인덱스
인덱스는 데이터베이스에서 특정 컬럼이나 컬럼들의 값을 기반으로 데이터를 빠르게 검색할 수 있도록 도와주는 자료구조이다. 마치 책 맨 뒷부분의 색인처럼, 인덱스를 통해 원하는 데이터를 신속하게 찾을 수 있다.
그럼 인덱스는 어떻게 데이터를 더 빠르게 찾을 수 있게 해주는 걸까?
원하는 데이터를 빠르게 찾기 위해서 데이터가 정렬되어 있어야 한다는 점에는 동의할 것이다.
가장 단순한 방법으로 이진 탐색 트리를 생각해볼 수 있다.
Binary Search Tree
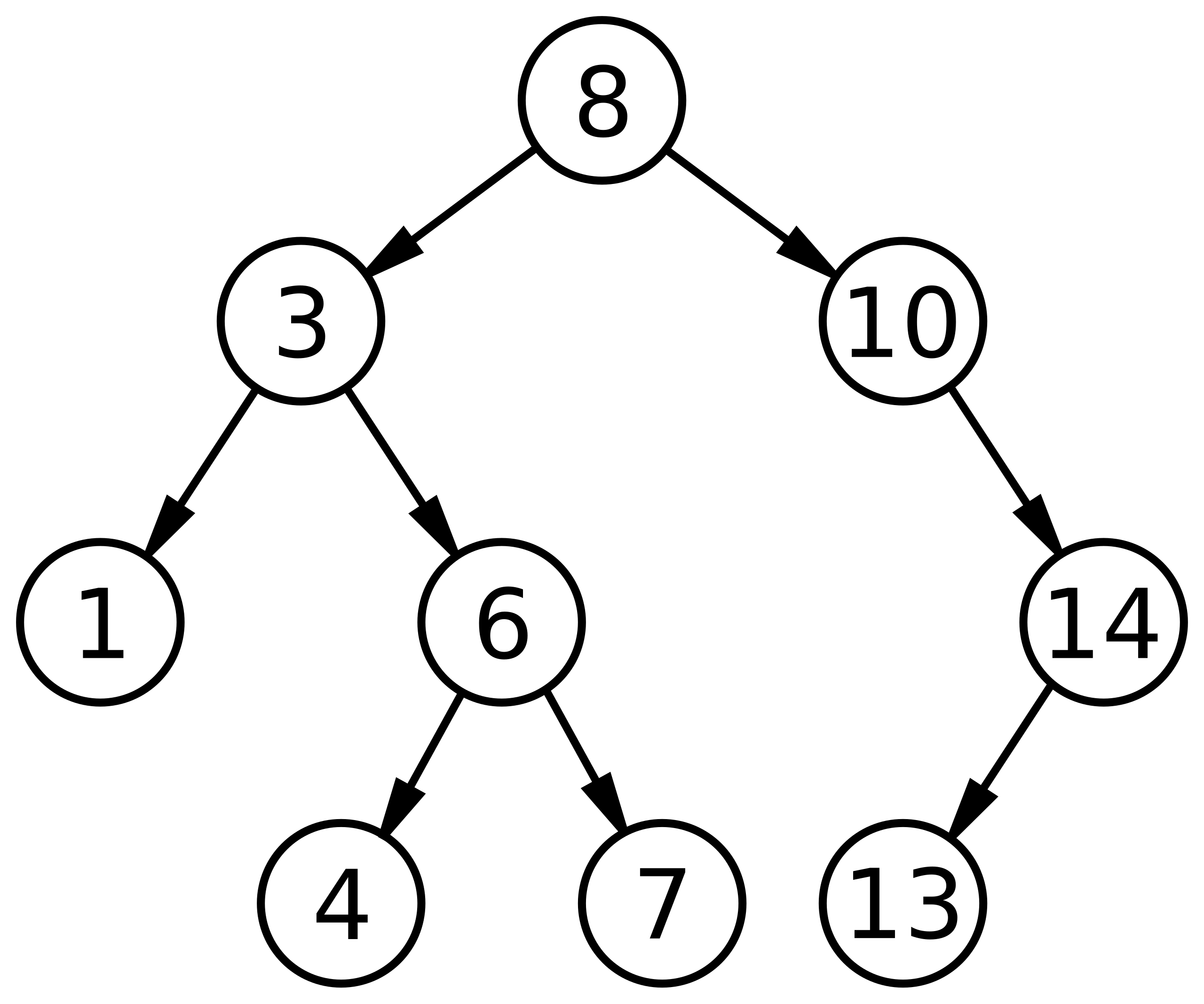
https://en.wikipedia.org/wiki/Binary_search_tree
이진 탐색 트리는 각 내부 노드의 키가 해당 노드의 왼쪽 서브 트리에 있는 모든 키보다 크고 오른쪽 서브 트리에 있는 키보다 작은 루트가 있는 구조이다.
기본적인 BST의 탐색 복잡도는 노드가 삽입되고 삭제되는 순서에 따라 달라진다. 최악의 경우, 정렬된 순서로 데이터를 삽입하면 한 방향에만 노드가 계속 연결되어 단일 연결 리스트와 같은 구조가 될 수 있다.
트리의 불균형 문제는 삽입, 삭제 후에 재조정 비용을 감수하고 트리의 균형을 맞추는 작업을 하게끔 Self-balancing 이진 탐색 트리로 만들어 해결할 수 있다.
이진 탐색 트리는 선형 탐색보단 낫지만, 디스크 기반의 데이터베이스에서 사용하기엔 아쉬운 점이 많다.
셀프 밸런싱 이진 탐색 트리(AVL, Red-Black Tree 등)는 메모리 상에서 잘 동작한다. 하지만 디스크는 메모리와 달리 느리기 때문에 지역성이 훨씬 중요해진다. (디스크 위치에 액세스하는 데 약 5ms = 5,000,000ns)
데이터베이스 환경에서는 좀더 디스크 I/O에 최적화된 자료구조가 필요하다.
한계점
노드에 하나의 키만 포함한다
이진 탐색 트리에서는 노드가 하나의 키만 갖고 있기 때문에, 트리의 높이가 계속 커지며 탐색할 때마다 각 노드를 하나씩 확인해야 한다. 예를 들어, 한 페이지에 수백 개 이상의 레코드가 있을 때, 여러 번의 디스크 I/O가 필요할 수 있다.
데이터를 모든 노드에 저장한다
데이터가 모든 노드에 분포되어 있어 순차적인 탐색이 필요한 범위 쿼리가 비효율적이다.
균형 유지 비용이 크다
셀프 밸런싱 이진 탐색 트리는 삽입, 삭제, 업데이트 시 트리 구조를 균형 있게 유지하기 위해 복잡한 재조정 작업을 수행한다. 이 과정에서 트리의 재조정에 많은 비용이 발생할 수 있다.
B-Tree
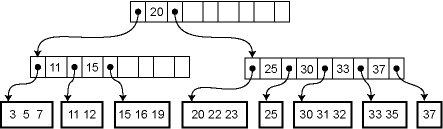
https://www.cs.cornell.edu/courses/cs3110/2012sp/recitations/rec25-B-trees/rec25.html
B-Tree는 디스크에 데이터 구조를 저장하기 위해 만들어졌다. 주로 대용량 데이터베이스나 파일 시스템에서 효율적인 검색, 삽입, 삭제 연산을 위해 사용된다.
이진 탐색 트리를 확장해 하나의 노드 2개 이상의 자식을 가질 수 있는 트리 구조이다.
- 내부 노드: 각 내부 노드는 ****N개의 키와 N+1개의 자식 노드를 가질 수 있다. 키와 데이터 포인터를 포함하며, 데이터 자체를 저장하기도 한다.
- 리프 노드: 리프 노드는 데이터를 저장하며, 자식 노드를 가지지 않는다.
이 구조를 통해 트리의 높이는 항상 균형을 이루므로 루트에서 모든 리프까지의 경로가 같아졌다.
장점
트리의 높이가 낮다
한 노드에 여러 키를 저장할 수 있어 트리의 높이가 낮다. 검색, 삽입, 삭제 연산이 O(log n) 시간 내에 이루어지고 데이터가 저장된 위치로 이동하는 데 필요한 디스크 읽기가 거의 없다.
디스크 I/O에 최적화되어 있다
노드 크기를 디스크 블록(페이지) 크기에 맞게 조정해 디스크 I/O를 최소화했다. 디스크 접근 시에 한 번에 여러 키를 읽어올 수 있어서 효율적인 캐시 사용이 가능하다.
한계점
범위 검색과 순차적 데이터 접근이 B+ Tree에 비해 비효율적이다
B-Tree에는 내부 노드, 리프 노드에 데이터가 존재할 수 있으며 데이터끼리의 연결이 없어 순차적으로 탐색하기 어렵다. 이를 개선한 것이 B+ Tree다.
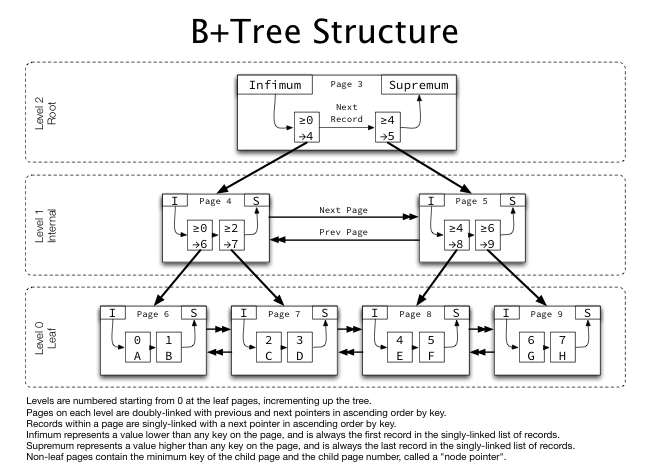
B+ Tree
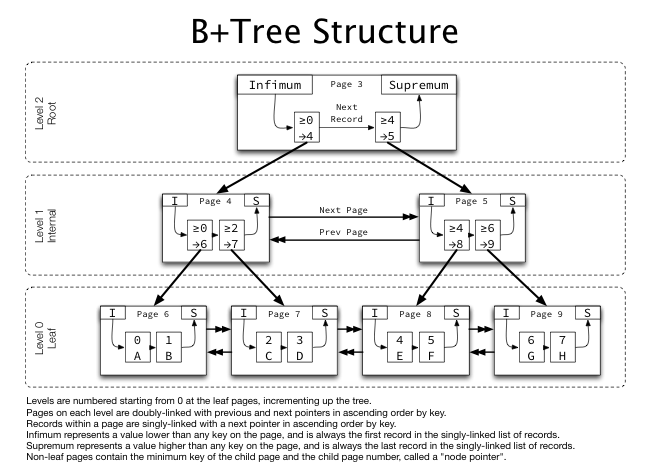
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
B+ Tree는 리프 노드에만 데이터를 저장하고, 리프 노드끼리 연결해 범위 검색을 효율적으로 개선했다.
InnoDB 스토리지 엔진의 인덱스도 B+ Tree 구조를 사용하고 있다.
B- Tree와의 차이점
- B-Tree는 모든 노드가 데이터와 포인터를 포함하지만, B+ Tree는 리프 노드만 데이터를 저장하고, 내부 노드는 키 값만 저장한다.
- B+ Tree는 리프 노드가 연결 리스트 형태로 되어 있어 범위 검색이 더 효율적이다.
어떤 자료 구조로 만들어야 효율적일 지 간단하게 알아보았다.
하지만 이렇게 데이터를 직접 정렬해 저장하니, 정렬의 기준이 되는 컬럼 외에 다른 컬럼으로 조회하면 결국 Full Scan이 일어난다.
특정 컬럼에 대한 검색을 효율적으로 만드려면, 그 컬럼에 대한 인덱스를 하나 더 만들어야 한다.
새로 만든 인덱스에 실제 데이터를 다시 저장하면 저장 공간이 낭비되고 데이터 변경을 어렵게 만들므로, 기본 인덱스의 프라이머리 키(리프 노드의 실제 데이터가 저장된 위치를 가리킨다)를 저장한다.
이 두 종류의 인덱스를 ‘실제 데이터가 클러스터화되어 있는지(인덱스 키 순서에 따라 물리적으로 정렬되어 있는지)’ 라는 의미에서 Clustered Index와 Non-clustered Index로 구분할 수 있다.
Clustered Index
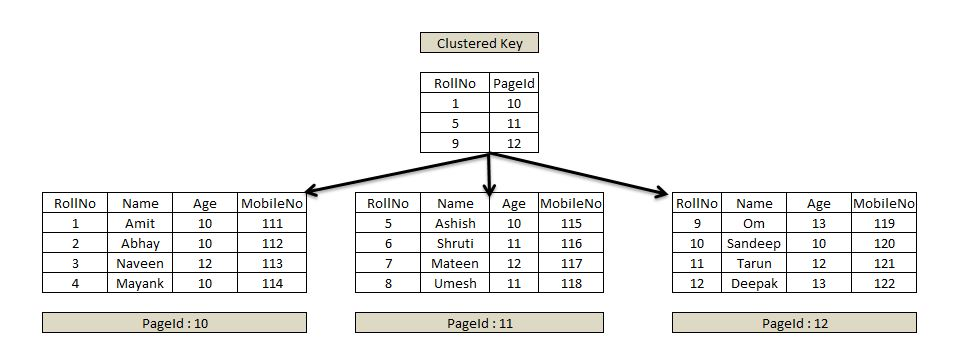
https://www.sqlservercentral.com/articles/nonclustered-index-structure
▲ 프라이머리 키 RollNo, Clustered Index
클러스터드 인덱스는 데이터 접근을 최적화하는 동시에 데이터의 물리적 저장 순서도 결정한다는 점에서 단순한 인덱스 이상의 개념으로, 데이터베이스의 기본적인 자료 구조라고 볼 수 있다.
클러스터드 인덱스는 기본적으로 프라이머리 키에 생성된다.
클러스터드 인덱스
- 데이터의 물리적인 정렬이 인덱스 키 순서에 따라 이루어진다
- 리프 노드에 실제 데이터가 저장된다
- 테이블당 하나의 클러스터드 인덱스만 존재할 수 있다
Non-clustered Index
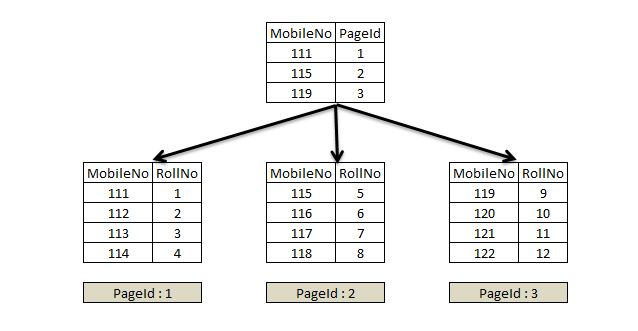
https://www.sqlservercentral.com/articles/nonclustered-index-structure
▲ 프라이머리 키가 아닌 MobileNo, unique한 Non-clustered Index
특정 컬럼에 대한 쿼리 성능을 향상시키기 위해 논클러스터드 인덱스를 만들 수 있다.
논클러스터드 인덱스를 실제 데이터를 저장하지 않고 클러스터드 인덱스의 PK를 가리키는 포인터를 저장한다. 이를 통해 인덱스를 탐색하고, PK를 이용해 실제 데이터를 빠르게 찾을 수 있다.
데이터가 논리적으로 정렬된 상태로 인덱스에 저장되므로 정렬된 데이터 검색이나 범위 쿼리에도 효율적이다.
논클러스터드 인덱스
- 인덱스의 리프 노드에 실제 데이터가 아닌 프라이머리 키 값이 저장된다
- 테이블에 여러 개의 논클러스터드 인덱스를 생성할 수 있다.
Non-clustered Index는 중복 값을 허용하는 컬럼(unique하지 않은 경우)에도 만들 수 있다.
먼저 컬럼 값이 유일한 (unique) 경우부터 살펴보자.
Unique Non-clustered Index
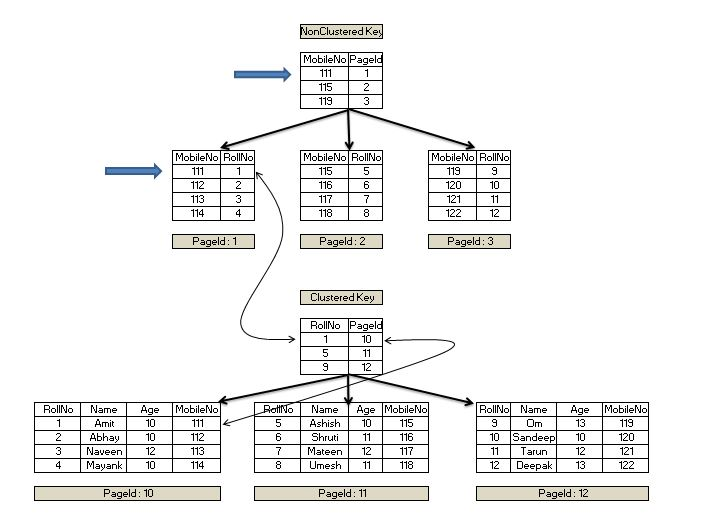
https://www.sqlservercentral.com/articles/nonclustered-index-structure
▲ Unique한 Non-clustered Index 시나리오 (MobileNo)
Non-clustered Index를 통해 쿼리가 동작하면, 일치하는 프라이머리 키를 찾는다. 찾은 프라이머리 키 값은 클러스터형 인덱스 키이므로 이 값으로 클러스터형 인덱스를 탐색해 값을 가져올 수 있다.
Non-unique Non-clustered Index
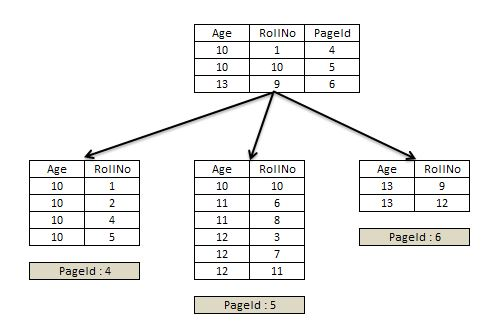
https://www.sqlservercentral.com/articles/nonclustered-index-structure
▲ Unique하지 않은 Non-clustered Index 시나리오 (Age)
논클러스터드 인덱스는 중복이 존재하는 컬럼에도 만들 수 있다.
이번에는 Unique할 때와 다르게 클러스터드 인덱스 키(RollNo)가 리프가 아닌 노드에도 생겼다.
논클러스터드 인덱스에서 중복된 값이 있을 땐, 해당 값들의 클러스터드 인덱스 키 순서대로 저장한다.
- 리프 노드가 아닌 노드에도 클러스터드 인덱스 키를 저장하는 이유 리프 노드에만 클러스터드 클러스터드 인덱스 키가 있다면?
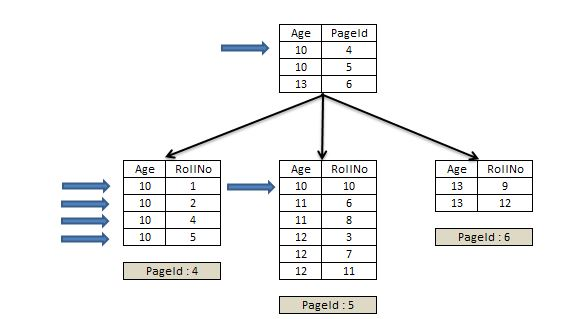 https://www.sqlservercentral.com/articles/nonclustered-index-structure
https://www.sqlservercentral.com/articles/nonclustered-index-structure
만약 클러스터드 인덱스 키가 중간 노드에 없다면, 클러스터드 인덱스 키의 순서로 정렬되어 있음에도 쿼리를 실행하기 위해 여러 페이지를 찾아야 한다. 큰 테이블의 경우, 이 작업으로 많은 낭비가 생긴다. 리프 노드가 아닌 노드 클러스터드 인덱스 키가 있는 경우update dbo.class set age = 12 where age = 10 AND rollno = 10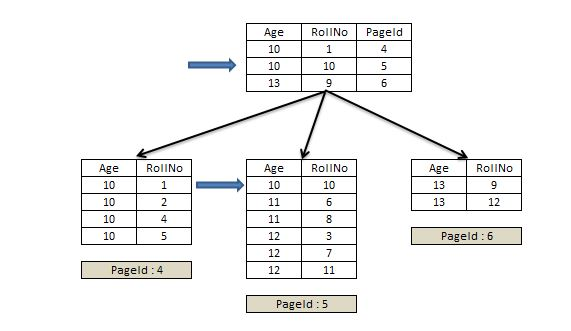 https://www.sqlservercentral.com/articles/nonclustered-index-structure
https://www.sqlservercentral.com/articles/nonclustered-index-structure
이렇게 하면 찾으려는 데이터가 있는 페이지에 한번에 접근할 수 있다.
인덱스 사용해보기
테이블 생성
-- 테이블 생성
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL
);AUTO INCREMENT되는 PK order_id 외엔 모두 중복이 가능하다.
데이터 삽입
-- 데이터 삽입
insert into orders values(1, 1, '2021-01-01', 10000),
(2, 2, '2021-01-02', 20000),
(3, 3, '2021-01-03', 30000),
(4, 4, '2021-01-04', 40000),
(5, 5, '2021-01-05', 50000);
insert into orders(customer_id, order_date, total_amount)
select FLOOR(RAND()*10000), now(), FLOOR(RAND()*10000) from orders;520만개 정도의 더미 데이터를 생성해 삽입했다.
PK에 생성되는 인덱스 확인
SHOW INDEX FROM orders;+------+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name|Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+------+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|orders|0 |PRIMARY |1 |order_id |A |20240 |null |null | |BTREE | | |YES |null |
+------+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
PK order_id 를 통해 기본적으로 생성되는 인덱스를 확인할 수 있다.
EXPLAIN SELECT로 조회에 인덱스를 사용하는지 확인
EXPLAIN SELECT * FROM orders WHERE customer_id = 5000;+--+-----------+------+----------+----+-------------+----+-------+----+-------+--------+-----------+
|id|select_type|table |partitions|type|possible_keys|key |key_len|ref |rows |filtered|Extra |
+--+-----------+------+----------+----+-------------+----+-------+----+-------+--------+-----------+
|1 |SIMPLE |orders|null |ALL |null |null|null |null|5231600|10 |Using where|
+--+-----------+------+----------+----+-------------+----+-------+----+-------+--------+-----------+type이 ALL(full scan)이다.
인덱스 적용 전 조회 속도
500 rows retrieved starting from 1 in 1 s 517 ms (execution: 1 s 246 ms, fetching: 271 ms)
500 rows retrieved starting from 1 in 1 s 364 ms (execution: 932 ms, fetching: 432 ms)
500 rows retrieved starting from 1 in 1 s 311 ms (execution: 1 s 3 ms, fetching: 308 ms)
500 rows retrieved starting from 1 in 1 s 60 ms (execution: 914 ms, fetching: 146 ms)인덱스 생성
CREATE INDEX idx_customer_id ON orders (customer_id);+------+----------+---------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+------+----------+---------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|orders|0 |PRIMARY |1 |order_id |A |20240 |null |null | |BTREE | | |YES |null |
|orders|1 |idx_customer_id|1 |customer_id|A |11551 |null |null | |BTREE | | |YES |null |
+------+----------+---------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+EXPLAIN SELECT로 조회에 인덱스를 사용하는지 확인
EXPLAIN SELECT * FROM orders WHERE customer_id = 5000;+--+-----------+------+----------+----+---------------+---------------+-------+-----+----+--------+-----+
|id|select_type|table |partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra|
+--+-----------+------+----------+----+---------------+---------------+-------+-----+----+--------+-----+
|1 |SIMPLE |orders|null |ref |idx_customer_id|idx_customer_id|4 |const|538 |100 |null |
+--+-----------+------+----------+----+---------------+---------------+-------+-----+----+--------+-----+인덱스 적용 조회 속도
500 rows retrieved starting from 1 in 264 ms (execution: 72 ms, fetching: 192 ms)
500 rows retrieved starting from 1 in 327 ms (execution: 7 ms, fetching: 320 ms)
500 rows retrieved starting from 1 in 173 ms (execution: 5 ms, fetching: 168 ms)
500 rows retrieved starting from 1 in 143 ms (execution: 9 ms, fetching: 134 ms)언제, 어디에 인덱스를 사용하는 게 좋을까?
- 데이터의 중복도가 낮은 컬럼
- 조회가 INSERT, UPDATE, DELETE 보다 자주 발생하거나 더 중요할 때
- JOIN, WHERE, ORDER BY에 자주 사용되는 컬럼
추가
- LIKE로 문자열 일부 등을 검색할 때 INDEX - full text index, …
