PNP AI 공부(1)
01-1 인공지능과 머신러닝, 딥러닝
인공지능 : 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
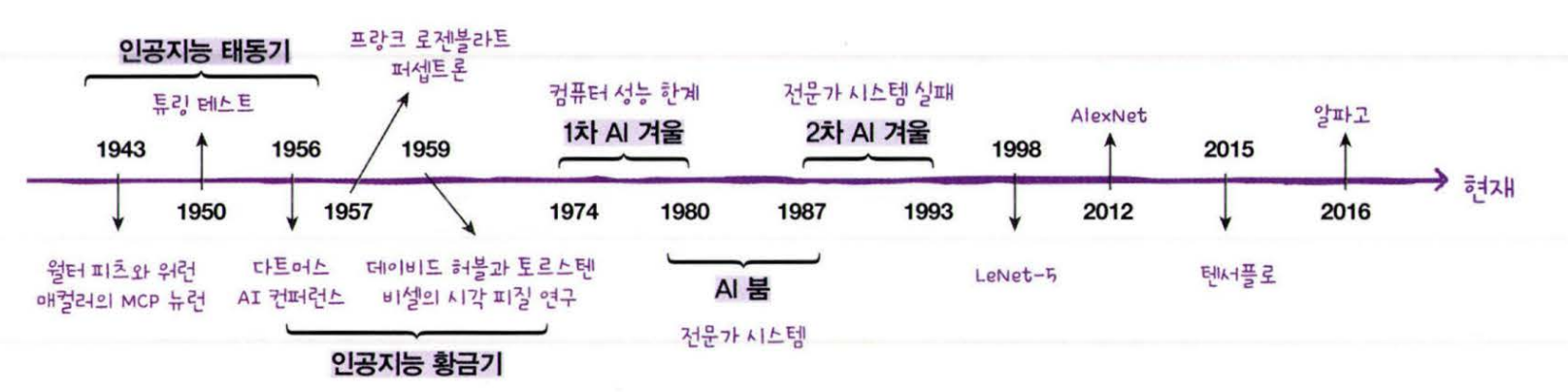
인공지능의 역사
강인공지능(인공일반지능) : 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템
예시 : <그녀>에 나왔던 사만다
약인공지능 : 특정 분야에서 사람의 일을 도와주는 보조 역할을 하는 컴퓨터 시스템
예시 : 알파고
머신러닝 : 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야, 인공지능 하위 분야
사이킷런(scikit-learn) : 컴퓨터 과학 분야의 대표적인 머신러닝 라이브러리로, 파이썬 API를 사용
딥러닝 : 머신러닝 알고리즘 중에 인공 신경망을 기반으로 한 방법
<예시>
LeNet-5 : 1998년 손글씨 숫자를 인식하는 신경망 모델이며 최초의 합성곱 신경망
AlexNet : 이미지 분류 작업을 하는 모델로, 합성곱 신경망 사용
<딥러닝 라이브러리>
텐서플로 : 구글 딥러닝 라이브러리
파이토치 : 페이스북 딥러닝 라이브러리
01-2 코랩과 주피터 노트북
구글 코랩 : 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스
텍스트 셀 수정 : Enter 또는 마우스 더블 클릭
텍스트 셀 수정 끝 :ESC
텍스트 셀에서는 HTML과 마크다운을 혼용해서 사용할 수 있다.
TT : 현재 라인을 제목으로 바꾼다.
B : 굵은 글자로 바꾼다.
I : 이탤릭체로 바꾼다.
<> : 코드 형식으로 바꾼다.
(-) : 선택한 글자를 링크로 만든다.

코드 셀 실행 : Ctrl + Enter 또는 플레이 아이콘
실행 및 새로운 셀 생성 : Alt + Enter
밑에 있는 셀로 내려가기 : Shift + Enter
- 새 노트북 만들기
[파일 - 새 노트] 클릭
코드 셀에 코드 작성, 실행
자동으로 구글 드라이브의 [내 드라이브] - [Colab Notebooks]폴더 아래에 저장
- 저장된 노트북 코랩으로 불러오기
- 노트북 화면 [파일] - [노트 열기]
팝업 창에서 [Google 드라이브]선택
[Colab Notebooks]에 들어간 노트북 열기- 구글 드라이브에서 코랩 노트북 선택
마우스 오른쪽 버튼 클릭
[연결 앱]-[Google Colaboratory]선택
텍스트 셀에 사용할 수 있는 마크다운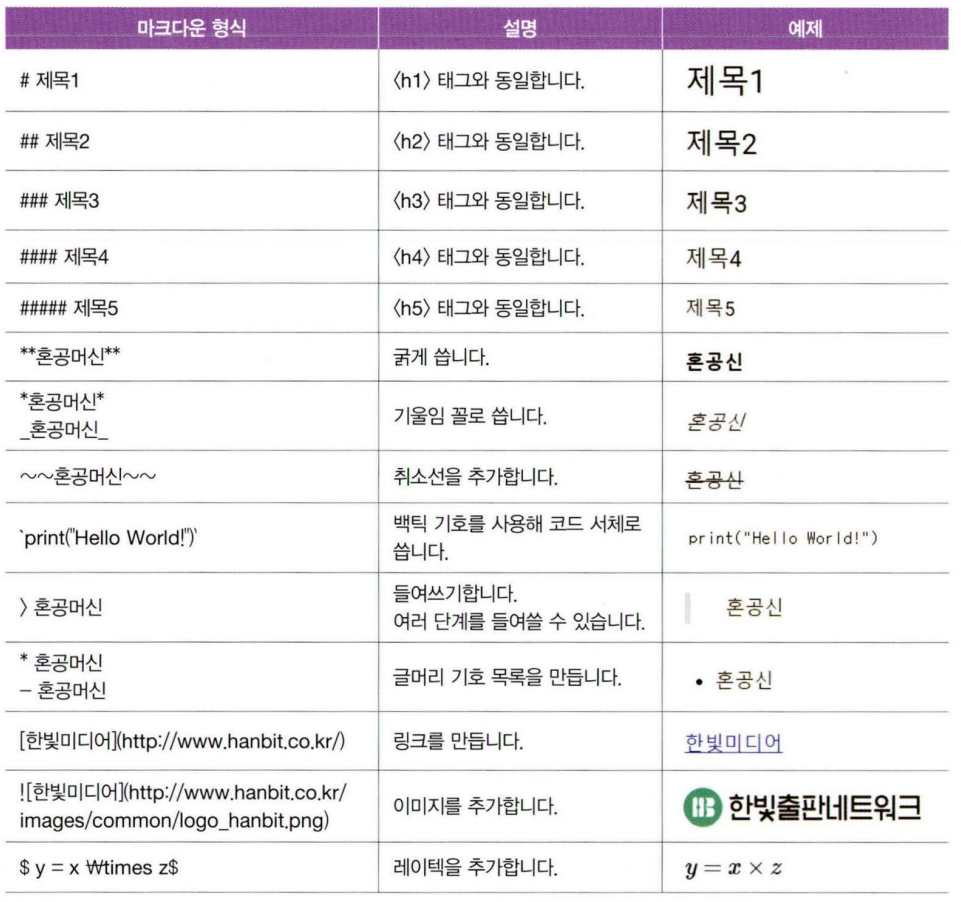
01-3마켓과 머신러닝
- 전통적인 프로그램

- 머신러닝은 누구도 알려주지 않는 기준을 찾아서 일을 하고 머신러닝에서 여러 개의 종류(클래스)중 하나를 구별해 내는 문제를 분류라고 한다.
- 2개의 클래스 중 하나를 고르는 문제를 이진 분류라고 한다.
- 데이터의 특징을 특성이라고 한다.
- 맷플롯립 : 파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지
 도미와 빙어 데이터를 준비한다.
도미와 빙어 데이터를 준비한다.
 pyplot함수를 불러와 scatter함수에 매개변수로 도미와 빙어의 길이와 무게를 전달한다.
pyplot함수를 불러와 scatter함수에 매개변수로 도미와 빙어의 길이와 무게를 전달한다.
x축의 이름과 y축의 이름을 지정해주고 show()함수를 사용해 출력한다.
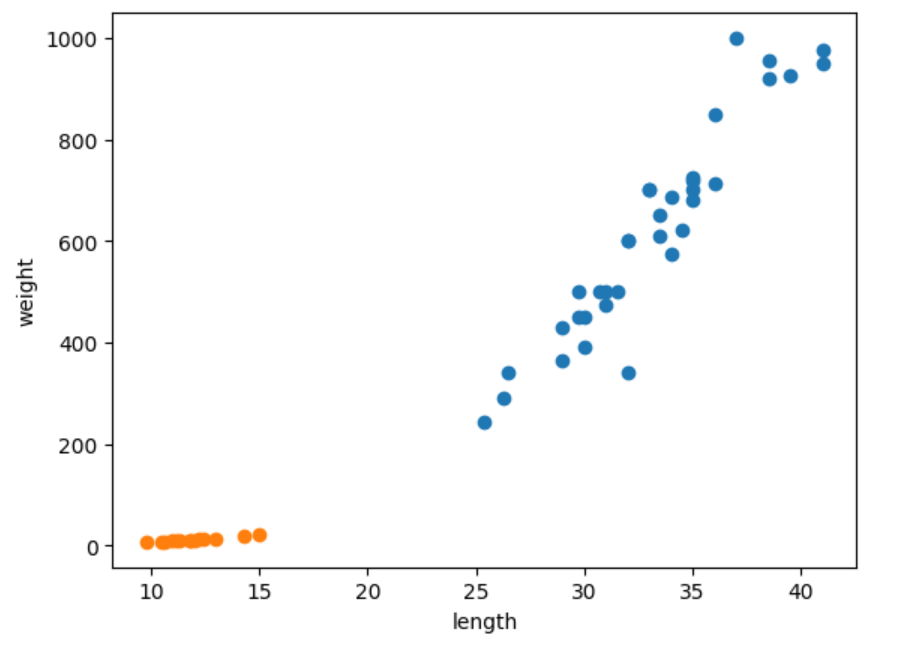 그래프가 일직선에 가까운 형태로 나타나는 경우 선형적이라고 한다.
그래프가 일직선에 가까운 형태로 나타나는 경우 선형적이라고 한다.

도미와 송어의 길이와 무게를 각각 새로운 리스트에 넣어준다. fish_data라는 새로운 리스트를 생성한다.
zip함수를 사용해 length와 weight의 원소들을 각각 하나씩 l과 w에 대입하여 원소가 l과 w인 2차원 리스트를 만든다.
fish_target라는 정답 리스트를 만든다. 여기서 찾고자 하는 값을 1, 아닌 것을 0으로 둔다.
KNeighborsClassifier함수를 불러온 뒤, fit함수를 사용해 fish_data와 fish_target을 가지고 훈련을 한다.
score함수로 정확도를 출력한다.
zip : 각각의 리스트의 원소들을 하나씩 짝을 지어주는 함수
scatter : 산점도 만드는 함수
fit : 데이터로 훈련하는 함수
score : 정확도를 출력하는 함수

scatter함수로 길이 30, 무게 600인 샘플을 산점도에 넣는다.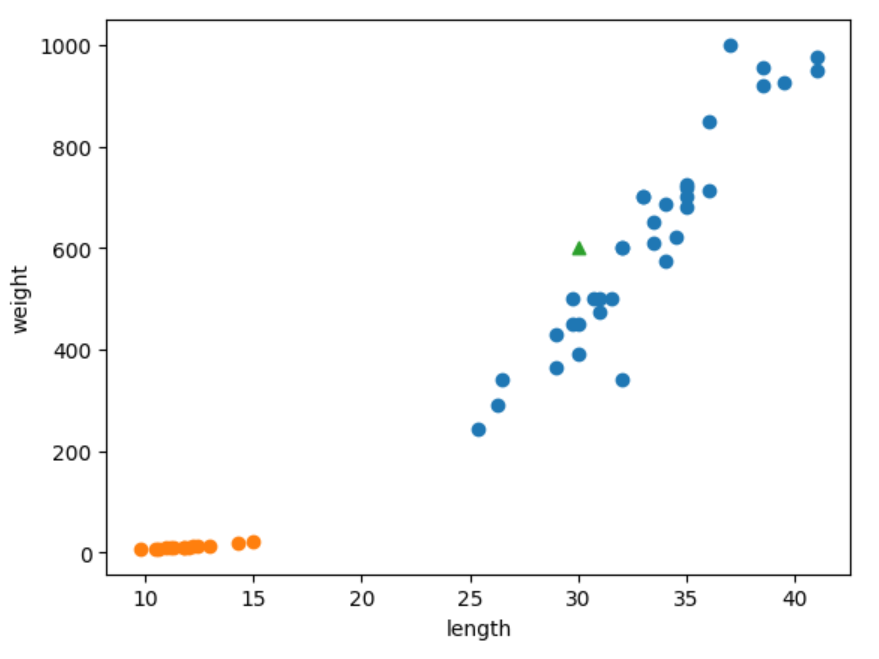
 predict함수로 길이 30, 무게 600인 샘플이 무엇인지를 출력하게 해준다. 1이 나왔고 도미를 1, 빙어를 0으로 했으니 맞는 결과가 출력됐다.
predict함수로 길이 30, 무게 600인 샘플이 무엇인지를 출력하게 해준다. 1이 나왔고 도미를 1, 빙어를 0으로 했으니 맞는 결과가 출력됐다.
입력한 샘플의 주위에 있는 5개의 값을 보고 결과를 결정하는데 n_neighbors=49를 적으면 기본값인 5가 49개가 되어 주위에 있는 49개의 값을 보고 결과를 결정하게 된다. 전체 샘플이 49개이므로 무조건 도미가 나온다.
02-1 훈련 세트와 테스트 세트
지도 학습은 입력(데이터)과 타깃(정답)으로 이루어진 훈련 데이터를 사용해 학습하고 비지도 학습은 타깃 없이 입력 데이터만 사용한다.
- 데이터 세트 : 평가에 사용하는 데이터
- 훈련 세트 : 훈련에 사용되는 데이터
01-3에서 모델이 훈련한 데이터와 테스트 데이터가 같아 무조건 정확도가 1이 나올 수 밖에 없는 코드였기에 이를 보안하기 위해 훈련 세트와 데이터 세트를 나눠 코드를 작성해야 한다.

데이터를 입력하고 fish_data와 fish_target을 앞서 배웠던 것처럼 똑같이 만든다.

fish_data를 인덱스 0~34까지 train_input에 넣고 인덱스 35~끝까지 test_input에 넣는다. fish_target도 똑같은 방법으로 train_target과 test_target에 넣는다. 훈련 세트로 훈련을 하고 테스트 세트로 정확도를 계산해 봤을 때 0이 나온다. 그 이유는 훈련 세트는 도미이고 테스트 세트는 빙어이기 때문이다. 이러한 현상을 샘플링 편향이라고 한다.
위와 같은 오류를 해결하기 위해선 데이터를 섞어야 하는데 이 작업을 편하게 할 수 있는 라이브러리가 numpy이다. numpy는 파이썬 배열 라이브러리로, 고차원의 배열을 만들고 조작할 수 있는 간편한 도구를 많이 제공한다.
 numpy array()함수를 사용하면 파이썬 리스트를 넘파이 배열로 바꿀 수 있다. 이렇게 바꾼 input_arr는 2차원 배열로 나타난다.
numpy array()함수를 사용하면 파이썬 리스트를 넘파이 배열로 바꿀 수 있다. 이렇게 바꾼 input_arr는 2차원 배열로 나타난다.
 shape함수는 그 배열의 샘플 수와 특성 수를 나타내고 샘플 수는 행, 특성 수는 열이다.
shape함수는 그 배열의 샘플 수와 특성 수를 나타내고 샘플 수는 행, 특성 수는 열이다.
 seed함수는 정수 초깃값을 지정한다. 랜덤 함수의 결과를 동일하게 재현하고 싶을 때 사용한다.
seed함수는 정수 초깃값을 지정한다. 랜덤 함수의 결과를 동일하게 재현하고 싶을 때 사용한다.
arange함수는 일정한 간격의 정수 또는 실수 배열을 만드는데 위의 코드에서 49는 0부터 48까지의 인덱스를 가지는 배열을 만든 것이다. shuffle함수는 그러한 배열을 랜덤하게 섞는다.
 랜덤하게 섞인 index배열을 배열 인덱싱을 사용해 인덱스0부터 34까지 34부터 끝까지로 나누어 input_arr와 target_arr에 있는 원소들을 랜덤하게 나눌 수 있다.
랜덤하게 섞인 index배열을 배열 인덱싱을 사용해 인덱스0부터 34까지 34부터 끝까지로 나누어 input_arr와 target_arr에 있는 원소들을 랜덤하게 나눌 수 있다.
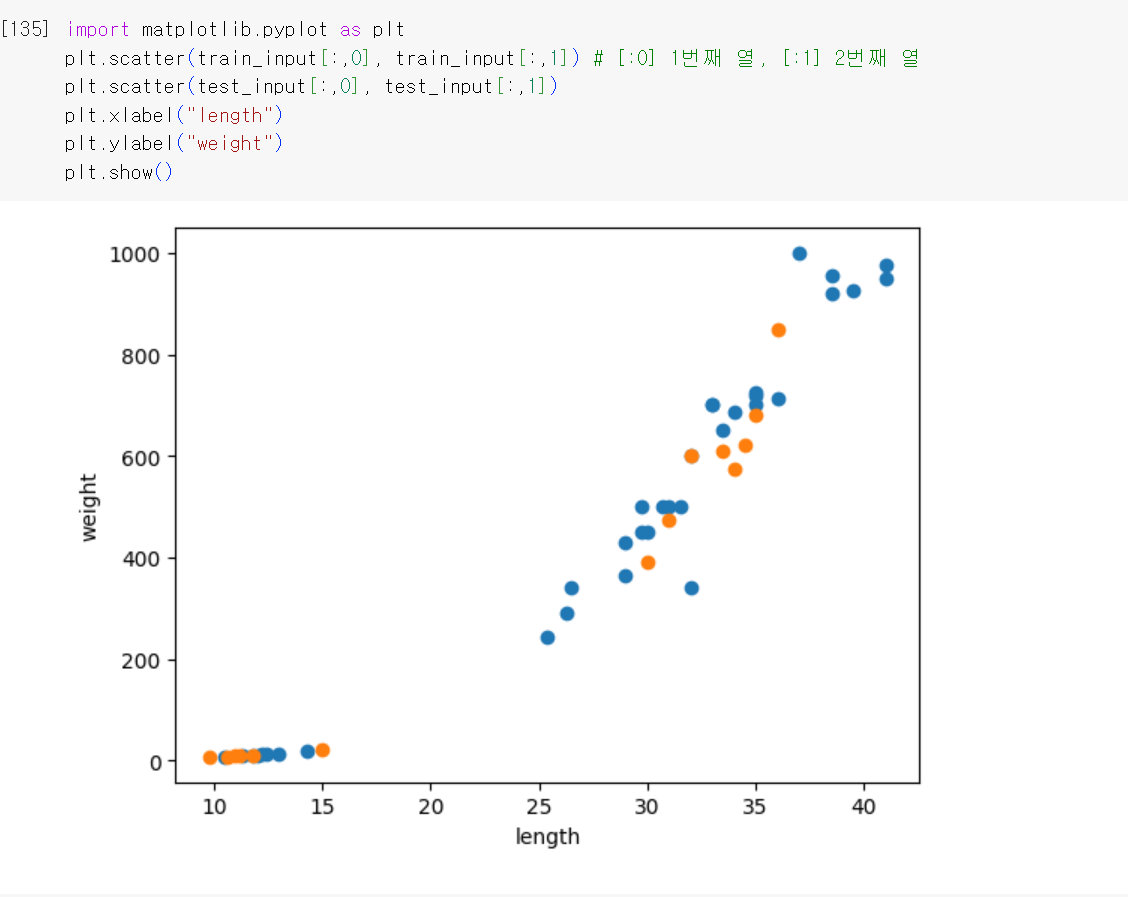 [: , 0]에서 :은 전체를 뜻하기 때문에 train_input에 1번째 열이 된다. [: , 1]은 2번째 열이 된다. 추가로 [:]은 전체 인덱스를 의미한다. 이는 x는 길이, y는 무게를 뜻하는 것이다. 파란색 점은 훈련 세트이고 주황색 점은 테스트 세트이다.
[: , 0]에서 :은 전체를 뜻하기 때문에 train_input에 1번째 열이 된다. [: , 1]은 2번째 열이 된다. 추가로 [:]은 전체 인덱스를 의미한다. 이는 x는 길이, y는 무게를 뜻하는 것이다. 파란색 점은 훈련 세트이고 주황색 점은 테스트 세트이다.
 훈련 세트로 훈련하고 테스트 세트로 정확도를 확인한 결과 1이 나온다. 예측 결과값이랑 테스트 결과값이 같은 것을 확인할 수 있다.
훈련 세트로 훈련하고 테스트 세트로 정확도를 확인한 결과 1이 나온다. 예측 결과값이랑 테스트 결과값이 같은 것을 확인할 수 있다.
코드링크텍스트
02-2 데이터 전처리
함수 정리
np.column_stack : 전달받은 리스트를 일렬로 세운 다음 차례대로 하나의 열로 하여 연결한다.
np.ones, np.zeros : 각각 원하는 개수의 1과 0을 채운 배열을 만들어 준다.
np.full : 원하는 수와 행렬의 개수를 넘겨주면 원하는 수로 채운 배열을 만들어 준다.
train_test_split : 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 준다. 나누기 전에 섞어준다.
random_state : 랜덤 시드를 정하는 함수이다.
stratify : 매개변수로 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눠준다.
kneighbors : 이웃까지의 거리와 이웃 샘플의 인덱스를 반환한다.
xlim : x축의 범위를 지정한다.
mean : 평균 계산한다.
std : 표준편차 계산한다.
 데이터를 작성하고 numpy를 import한 뒤, fish_length와 fish_weight를 각각 하나의 열로 만들어 48*2행렬로 만든다.
데이터를 작성하고 numpy를 import한 뒤, fish_length와 fish_weight를 각각 하나의 열로 만들어 48*2행렬로 만든다.
 fish_target를 만들기 위해 np.ones와 np.zeros를 사용해 1이 35개이고 0이 14개인 1차원 배열을 만든다.
fish_target를 만들기 위해 np.ones와 np.zeros를 사용해 1이 35개이고 0이 14개인 1차원 배열을 만든다.

 도미와 빙어의 데이터가 골고루 섞이기 위해 stratify함수를 사용하고 fish_data가 train_input과 test_input데이터로 나뉘고 fish_target이 train_target과 test_target으로 나뉜다.
도미와 빙어의 데이터가 골고루 섞이기 위해 stratify함수를 사용하고 fish_data가 train_input과 test_input데이터로 나뉘고 fish_target이 train_target과 test_target으로 나뉜다.
 앞 쳅터에서 만든 코드를 작성했고 정확도는 1이다.
앞 쳅터에서 만든 코드를 작성했고 정확도는 1이다.
 새로운 도미 샘플을 넣었더니 빙어(0)으로 결과가 나온다.
새로운 도미 샘플을 넣었더니 빙어(0)으로 결과가 나온다.
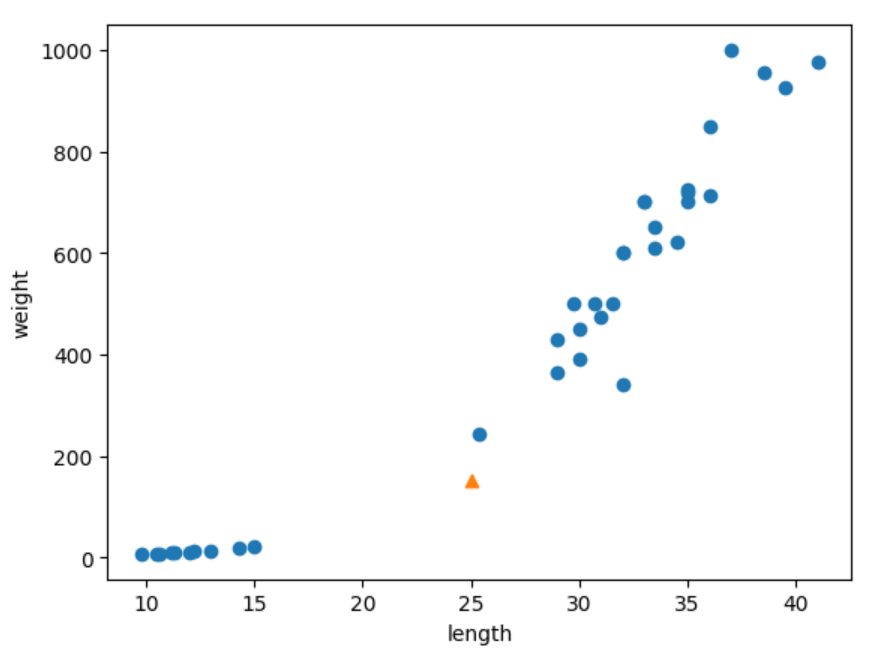 그래프를 눈으로 봤을 때는 도미에 확실히 가까운 걸로 보인다.
그래프를 눈으로 봤을 때는 도미에 확실히 가까운 걸로 보인다.

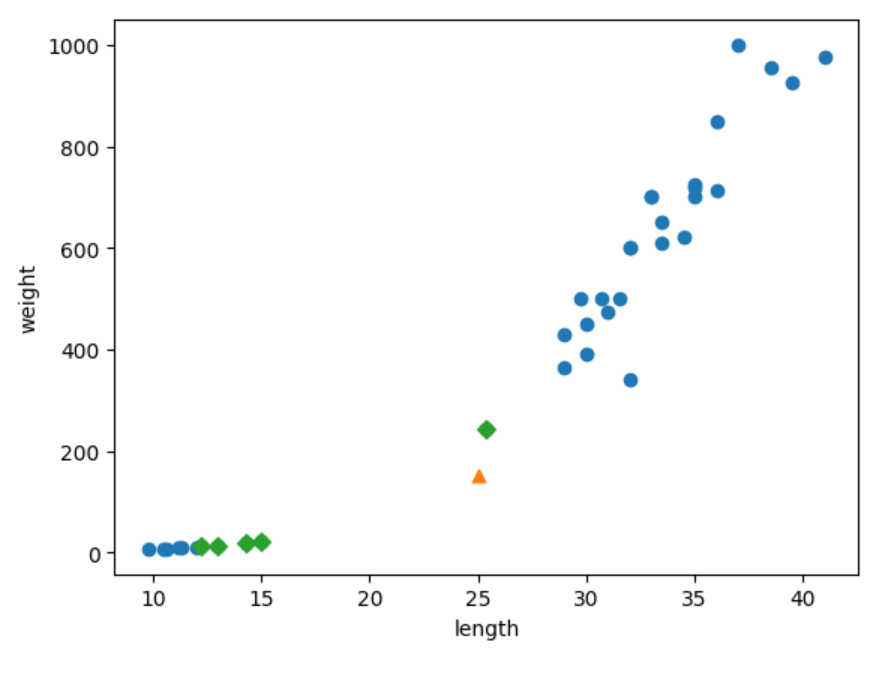 그래프를 보니 가까운 5개의 샘플 중 4개가 빙어인 것으로 보인다. 이러한 결과가 나온 이유는 x축은 범위가 좁고(10~40), y축은 범위가 넓기(0~1000) 때문이다. 이러한 문제를 해결하기 위해 x축의 범위를 동일하게 맞추어야 한다.
그래프를 보니 가까운 5개의 샘플 중 4개가 빙어인 것으로 보인다. 이러한 결과가 나온 이유는 x축은 범위가 좁고(10~40), y축은 범위가 넓기(0~1000) 때문이다. 이러한 문제를 해결하기 위해 x축의 범위를 동일하게 맞추어야 한다.
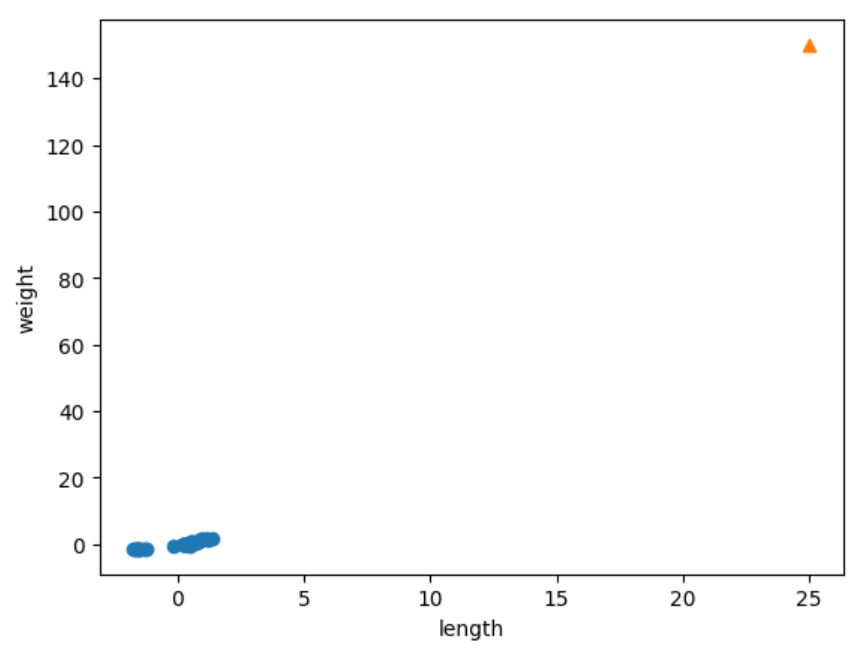
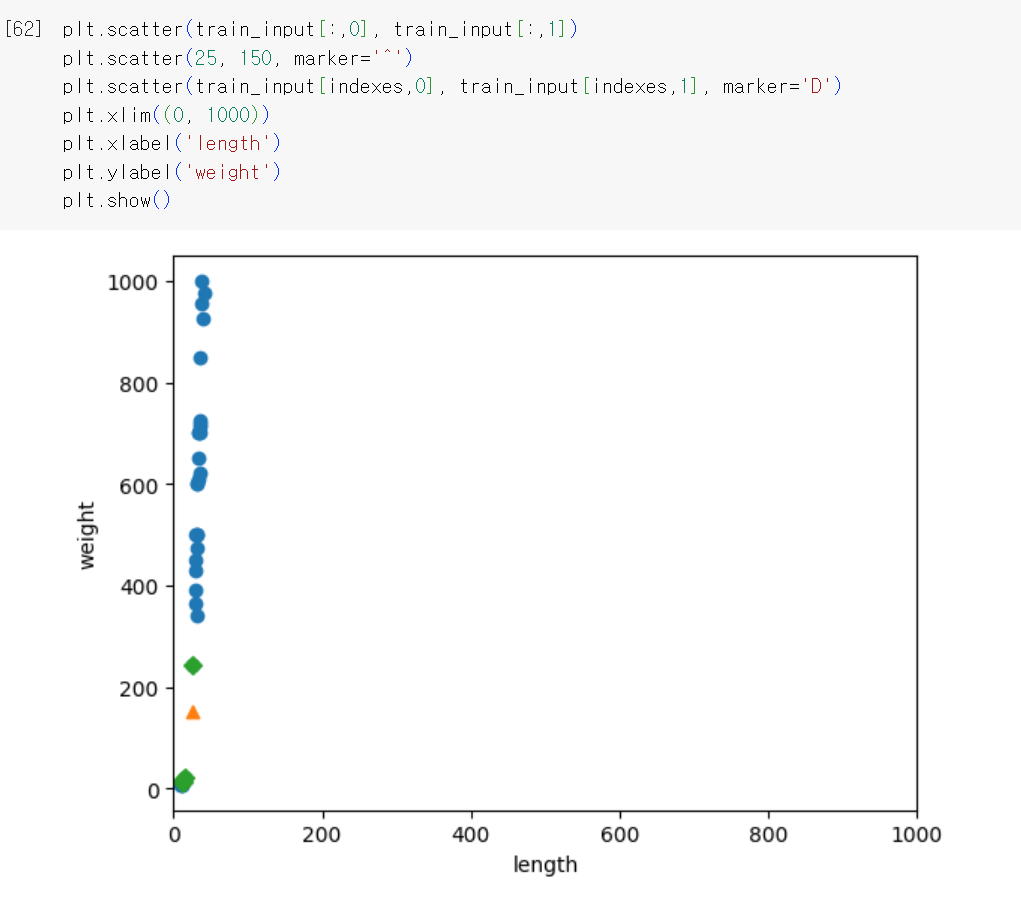 xlim함수를 사용해 범위를 늘렸더니 생선의 길이는 영향을 미치지 못하게 되었다. 샘플 간의 거리에 영향을 많이 받는 알고리즘은 특성값을 일정한 기준으로 맞춰 주어야 한다. 이러한 일을 데이터 전처리라고 한다.
xlim함수를 사용해 범위를 늘렸더니 생선의 길이는 영향을 미치지 못하게 되었다. 샘플 간의 거리에 영향을 많이 받는 알고리즘은 특성값을 일정한 기준으로 맞춰 주어야 한다. 이러한 일을 데이터 전처리라고 한다.
데이터 전처리 방법 중 하나인 표준점수(z점수)를 사용한다. 표준점수는 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다.
계산하는 방법은 (특성-평균)/표준편차이다.
 axis는 축으로 0은 세로, 1은 가로이다. train_input은 행이 샘플이고 열이 특성이기에 axis는 0으로 한다. mean함수를 써 평균을 내고 평균값을 mean으로 받는다. std함수를 써 표준편차를 내고 std로 표준편차 값을 받는다. 각각의 train_input의 원소를 평균으로 빼고 표준편차로 나눈 값을 train_scaled배열로 받는다.
axis는 축으로 0은 세로, 1은 가로이다. train_input은 행이 샘플이고 열이 특성이기에 axis는 0으로 한다. mean함수를 써 평균을 내고 평균값을 mean으로 받는다. std함수를 써 표준편차를 내고 std로 표준편차 값을 받는다. 각각의 train_input의 원소를 평균으로 빼고 표준편차로 나눈 값을 train_scaled배열로 받는다.
 이러한 그래프가 된다. 여기서 새로운 도미의 샘플은 변화를 주지 않았기 때문에 이러한 그래프가 그려지게 된다. 여기서 중요한 점은 새로운 샘플과 테스트 세트도 훈련 세트의 평균과 표준편차로 변환해야 한다는 것이다.
이러한 그래프가 된다. 여기서 새로운 도미의 샘플은 변화를 주지 않았기 때문에 이러한 그래프가 그려지게 된다. 여기서 중요한 점은 새로운 샘플과 테스트 세트도 훈련 세트의 평균과 표준편차로 변환해야 한다는 것이다.

 모델을 훈련시킨다.
모델을 훈련시킨다.
 테스트 세트를 훈련 세트의 평균과 표준편차로 변환하였고 정확도는 1이다.
테스트 세트를 훈련 세트의 평균과 표준편차로 변환하였고 정확도는 1이다.
 새로운 샘플의 예측 결과값이 1이 나온다.
새로운 샘플의 예측 결과값이 1이 나온다.
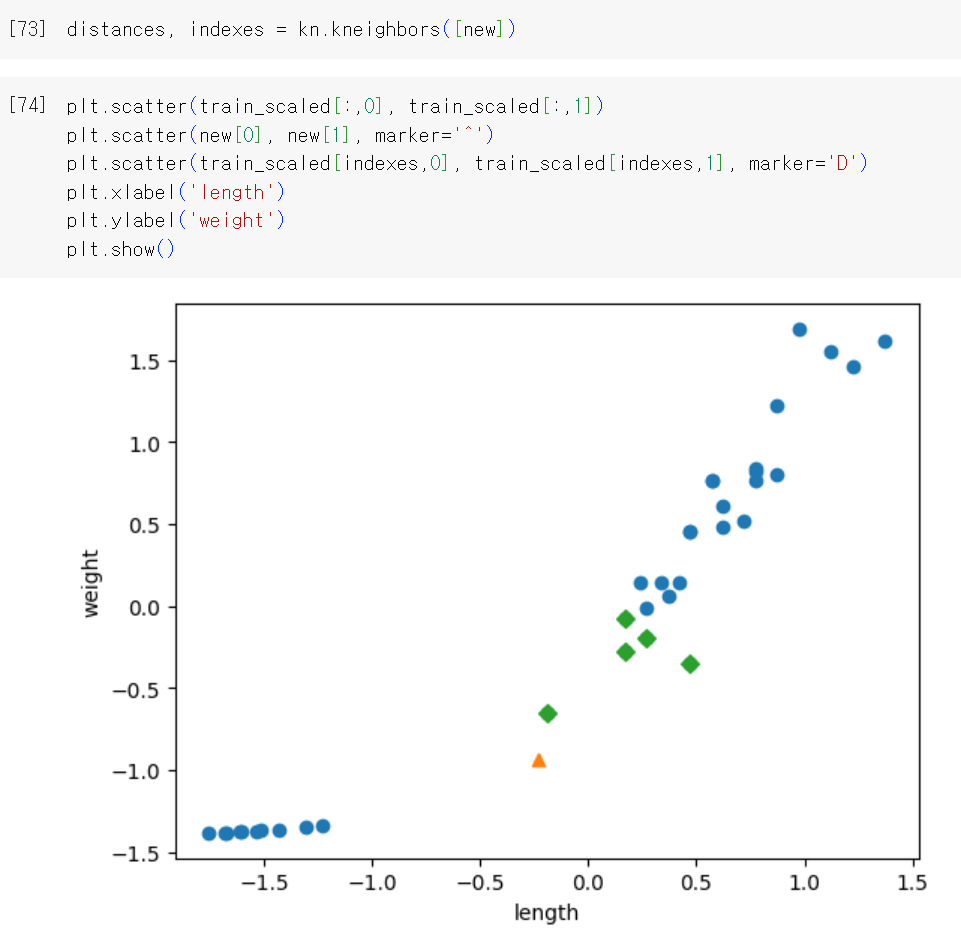 가까운 5개의 샘플을 색칠해 보았을 때 도미 5개가 나오는 걸 확인 할 수 있다.
가까운 5개의 샘플을 색칠해 보았을 때 도미 5개가 나오는 걸 확인 할 수 있다.
코드링크텍스트
