1. 파이썬의 자료형
- 리스트 초기화하기!
n = 5
a = [0] * n
print(a) # [0, 0, 0, 0, 0]- 2차원 리스트 초기화하기!
array = [[0] * m for _ in range(n)]- 리스트 관련 메소드
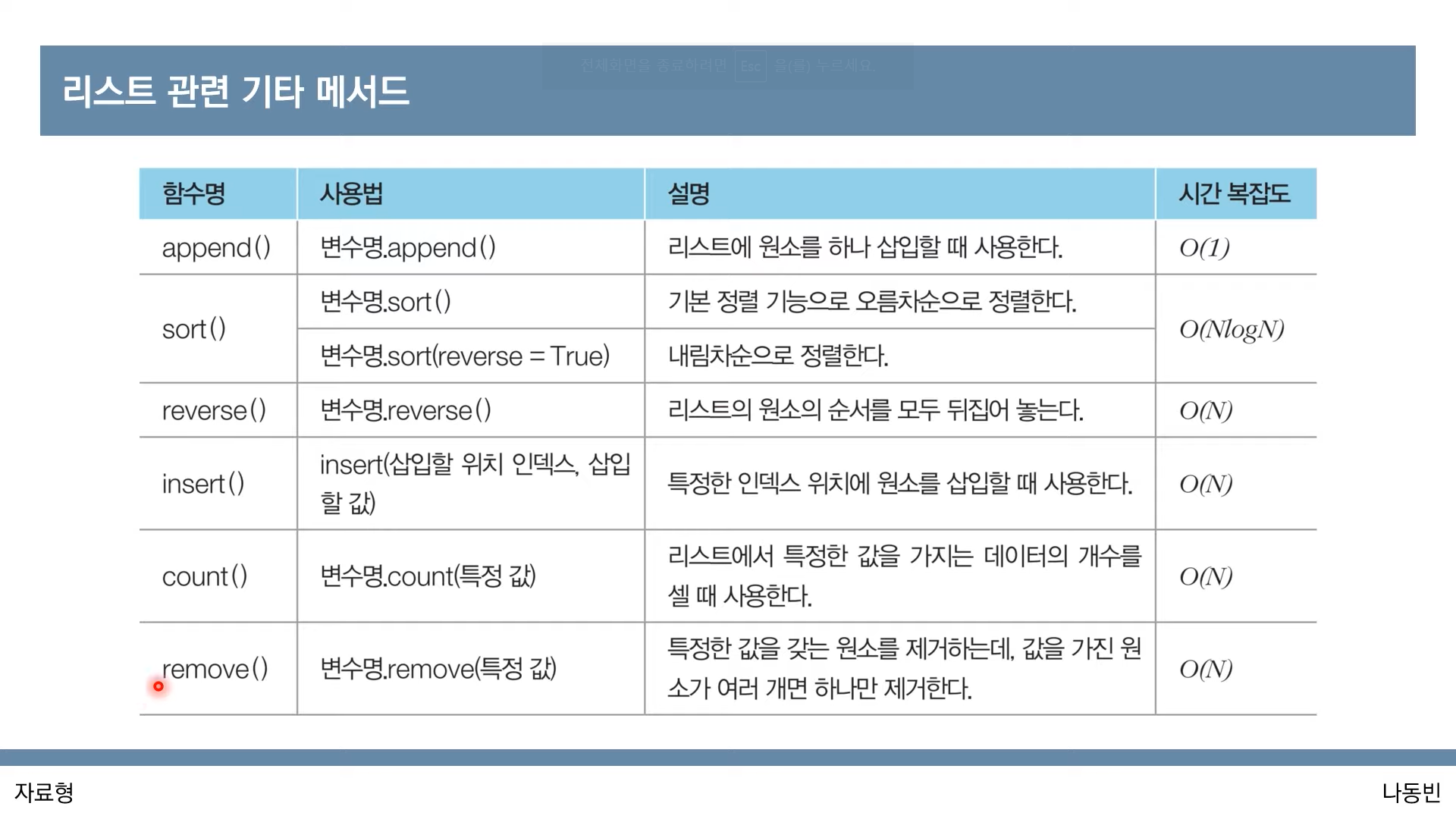
[출처: 동빈나 youtube (이코테 2021)]
- remove / del / pop 차이
remove 는 첫 번째 일치 값을 제거합니다.
a = [0, 2, 3, 2]
a.remove(2)del 은 특정 인덱스에서 항목을 제거합니다.
a = [9, 8, 7, 6]
del a[1]pop 은 특정 인덱스에서 항목을 제거하고 반환합니다.
a = [4, 3, 5]
a.pop(1) # 3-
튜플 자료형
: 서로 다른 성질의 데이터를 묶어서 관리해야 할 때 사용 가능하다
ex. 최단 경로 알고리즘에서 (비용, 노드번호)의 형태, 해싱의 키 값 -
사전 자료형
: 키와 값의 쌍을 데이터로 가지는 자료형- 키 데이터만 뽑고 싶은 경우, keys() 함수 이용
- 값 데이터만 뽑고 싶은 경우, values() 함수 이용
# 선언 및 정의
data = dict()
data['사과'] ='apple'
data['바나나'] = 'banana'
# method 사용
key_list = data.keys()
value_list = data.values()
# 키에 따른 값 출력
for key in key_list:
print(data[key])
# 데이터 기준으로 정렬하고플때
dic1 = sorted(dic.items(), key=lambda x : x[1])
- 집합 자료형
: 중복을 허용하지 않고, 순서가 없는 자료형, set()함수를 이용- 합집합(|), 교집합(&), 차집합(-)
a = set([1, 2, 3, 4, 5])
b = set([3, 4, 5, 6, 7])
# 합집합
print(a | b)
# 교집합
print(a & b)
# 차집합
print(a - b)
# 원소 추가
a.add(9)
# 여러 원소 추가
a.updata([7, 8])
# 원소 삭제
a.remove(8)2. 파이썬의 입출력
- 일반적인 소스 코드
n = int(input())
# 리스트로 받을때
data = list(map(int, input().split()))
data.sort(reverse=True)
# 변수로 받을때
a, b, c = map(int, input.split())- 입력
# 일반적인 입력
data1 = input()
# 빠른 입력
data2 = sys.stdin.readline().rstrip()- 출력
# 일반적인 출력
print(a, b)
# 줄바꿈을 하지 않을 경우
print(a, end=" ")
# 분자열로 출력
print("정답은" + str(a) + "입니다.")3. 함수
- 람다 함수
array = [('홍길동', 50), ('이순신', 32), ('아무개', 75)]
def my_key(x):
return x[1]
print(sorted(array, key=my_key))
print(sorted(array, key=lambda x: x[1]), reverse=True)4. 라이브러리
- 순열
: 서로 다른 n개에서서로 다른 r개를 선택하여 일렬로 나열하는 것
from itertools import permutations
data = ['A', 'B', 'C']
result = list(permutations(data, 3))
print(result)
# [('A', 'B', 'C'),('A', 'C', 'B'),('B', 'A', 'C'),('B', 'C', 'A'),('C', 'A', 'B'),('C', 'B', 'A')]- 조합
: 서로 다른 n개에서 순서에 상관없이 서로 다른 r개를 선택하는 것
from itertools import combinations
data = ['A', 'B', 'C']
result = list(combinations(data, 2))
print(result)
# [('A', 'B'),('A', 'C'),('B', 'C')]- 카운터
: 내부의 원소가 몇번씩 등장했는지를 알려줌
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'blue'])
print(counter['blue']) #2
print(counter['green']) #2
print(dict(counter)) #{'red': 2, 'blue': 2}- 최대공약수와 최소공배수
import math
def lcm(a, b):
return a*b / math.gcd(a,b)
a = 21
b = 14
print(math.gcd(a, b))
print(lcm(a, b))5. 꾸르팁
- nonlocal : 전역변수를 포함한 상위 스코프의 이름을 사용
