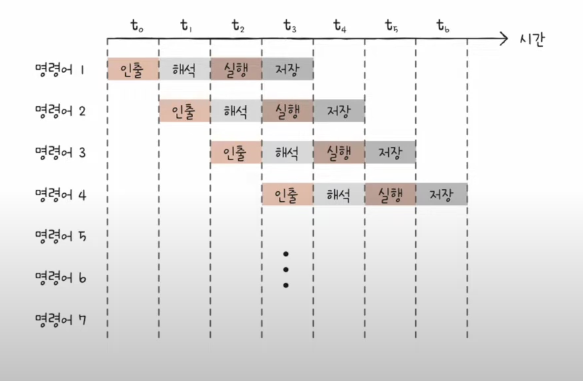
명령어 인출 -> 해석 -> 실행 -> 결과 저장
같은 단계가 겹치지만 않는다면 CPU는 각 단계를 동시에 실행할 수 있다.
파이프라인 위험
1. 데이터 위험

2. 제어 위험
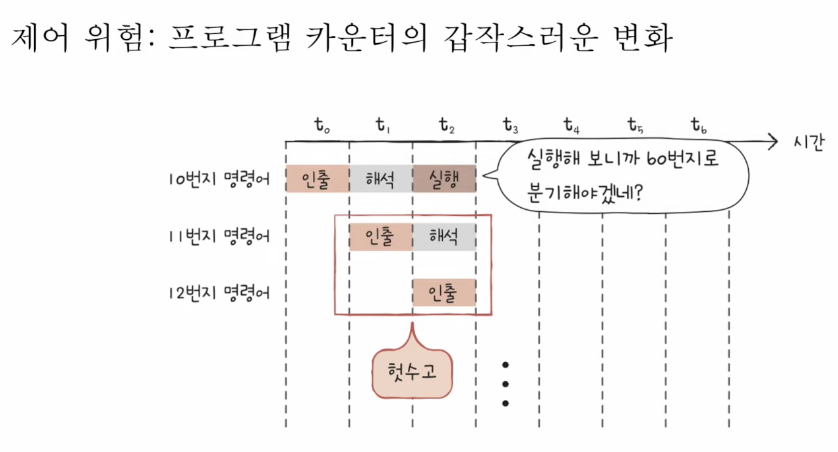
갑자기 jump 등의 분기 명령어를 실행하면 오류가 발생할 수 있다. 이를 분기 예측을 통해 해결한다.
3. 구조적 위험
서로 다른 명령어가 같은 ALU, 레지스터를 사용하려고 할때 발생한다.
슈퍼스칼라
CPU 내부에 여러 개의 명령어 파이프라인을 포함한 구조를 말한다.
이론 상 처리속도가 증가할 것 같지만, 실제로는 파이프라인 위험도 동일하게 증가하므로 병렬 명령어 파이프라인을 많이 추가한다고 해서 이에 비례하여 처리속도가 증가하지는 않는다.
- 비순차적 명령어 처리

파이프라인 중단을 방지하기 위해 명령어를 순차적으로 처리하지 않는 명령어 병렬 처리 기법을 이야기한다.
합법적인 새치기라고 생각해도 되겠다.
이는 명령어를 순차적으로 처리하지 않는다.


위의 사진과 같이 명령어의 실행 순서를 바꾸는 방식을 얘기한다.
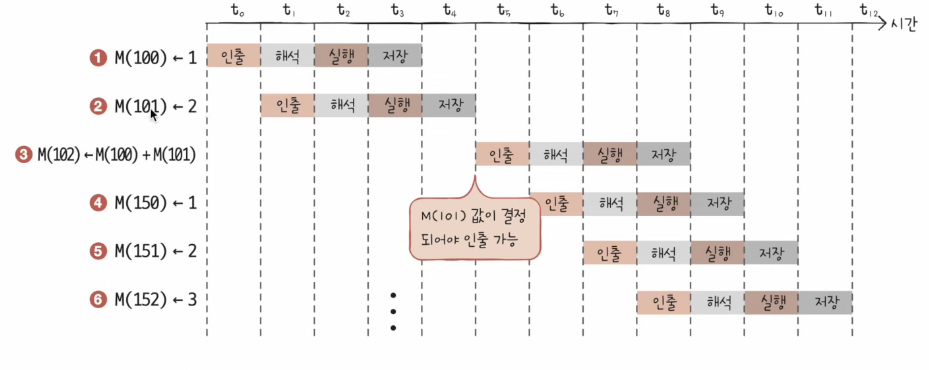
이유는 M(100) 과 M(101) 이 저장이 완료된 상태이어야 M(102) 에 ADD 연산을 실행할 수 있는데, 이를 순차적으로 실행하면 오류가 발생하기 때문이다.

실행 순서를 비순차적으로 변경할 시 오류없이 정상 실행이 가능하다.

그러나 아무 명령어나 순서를 바꿀 수 있는 것은 아니다. 서로 의존성이 없는 명령어들만 순서를 바꿀 수 있다.
명령어 집합구조 ISA (Instruction Set Architecture)
각 CPU 마다 명령어의 연산, 주소 지정 방식들은 상이하다.
인텔은 X86-64 명령어 집합
애플은 ARM 명령어 집합
을 대표적으로 따른다.
고로 같은 소스파일을 컴파일하더라도 생성되는 어셈블리어, 기계어 종류가 다르다.
또한 명령어 집합구조에 따라 CPU의 구조가 달라진다.
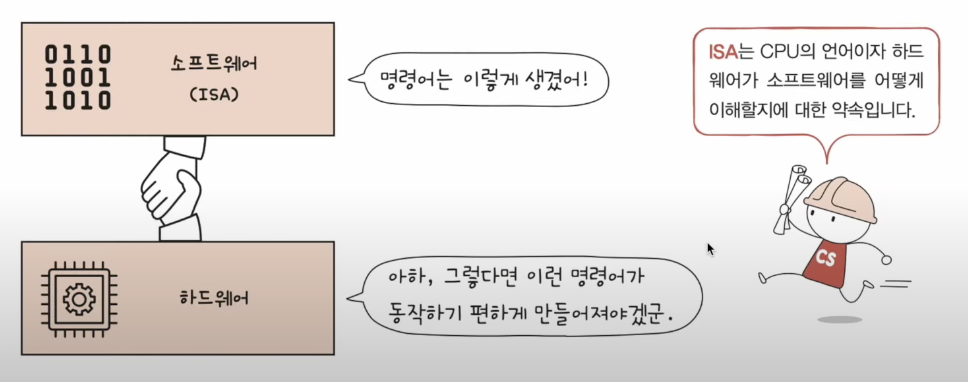
이는 하드웨어가 소프트웨어를 어떻게 이해할지에 대한 약속 이다.
CISC 와 RISC

- CISC (Complex Instruction Set Computer)
-
복잡한 명령어 집합을 활용하는 CPU 로 대표적인 명령어 집합구조는
X86-64아키텍쳐가 있다. -
메모리를 최대한 아끼며 개발해야 했던 시절에 인기가 높았다.
-
명령어의 형태와 크기가 다양하고, 가변길이 명령어를 사용한다.
고로 상대적으로 적은 수의 명령어로도 프로그램 실행이 가능하다.
그렇기에 명령어가 워낙 복잡하고 다양한 기능을 제공하는 탓에 명령어의 크기와 실행되기까지의 시간이 일정하지 않으며 복잡한 명령어 때문에 명령어 하나를 실행하는 데에 여러 클럭과 주기가 소모된다. -
이 때문에 명령어 파이프라이닝이 불리하다는 단점이 있다.
-
그러나 대다수의 복잡한 명령어는 사용빈도가 낮다.
- RISC (Reduced Instruction Set Computer)
-
명령어의 종류가 적고, 주기가 1클럭 정도로 짧고 규격화된 명령어를 사용한다.
-
단순하고 고정 길이 명령어 집합을 사용한다.
-
LOAD,STORE등 메모리 접근하는 명령어를 최소화화며레지스터를 십분 활용한다. -
CISC 에 비해 더 많은 명령어로 프로그램을 실행한다.
