https://openreview.net/pdf?id=CScEFM0FmO
TL;DR
토큰 레벨 협업 디코딩에서 과도한 모델 전환 비용과 숫자·수식 등 연속 스팬 파손 문제를 동시에 해결하기 위해
모델 지속성(persistence) + 스팬-가드(span-aware gating) + 경량 GRU 라우터를 결합한 라우팅 프레임워크를 제안.
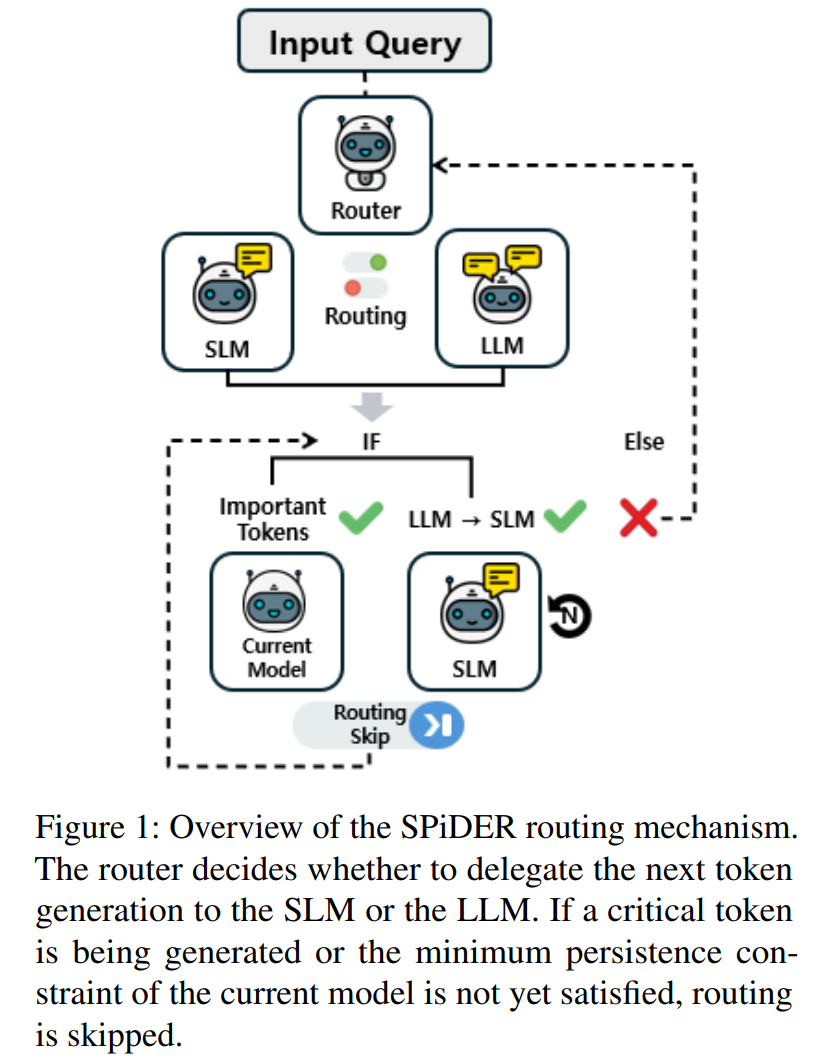

1) 한눈에 보기 (Abstract in 5 lines)
- 문제: 토큰 단위로 SLM↔LLM을 잦게 스위칭하면 KV 재계산/재토크나이즈 등 숨은 오버헤드와, 숫자·수식 같은 연속 스팬 파손이 발생.
- 핵심: (a) 지속성 — 전환 후 최소 토큰 수
M_min유지, (b) 스팬-가드 — 숫자/수식 구간에서 전환 금지, (c) GRU 라우터 — 최근 창 신호(엔트로피/마진/유사도 등) 누적해 전환 확률 예측. - 효과: LLM은 필요할 때만 호출 → 정확도 향상과 시간(또는 비용) 대비 효율 향상.
- 적용성: 파인튜닝 없이도 유효, 비동일 패밀리 조합에서도 효율적.
- 포지셔닝: Co-LLM 등 기존 토큰 라우팅 대비 스위칭 억제+스팬 보존을 명시적으로 설계.
2) 왜 이 연구인가? (Motivation)
토큰 라우팅은 미세 제어가 가능하지만,
1) Switching Overhead: 잦은 전환으로 KV 캐시 갱신/컨텍스트 재계산 비용이 쌓인다.
2) Span Breakup: 숫자·식 등 연속 스팬이 중간에 끊겨 정답/유창성이 저하된다.
SPiDER는 스팬 일관성과 전환 빈도를 규칙으로 보장하고, 결정은 경량 순환( GRU )으로 시간적 맥락을 누적하여 더 안정적 라우팅을 수행한다.
3) 방법론 (Method)
3.1 창 기반 특징 (Windowed Features)
토큰 시점 (t)에서 최근 (W) 토큰 창을 보며, 확률 분포의 엔트로피/마진, 숫자 스팬 비율, 문장 임베딩 유사도 등을 계산한다.
평균 엔트로피(불확실성)
엔트로피 변화량
평균 마진(1–2위 확률 차)
마진 변화량
숫자/수식 지속 비율
쿼리–창 임베딩 코사인
위 6종 신호 조합으로 GRU 라우터가 전환 확률을 안정적으로 추정.
3.2 GRU 라우터
수치 특징 (x{\text{num},t})과 임베딩 특징 (x{\text{emb},t})를 투영해 GRU 은닉 (h_t)로 누적, 전환 확률 (p_t) 산출:
3.3 모델 지속성 (Model Persistence)
전환 후 최소 토큰 수를 강제:
→ 핑퐁 전환 방지·KV 오버헤드 억제.
3.4 스팬-가드 (Span-aware Gating)
토큰이 숫자/수식 패턴(예: [0-9.+=*/]+)과 매칭되면 전환 잠금을 걸고 스팬 종료 시까지 유지 → 연속 스팬 보존.
3.5 학습 라벨·손실
- 윈도우 라벨링: 정답 결정에 중요 토큰이 포함된 창을 LLM 위임(1) 라벨, 그 외 0.
- 손실: 마스크·클래스가중 BCEWithLogitsLoss로 학습.
3.6 추론 루프 (요약 의사코드)
- 중요 스팬이면 전환 검사 스킵
- 지속성 카운트 (c \ge M_{\min})일 때만 (p_t) 계산·임계 판단
- 전환 시 카운터/캐시 재설정, 다음 토큰 진행

4) 실험 (Setup)
- 데이터셋: GSM8K(수리추론, 7,473 train / 1,319 test), 6-shot 기본.
- 모델 조합(예): SLM — Llama-3.2-1B, Qwen-2.5-1.5B / LLM — DeepSeek-R1-Distill-Qwen-14B, Qwen-2.5-32B.
- 지표: Accuracy, 평균 추론시간(또는 비용). 효율(Eff):(또는 ACC/Time: 정확도÷평균시간).
5) 핵심 결과 (Key Results)
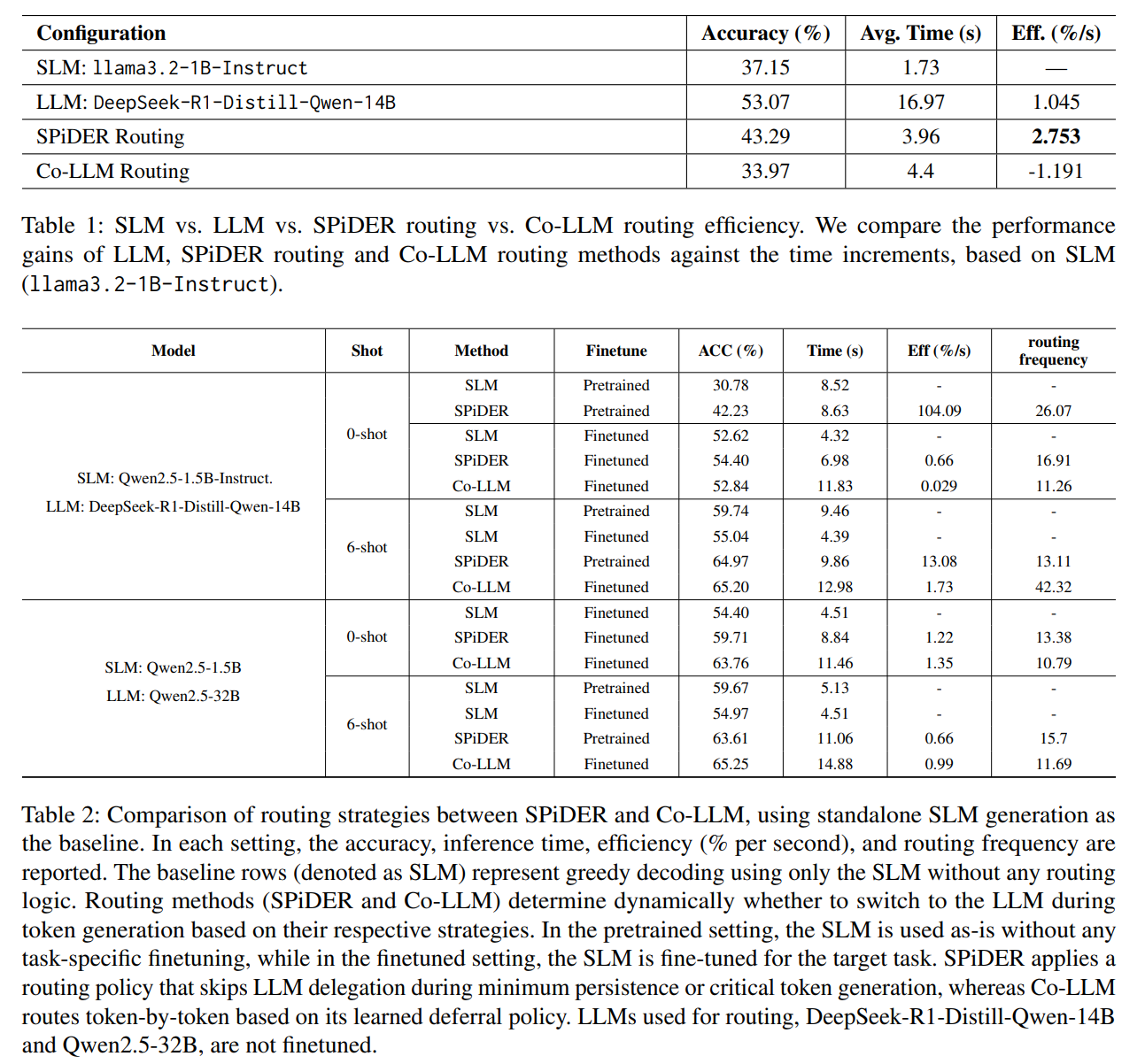
5.1 단일 모델 vs 라우팅
- SLM(1B): 37.15% @ 1.73s
- LLM(14B): 53.07% @ 16.97s
- SPiDER(라우팅): 43.29% @ 3.96s, Eff = 2.753%/s
- Co-LLM: 33.97% @ 4.40s, Eff = −1.191%/s
→ SPiDER는 적은 지연 증가로 의미 있는 정확도 개선, LLM 단독 대비 효율↑.
5.2 파인튜닝 유무/샷팅 별 비교(요약)
- Pretrained, 0-shot (Qwen-1.5B ↔ 14B): SLM 30.78%@8.52s → SPiDER 42.23%@8.63s, 큰 효율 향상.
- Pretrained, 6-shot: SLM 59.74%@9.46s → SPiDER 64.97%@9.86s.
- Finetuned, 0-shot: SPiDER 54.40%@6.98s, Co-LLM 52.84%@11.83s(효율 낮음).
→ SPiDER는 파인튜닝 없이도 일관된 효율 이득.
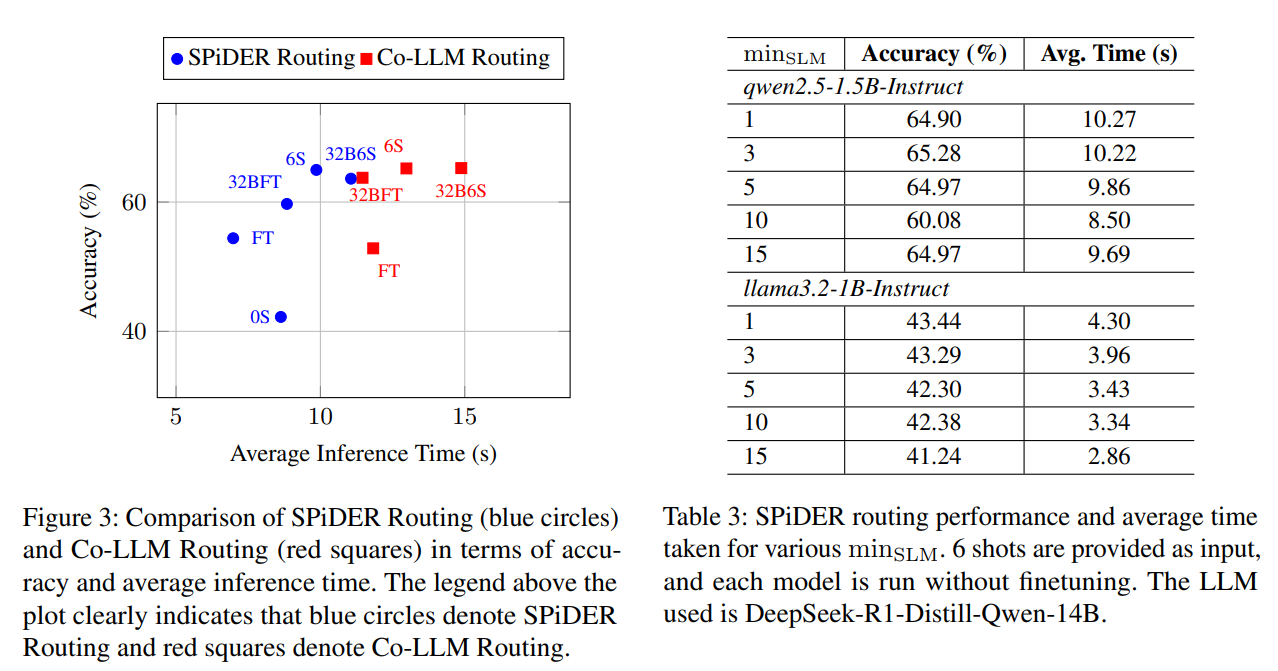
5.3 지속성 하이퍼파라미터(minSLM) 영향
- Qwen-1.5B: minSLM 3→5로 올리면 정확도 65.28→64.97%(소폭↓), 시간 10.22→9.86s(소폭↓).
- Llama-1B: minSLM 1은 43.44%@4.30s, 15는 41.24%@2.86s — 정확도↔속도 상충.
→ 지연 제약이 크면 minSLM↑, 정확도 중시면 minSLM↓ 권장.
6) Ablation & 민감도 (요지)
- 라우터 구조(GRU/LSTM/Transformer): 경량 GRU로도 충분, 상황에 따라 Transformer가 약간 높을 수 있으나 비용 증가. (표 생략)
- 특징 제거 실험: 여러 조합에서 정확도/재현율이 안정 구간(≈0.65–0.72)에 머물러 단일 특징 의존성 낮음. (표 생략)
(원문 부록 E/F 참고)
7) 의미 & 차별점 (Why it matters)
- 실서비스 친화: 지속성+스팬-가드로 숨은 오버헤드·스팬 파손 ↓ → 모바일/실시간 적합성↑.
- 운영 편의성: 파인튜닝 없이 배치 가능, 이기종 모델 조합에도 유연.
- 연구적 포지션: 토큰 라우팅(Co-LLM) 대비 전환 안정화, 쿼리 라우팅 대비 세밀 제어를 유지.
8) 한계 & 향후 과제
- 도메인: 현재 GSM8K 중심 → 코드/표/멀티모달로 일반화 평가 필요.
- 스팬 감지: 정규식 기반 → 학습형 스팬 태거로 고도화 여지.
- 하이퍼 적응: (\tau, M_{\min})을 상황 적응형으로 학습(예: RL)하면 추가 개선 가능.
