Numpy를 사용하는 이유
Numpy: Numerical computing with Python. 수치연산 및 벡터 연산에 최적화된 라이브러리
Numpy
- 2005년에 만들어졌으며, 100%오픈소스입니다.
- 최적화된 C code로 구현되어 있어 엄청나게 좋은 성능을 보입니다.
- 파이썬과 다르게 수치 연산의 안정성이 보장되어 있습니다.
- N차원 실수값 연산에 최적화 되어 있습니다. == N개의 실수로 이루어진 벡터 연산에 최적화 되 어있습니다.
Numpy를 사용해야 하는 이유
- 데이터는 벡터로 표현됩니다. 데이터 분석이란 벡터 연산입니다. 그러므로 벡터연산을 잘 해야 데이터 분석을 잘할 수 있습니다.
- 파이썬은 수치 연산에 매우 약합니다. 실수값 연산에 오류가 생기면 원하는 결과를 얻지 못할 수 있습니다. 많은 실수 연산이 요구되는 머신러닝에서 성능 저하로 이어질 수 있습니다.
- numpy는 벡터 연산을 빠르게 처리하는 것에 최적화되어 있습니다. 파이썬 리스트로 구현 했을 때보다 훨씬 더 높은 속도를 보여줍니다.
Numpy array
Numpy array : numpy에서 사용되는 기본적인 자료구조
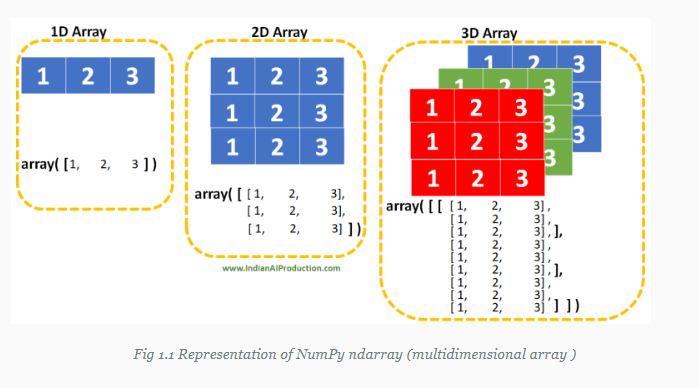
Numpy와 파이썬 리스트는 비슷한 구조이지만 세부적인 특징이 다릅니다.
<다른점>
1. 선언한 이후에 크기 변경이 불가능 합니다.
2. 모든 원소의 데이터 타입이 동일해야 합니다.(Numpy는 모든 원소의 데이터 타입이 동일 하기 때문에 벡터 연산을 빠르게 처리하는 것에 최적화가 잘 되어 있습니다.)
<같은점>
1. indexing으로 원소를 접근할 수 있습니다.
2. 생성 후 assignment operator를 이용해서 원소의 update가 가능합니다.
numpy가 제공하는 데이터 타입은 파이썬과 다릅니다.
- 수치와 관련된 데이터 타입이 대부분입니다.
- 원소의 크기(memory size)를 조절할 수 있으며, 크기에 따라 표현할 수 있는 수치 범위가 정해집니다.
- 예를 들면 np.int8 -> 수치 표현에 8bits를 사용한다 -> 00000000~11111111 -> 2^8(256개) -> -128~127
- np.float32 -> 실수 표현에 32bits를 사용한다 -> exponent, mantissa, sign-> single precision

시간을 아끼자