배열이란
배열은 연관된 정보를 그룹핑 하는데 사용한다.
만약 데이터가 1개나 2개일 경우면 각각 변수명을 부여하는 것이 유리하지만 데이터가 늘어난다면 여러 데이터를 하나의 이름으로 그룹핑하여 관리 할 필요성이 생기고 이럴 때 사용하는 것이 배열이다.
변수에 데이터를 담을 때는 1개씩 할당가능하지만 int a = 1004; 프로그래밍을 하다보면 다루어야 할 데이터가 아주 많아져서 관리하기가 어려워지게 된다.
이때 연관성이 있는 여러 데이터들을 한번에 관리하기에 용이한 방법 중에는 배열이 있다.
변수가 하나의 데이터를 저장하기 위한 것이라면 배열은 여러 개의 데이터를 저장하기 위한 것이다.
배열의 모든 원소는 같은 자료형이여야한다. (Ex) 정수형, 실수형, 문자열)
배열 정의와 할당 방법
배열을 정의할 때 데이터 타입과 크기를 알수 있다.
new 키워드를 사용하므로 배열이 객체라는 것 또한 알 수 있다.
생성하면서 동시에 엘리먼트를 할당할 수도 있다.
// 문자열 배열 생성 예시 1
String[] classGroup1 = { "소정", "유지", "왕자", "수진" };
// 문자열 배열 생성 예시 2
// 유의점은 배열의 크기를 꼭 지정해야한다.
String[] classGroup2 = new String[4];
classGroup2[0] = "소정";
classGroup2[1] = "유지";
classGroup2[2] = "왕자";
classGroup2[3] = "수진";
배열의 구조
C언어로 배열을 설명하면, 배열은 크기를 지정하고 해당 크기만큼의 연속된 메모리 공간을 할당받는 작업을 수행하는 자료형을 말한다. 크기가 고정되어 있으며, 한번 생성한 배열은 크기를 변경하는 것이 불가능하다.
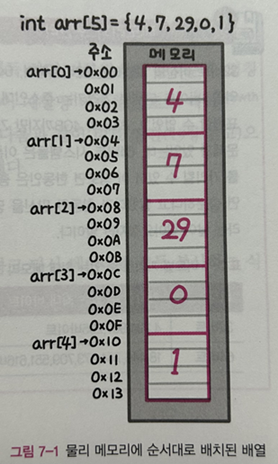
int[] arr = {4, 7, 29, 0, 1};
Index: 0 1 2 3 4
+-----+-----+-----+-----+-----+
Value: | 4 | 7 | 29 | 0 | 1 |
+-----+-----+-----+-----+-----+
↑ ↑ ↑ ↑ ↑
arr[0] arr[1] arr[2] arr[3] arr[4]물리 메모리에는 이 배열 엘리먼트의 값 4, 7, 29, 0, 1이 아래 그림과 같이 순서대로 배치된다.
int의 크기는 컴파일러와 프로세서 구조에 따라 상이하지만(16비트에선 2바이트였다) 오늘날엔 32비트 이상의 시스템을 사용하기 때문에 4바이트로 사용한다. 또한 메모리에 대한 접근 방식은 바이트 단위로 하여, 가리키는 주소는 1바이트이다. 따라서 가리키는 주소는 1바이트마다 1씩 증가한다.
그림 예시에서 엘리먼트는 4바이트이고, 따라서 배열의 주소 또한 4씩 증가한다.
| 용어 | 설명 |
|---|---|
| Index(인덱스) | 배열 요소의 위치를 나타내는 숫자 (0부터 시작) |
| Value(값) | 각 위치에 저장된 실제 데이터 |
| Element(요소) | 배열의 한 항목, 즉 arr[2] = 29 같은 것 |
배열의 제어
우리는 엘리먼트의 인덱스를 통해 값을 가져올 수 있다.
주의할 점은 인덱스는 0부터 시작한다는 점이다.
하지만 아직 설정하지 않아서 값이 없는 엘리먼트의 값을 가져오려고 한다면 자바에서는 기본값을 반환한다. (int면 0, 객체면 null을 반환하게 된다.)
배열의 크기를 알고 싶다면 length()를 이용하면 된다. 이 크기는 채워진 값을 알려주는 것이 아니라 값이 들어갈 수 있는 전체 크기를 의미한다.
String[] classGroup = { "소정", "유지", "왕자", "수진" };
// index(인덱스)를 이용한 element(원소) 도출
System.out.println(classGroup[0]); // 소정
System.out.println(classGroup[2]); // 왕자
// 배열의 크기
System.out.println(classGroup.length); // 4 배열과 반복문의 활용
배열과 반복문은 뗄레야 뗄 수 없는 긴밀한 관계이다.
String[] members = { "소정", "유지", "왕자", "수진" };
// 방법 1 while문
int i = 0;
while(members.length > i) {
System.out.println(members[i]);
i++;
}
// 방법 2 for문
for (int i = 0; i < members.length; i++) {
String member = members[i];
System.out.println(member + "이(가) 상담을 받았습니다.");
}
// 방법 3 for-each문법
for (String e : members) {
System.out.println(e + "이(가) 상담을 받았습니다.");
}
배열과 연결리스트
특정 정보를 저장하려면,
즉 컴퓨터의 메모리에 데이터를 저장하려면
컴퓨터에게 메모리 공간을 요청하게 된다.
그러면 컴퓨터는 저장 가능한 메모리 주소를 알려준다.
여러 개의 데이터를 저장해야 할 경우엔 보통
배열이나 리스트 같은 자료구조를 사용한다.
이 중에서 리스트의 한 종류인 연결 리스트를 예로 들어
메모리 저장 방식의 차이점을 설명해보자.
예를 들어, 4명의 친구가 영화관 티켓을 예매하려 한다고 해보자.
대부분은 나란히 앉을 수 있는 4자리를 고르려고 할 것이다.
그래서 일주일 전에 미리 4자리를 예약해두었다.
그런데 영화 당일, 친구 2명이 더 합류하겠다고 한다.
하지만 이미 옆자리는 다른 사람이 예매해서
6명이 나란히 앉을 수는 없는 상황이 되었다.
이럴 땐 어떻게 해야 할까?
기존 예약을 취소하고,
6명이 나란히 앉을 수 있는 다른 자리를 새로 예매해야 한다.
이 상황이 바로, 배열에서 새 원소를 추가해야 할 때의 문제점과 비슷하다.
만약 친구가 한 명 더 늘어나면?
또 예매를 취소하고, 7명이 앉을 자리를 다시 찾아야 한다.
즉, 배열은 처음 정해진 크기만큼만 데이터를 담을 수 있어서,
새로운 데이터를 추가하는 일이 번거롭고 비효율적이다.
"그럼 넉넉하게 예매해두면 되지 않을까?" 하고
미리 여분의 좌석을 사두는 방식도 생각해볼 수 있다.
하지만 이럴 경우,
빈 좌석은 낭비되고,
다른 사람이 영화를 볼 기회도 빼앗게 된다.
게다가, 만약 친구 수가 여분보다 많아지면
결국 또 좌석을 다시 예매해야 한다.
게다가 친구가 50명이라면,
50명이 나란히 앉을 수 있는 영화관이 없을 수도 있다!
그런데 만약 친구들이
“우리 흩어져서라도 보자!”라고 말한다면 어떨까?
이건 바로 연결 리스트를 선택한 것과 비슷하다.
연결 리스트를 쓰면,
빈 자리를 어디든 사용할 수 있다.
친구들이 떨어져 앉게 되긴 하지만,
모두 자리에 앉아 영화를 함께 볼 수 있는 것이다.
하지만 이 방식에도 단점이 있다.
모두가 어디 앉았는지 기억하기 어렵기 때문에,
갑자기 대화를 나누고 싶어도
영화가 끝날 때까지 기다려야 할 수도 있다.
연결 리스트는 각 원소가
자신의 데이터와 다음 원소의 주소를 함께 저장한다.
새로운 원소를 추가할 때는
메모리의 빈 공간에 데이터를 저장하고,
그 주소를 이전 원소에 연결함으로써
전체가 연결된 구조를 형성하게 된다.
먼저, 배열의 가장 큰 장점은 임의 접근(random access)이 가능하다는 점이다.
특정 원소가 몇 번째에 있는지 바로 계산할 수 있다.
배열은 메모리상에 연속된 공간에 저장되기 때문에,
간단한 산술 계산만으로 원하는 위치의 값을 곧바로 찾아낼 수 있다.
예를 들어, 5번째 원소를 알고 싶다면
시작 주소 + (5 × 자료형 크기)만 계산하면 된다.
매우 빠르다.
반면, 연결 리스트는 이런 식의 접근이 불가능하다.
마지막 원소를 찾으려면
0번 → 1번 → 2번 ... 이렇게
앞에서부터 차례차례 따라가야 한다.
즉, 순차 접근(sequential access)만 가능하다.
그래서 읽기 속도는 배열보다 느리다.
하지만 배열에는 큰 단점도 있다.
중간에 원소를 추가하거나 삭제해야 할 경우,
그 이후의 모든 데이터를 한 칸씩 밀거나 당겨야 한다.
이 과정에서 많은 연산과 이동이 발생한다.
이럴 때 연결 리스트는 훨씬 유리하다.
새로운 원소를 넣거나 값을 제거할 때
이전 원소의 주소값만 바꿔주면 끝이다.
다른 원소들을 이동시킬 필요가 없다.
최종 정리: 연결 리스트는 삽입과 삭제에 좋고, 배열은 임의 접근이 좋다.
| 구분 | 배열 | 연결 리스트 |
|---|---|---|
| 접근 방식 | 임의 접근 가능 | 순차 접근만 가능 |
| 메모리 구조 | 연속된 메모리 공간 | 불연속적인 메모리 공간 |
| 읽기 속도 | O(1) | O(n) |
| 삽입/삭제 속도 | O(n) | O(1) (포인터만 조정 시) |
| 검색 효율 | 빠름 | 느림 |
| 크기 변경 | 어렵다 (재할당 필요) | 유연하다 (필요한 만큼 확장 가능) |
| 사용에 적합한 상황 | 읽기/검색이 잦고 크기가 고정된 경우 | 삽입/삭제가 빈번한 경우 |
배열의 오류와 한계
String[] members = { "소정", "유지", "왕자", "수진" };
System.out.println(members[4]);
//또는
members[4] = "지영";
만약 배열의 크기를 벗어난 존재하지 않는 인덱스를 사용하거나 할당하려 한다면 아래와 같은 예외를 확인할 수 있다.
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 4
at ot_array.ExceptionDemo.main(ExceptionmDemo.java:7)
배열은 어느 위치에서나 O(1)에 조회가 가능하다는 장점이 있다.
하지만 고정된 크기 만큼의 연속된 메모리 할당이다. 하지만 실제 데이터에서는 전체 크기가 어떻게 될지 가늠하기 힘들때가 많다. 때로는 너무 적은 영역을 할당해 모자라거나, 때로는 너무 많은 영역을 할당해 낭비될 때도 있다.
처음부터 큰 배열을 지정하여 램의 메모리 공간을 낭비하는 것도 바람직하지 않고 추후에 유연하게 확장하기가 어렵다는 불편함과 한계를 극복하기 위하여 미리 크기를 지정하지 않고 자동으로 조정할 수 있다면 좋지 않을까? 라는 고민을 해결하고자 자동으로 리사이징하는 배열인 동적 배열이 등장했다. (자바에서는 ArrayList, C++에서는 Std::vector가 대표적이다.)
자바는 컬렉션(Collection)에 편리한 자료구조들을 이미 모두 구현해두었기에 사용하기가 편하다.
컬렉션 프레임워크
동적 배열 리사이징
동적 배열의 원리는 간단하다. 이미 초깃값을 작게 잡아 배열을 생성하고, 데이터가 추가되면서 가득 채워지면, 늘려주고 복사하는 식이다. 대게는 더블링(Doubling)이라고 하여 2배씩 늘려주는데, 모든 언어가 항상 그런 것은 아니고 언어마다 늘려가는 비율이 상이하다. 경우에 따라 값이 70%정도 채워졌을때 리사이징하는 경우도 있지만(특정 성능 최적화 라이브러리나 캐시 등), 자바 ArrayList는 가득 찼을 때만 리사이징한다.
자바의 ArrayList의 더블링 구조는 초깃값 10인 배열을 설정하고, 값으로 공간이 가득 차면 더블링으로 늘려준다. 명칭과 달리 정확히 2배인 20으로 늘리는 것은 아니며, 이 재할당 비율을 그로스 팩터(성장 인자)는 비트 연산으로 계산하도록 구현되어 있으며, 이 비율은 정확히 1.5개다.
즉, 배열이 가능차면 1.5배 더 큰 메모리 영역을 할당하고 다시 데이터를 모두 복사하는 식으로 늘려나간다.
복사하는 작업은 O(n) 비용이 발생하며, 최악의 경우는 삽입시 O(n)이 되지만 자주 일어나는 일이 아니므로, 분할 상환 분석에 다른 입력시간은 O(1)이라고 봐야한다.
만약 카카오톡에서 회원 정보를 관리한다면?
카카오톡에서 사용자 아이디 목록을 관리한다고 가정하자.
로그인할 때마다 입력한 아이디가 이미 등록된 아이디인지 확인해야 한다.
검색 속도를 높이기 위해 이진 탐색을 사용할 수 있다.
이진 탐색을 하려면 중간 위치부터 바로 접근할 수 있어야 하므로,
아이디 목록은 정렬된 배열 형태여야 한다.
(예: A부터 Z까지 순서대로 정렬된 상태)
하지만 이 방식엔 단점이 있다.
새로운 가입자가 생길 때마다 배열의 끝에 추가한 후
전체를 다시 정렬해야 해서 비효율적이다.
그래서 한 가지 대안으로,
A부터 Z까지의 배열을 만들고,
각 칸이 해당 알파벳으로 시작하는 아이디의 연결 리스트를 가리키도록 하는
복합 자료구조를 생각할 수 있다.
이 방식은 검색 속도 면에서
연결 리스트보다는 빠르고, 배열보다는 느리다.
하지만 신규 등록 시에는 정렬을 다시 하지 않아도 되는 장점이 있다.
실제로는 회원 정보를 데이터베이스로 관리하고,
그 안에서는 해시 테이블이나 B-트리 같은 자료구조를 사용한다.
배열의 단점으로 마땅한 기능이 없다는 점도 있다.
데이터를 추가하고 삭제하고 이동시키는 것이 불가능하다.
하지만 크기가 정해져 있고, 마땅한 기능이 없기에
작고 가볍고 단순하므로 도구로서 아주 중요하고 유용하기도 하다는 역설적인 장점이 되기도 한다.
해시 테이블이나 B-트리 같은 복잡한 구조들도 결국 배열이나 리스트 같은
기초 자료구조를 바탕으로 만들어지므로 배열은 아주아주 중요한 자료구조라고 볼 수 있다.
참고자료
