시험에서 점수를 올리기에 가장 좋은 방법은 문제를 많이 풀어보는 것이기에
기출문제를 풀어보면서 내가 모르는 것을 발견하고,
틀린 부분을 보충하여 공부하였다.
문제를 맞추면 기분 좋은 일이지만
맞추지 못하는 문제를 발견하는 것이 더 좋은 일이라고 생각했기에
헷갈리는 지문이 있을경우 모조리 체크해두었다가 채점과 함께 찾아보았다.
내가 자주 틀리던 문제들에는 서브쿼리, 계층형 질의, 옵티마이저, Having 절, 그룹함수(Roll up, cube, grouping sets) 등등이 있었는데 오답노트를 통해서 채울 수 있었다.
2과목 2장 SQL활용
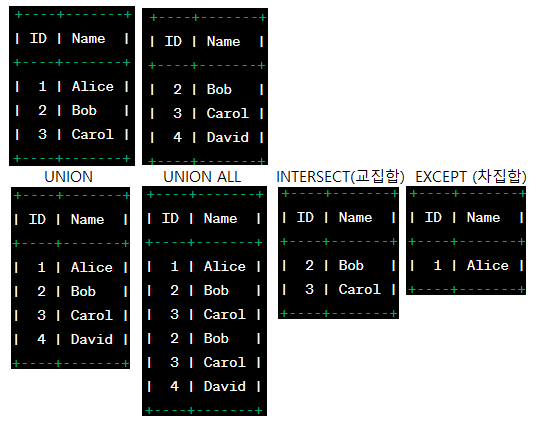
집합연산자
일반집합 연산자
집합 연산자는 하나의 테이블(또는 서브쿼리)에서 나오는 조회(SELECT) 쿼리의 결과를 대상으로 연산을 수행하는 연산자로 UNION, UNION ALL, INTERSECT, MINUS등이 있다. 조회의 결과를 대상으로 연산을 수행하므로, 여러 개의 SELECT문을 하나의 쿼리로 만드는 연산자라고 할 수 있다.
Union All만 중복을 허용한다.
순수관계 연산자
- SELECT -> WHERE로 구현
- PROJECT -> SELECT로 구현 (테이블에서 원하는 열만 선택)
- NATRUAL JOIN -> 다양한 JOIN으로 구현
- DIVIDE -> 현재 사용 X
FROM절 JOIN 형태
-
INNER JOIN : ON 또는 USING 조건절을 사용하여 연결 조건을 지정하여 두 개 이상의 테이블을 결합하고, 두 테이블 간의 일치하는 행만 반환 USING, ON 조건절 사용이 필수적이다.
-
NATURAL JOIN : 두 테이블 사이에서 동일한 이름을 가진 열을 자동으로 모두 찾아내어 해당 열을 기반으로 EQUI JOIN을 수행한다.
NATURAL JOIN이 명시되면 ON, USING, WHERE JOIN조건 정의 불가 (SQL에서 지원 X) -
USING 조건절 : INNER JOIN 또는 NATURAL JOIN에서만 사용되며 같은 이름을 가진 칼럼들 중에서 원하는 칼럼에 대해서만 EQUI JOIN을 한다. JOIN 칼럼에 대해서 ALIAS나 테이블명을 사용할 수 없다 (SQL에서 지원 X)
-
ON 조건절 : ON 절은 INNER JOIN, OUTER JOIN, CROSS JOIN에서 사용된다. ON과 WHERE(데이터 조건 추가가능)을 분리하면 이해가 쉬우며, 칼럼명이 달라도 JOIN 조건을 사용할 수 있다. ALIAS와 테이블명을 반드시 사용한다.
-
CROSS JOIN : 카티시안의 곱으로도 불리며 두개의 테이블을 결합하여 가능한 모든 행의 조합을 반환하며 양쪽집합 M*N건의 데이터 조합이 발생한다.
-
OUTER JOIN(LEFT, RIGTH, FULL) : INNER JOIN과는 달리 JOIN 조건에서 동일한 값이 없는 행도 반환가능하다. USING, ON을 반드시 사용해야 하며 (+)가 안붙은 쪽으로 JOIN한다.
- LEFT OUTER JOIN : 먼저 표기된 좌측 테이블에 해당하는 데이터를 읽은 후 나중에 표기된 우측테이블에서 JOIN 대상 데이터를 읽어 온다.
우측값에서 같은 값이 없는 경우 NULL로 채운다. - RIGHT OUTER JOIN : LEFT OUTER JOIN의 반대
- FULL OUTER JOIN : 좌우측 테이블의 모든 데이터를 읽어 JOIN하여 결과를 생성한다.
중복데이터는 삭제한다.
계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 계층형 질의를 사용한다.
- START WITH : 시작 위치 (최상위 노드) 지정
- CONNECT BY : 연결고리 역할
- PRIOR : 계층 구조 전개. PRIOR 자식=부모(순방향), PRIOR 부모=자식(역방향)
- LEVAL : 루트면 1, 하위면 2, leaf까지 1씩 증가
- CONNECT BY ISLEAF : 리프데이터면 1, 아니면 0
- CONNECT BY NOCYCLE : 동일한 데이터가 전개되지 않음(중복발생시 루푸돌지 않게)
조상으로 부터 데이터가 존재하면 1, 아니면 0 - ORDER SIBLINGS BY : 동일 레벨 노드 간 정렬
- WHERE : 모든 전개 후 지정된 조건을 만족하는 데이터만 추출
- SYS CONNECT BY PATH(칼럼, 경로분리자)(오라클) : 루트 데이터부터 현재 전개할 데이터까지의 경로를 표시
- CONNECT BY ROOT(칼럼)(오라클) : 현재 전개할 데이터의 루트 데이터를 표시 ()
셀프 조인
한 테이블 내 두 칼럼이 연관 관계가 있을 때 동일 테이블 사이의 조인. FROM에 동일 테이블이 별칭을 가지고 2번 이상 나타난다.
서브 쿼리
- 하나의 SQL문 안에 포함된 또 다른 SQL문으로 알려지지 않은 기준을 이용한 검색에 사용한다.
- 서브쿼리는 괄호로 감싸있고, 단일 행이나(결과가 1개이상이여야함) 복수 행(결과 개수 상관없음) 비교연산자와 함께 사용 가능하다.
- ORDER BY 를 사용하지 못하고 SELECT, FROM, WHERE, HAVING, ORDER BY, INSERT-VALUES, UPDATE-SET에 사용가능
단일행 비교 연산자 : = < >= <> 서브쿼리 결과로 1개행 반환
다중행 비교 연산자 : IN, ALL(모든결과값 만족), ANY, EXISTS(만족하는값이 있는지) 등
스칼라 서브쿼리 : 한 행 한 칼럼만을 반환하는 서브쿼리(단일행), SELECT 절에서 사용하는 서브쿼리
인라인 뷰 : FROM 절에서 사용되는 서브쿼리. 인라인 뷰는 SQL문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다.
VIEW(뷰)
테이블은 실제로 데이터를 가지고 있는 반면, 뷰(View)는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰 정의(View Definition)만을 가지고 있다.
뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블(Virtual Table)이라고도 한다.
뷰의 장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다. 또한 해당 형태의 SQL문을 자주 사용할 때 뷰를 이용하면 편리하다.
- 보안성 : 직원의 급여정보처럼 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 때 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있다.
CREATE VIEW, DROP VIEW로 생성과 삭제
그룹함수
ROLLUP
ROLLUP은 소그룹간의 소계를 계산한다.
인수 순서가 바뀌면 수행 결과도 바뀌게 되므로 인수의 순서에도 주의해야 한다.
Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 소계가 생성된다.
| 예시 | 결과 |
|---|---|
| ROLL_UP(A) | A그룹핑 ---> 합계 |
| ROLL_UP(A, B) | A, B그룹핑 ---> A소계/합계 |
| ROLL_UP(A, B, C) | A, B, C그룹핑 ---> (A소계,B소계)/합계 |
CUBE
CUBE는 결합 가능한 모든 값에 대하여 소계와 총계를 생성한다.
따라서 인수 순서가 바뀌어도 수행결과는 동일하다.
ROLLUP에 비해 시스템의 연산 대상이 많아 부담을 주게 된다.
Grouping Columns의 수를 N이라고 했을 때 2의 n승의 소계를 생성한다.
| 결과 | |
|---|---|
| CUBE(A) | A그룹핑 ---> 합계 |
| CUBE(A, B) | A, B그룹핑/A그룹핑/B그룹핑 ---> A소계,B소계 / 합계 |
| CUBE(A, B, C) | A, B, C그룹핑 / A, B그룹핑 / A, C그룹핑 / B, C그룹핑 / A그룹핑 / B그룹핑 / C그룹핑 |
| ---> (A소계,B소계),(A소계),(B소계)/합계 |
GROUPING SETS
ROLLUP이나 CUBE와 달리 계층이 없고 그룹핑된 결과만 보여준다.
괄호로 묶은 집합별로의 집계를 구할수 있다.
| 예시 | 결과 |
|---|---|
| GROUPING SETS(A, ()) | A그룹핑 ---> 합계 |
| GROUPING SETS(A, B, ()) | A그룹핑/B그룹핑 ---> A소계/합계 |
GROUPING
ROLLUP, CUBE, GROUPING SETS 함수를 사용할 때 소계자리에 NULL 대신 텍스트를 쓰게 해주는 함수이다.
윈도우 함수
WINDOW 함수에는 OVER 문구가 키워드로 필수 포함된다.
순위함수
- ROW_NUMBER(): 결과 집합 내에서 각 행에 순번을 부여합니다.
1등 2등 3등 4등 동일해도 순번은 고유하게- RANK(): 결과 집합 내에서 동점 순위를 가질 수 있으며, 동점 순위의 다음 순위를 건너뜁니다.
1등 2등 2등 4등- DENSE_RANK(): 결과 집합 내에서 동점 순위를 가질 수 있으며, 동점 순위의 다음 순위를 건너뛰지 않습니다.
1등 2등 2등 3등
집계함수
- SUM, MIN, COUNT, AVG, MAX
순서함수 (오라클만 가능)
- FIRST_VALUE(): 파티션별 윈도우에서 가장 먼저 나온 값을 구한다.
SELECT DEPTNO, -- 부서 번호 ENAME, -- 직원 이름 SAL, -- 연봉 FIRST_VALUE(ENAME) OVER ( PARTITION BY DEPTNO ORDER BY SAL DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as DEPT_RICH FROM EMP; 1. FIRST_VALUE(ENAME) OVER (...): 이 부분은 윈도우 함수 FIRST_VALUE를 사용하여 직원 이름을 가져옵니다. 2. PARTITION BY DEPTNO: 결과를 부서 번호(DEPTNO)로 파티션(그룹화)합니다. 즉, 각 부서 별로 별도로 작업을 수행합니다. 3. ORDER BY SAL DESC: 각 부서 내에서 연봉(SAL)을 내림차순으로 정렬합니다. 4. ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW: 파티션 내에서 현재 행을 포함하여 그 이전의 모든 행을 범위로 지정합니다. 이것은 현재 행을 기준으로 파티션 내의 첫 번째 행까지를 의미합니다. 5. 결과는 부서별로 연봉이 가장 높은 직원의 이름(DEPT_RICH)을 포함하는 테이블을 반환합니다.
- LAST_VALUE(): 파티션별 윈도우에서 가장 나중에 나온 값을 구한다.
- LAG(): 파티션별 윈도우에서 이전 몇 번째 행의 값을 가져올 수 있다.
직원들을 입사일자가 빠른 기준으로 정렬을 하고, 본인보다 입사일자가 한 명 앞선 사원의 급여를 본인의 급여와 함께 출력한다.- LEAD(): 현재 행 다음의 행에 있는 값을 반환합니다.
- LAG(): 현재 행 이전의 행에 있는 값을 반환합니다.
비율 함수(오라클만 가능) 결과는 0~1사이의 값으로 나옴
- RATIO_TO_REPORT(): 파티션 내 전체 SUM(칼럼)값에 대한 행별 칼럼 값의 백분율을 소수점으로 구할 수 있다.
- PERCENT_RANK(): 파티션별 윈도우에서 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행의 순서별 백분율을 구한다.
- CUME_DIST(): 누적 분포 함수로, 특정 값의 누적 백분위 순위를 계산합니다.
- NTILE(n): 결과 집합을 n개의 동일한 크기의 구간으로 분할합니다.
절차형 SQL
연속적인 실행이나 분기, 반복 등의 제어가 가능한 SQL이다
프로시저, 트리거, 사용자 정의 함수가 있다.
PROCEDURE(프로시저)
- 프로시저란 절차형 SQL을 활용하여 특정 기능을 수행하는 일종의 트랜잭션 언어이며 호출을 통해 실행되어 미리 저장해 놓은 SQL 작업을 수행한다. 여러 프로그램에서 호출하여 사용 가능하고, 시스템의 일일 마감 작업, 일괄 작업 등에 주로 사용된다. 스토어드(Stored) 프로시저라고도 불린다.
- 파라미터는 IN, OUT, INOUT, 매개변수명, 자료형이 올 수 있다. 값을 전달하거나 반환할 때 IN과 OUT, INOUT을 사용한다.
- 프로시저는 처리결과를 반환하지 않거나 한 개 이상의 값을 반환한다.
- header의 끝에는 IS(AS)가 와야하고 IS 와 BEGIN 사이에 BEGIN~END에서 사용할 변수를 선언한다.
- 자신의 스키마에서 프로시저를 만들려면 CREATE PROCEDURE 시스템 권한이 필요
- 다른 스키마 계정에서 프로시저를 만들려면 CREATE ANY PROCEDURE 시스템 권한이 필요
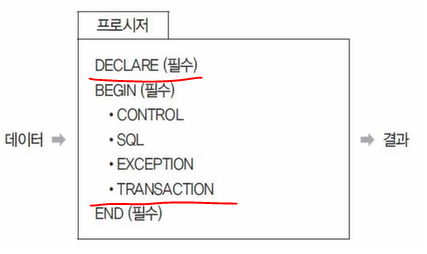
프로시저 생성 :
CREATE PROCEDURE 프로시저명(파라미터)
BEGIN
BODY;
END;| 프로시저 구성 | 내용 |
|---|---|
| DECLARE | 프로시저의 명칭, 변수, 인수, 데이터 타입을 정의하는 선언부 (필수) |
| BEGIN / END | 프로시저의 시작과 종료를 의미 (필수) |
| CONTROL | 조건문 또는 반복문이 삽입, 순차적 처리 |
| SQL | DML, DCL이 삽입돼, 조회, 추가, 수정, 삭제 작업을 수행 |
| EXCEPTION | 구문 실행 중 예외 발생 시 처리 방법 정의 |
| TRANSACTION | 작업들을 DB에 적용할지 취소하리 결정하는 처리부 |
TRIGGER(트리거)
-
트리거는 DB 시스템에서 삽입, 갱신, 삭제 등 이벤트가 발생할 때마다 자동 수행되는 절차형 SQL이다. 무결성 유지, 로그 메시지 출력 등의 목적으로 사용한다. 구문에는 DCL을 사용할 수 없고 DCL이 포함된 프로시저나 함수 호출도 불가능하다.
-
데이터베이스 시스템에서 데이터의 입력, 갱신, 삭제 등의 이벤트가 발생할때마다 관련 작업이 자동으로 수행된다.
-
트리거 문에는 DCL(권한부여)사용 불가
-
트리거 문에는 DDL, DML 사용 가능

트리거 생성 :
CREATE TRIGGER 트리거명 (실행 시기)(옵션) ON 테이블명
REFERENCING (NEW or OLD) AS 테이블명
FOR EACH ROW
BEGIN
BODY;
END;| 트리거 구성 | 내용 |
|---|---|
| DECLARE | 프로시저와 같다. |
| EVENT | 실행되는 조건 명시 |
| BEGIN / END | 프로시저와 같다. |
| CONTROL | 프로시저와 같다. |
| SQL | 프로시저와 같으나 DCL은 삽입될 수 없다. |
| EXCEPTION | 프로시저와 같다. |
| 동작시기 | AFTER-테이블 변경 후 / BEFORE-테이블 변경 전 |
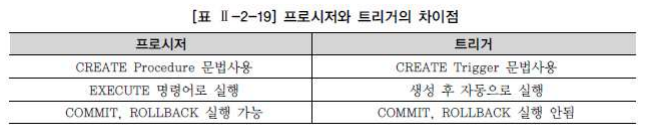
프로시저와 트리거의 차이점
프로시저는 BEGIN ~ END 절 내에 COMMIT, ROLLBACK 과 같은 트랜잭션 종료 명령어를 사용할
수 있지만, 데이터베이스 트리거는 BEGIN ~ END 절 내에 사용할 수 없다.
지점명 변경 시 사원정보 테이블 자동 갱신
CREATE OR REPLACE TRIGGER trg_update_branch_name
AFTER UPDATE OF 지점명 ON 업무지점2
FOR EACH ROW
BEGIN
UPDATE 사원정보2
SET 지점명 = :NEW.지점명
WHERE 지점번호 = :OLD.지점번호;
END;
주문 금액 자동 계산 (주문 → 주문상세)
CREATE OR REPLACE TRIGGER trg_order_amount
AFTER INSERT OR UPDATE OR DELETE ON 제품주문상세
FOR EACH ROW
BEGIN
-- 주문금액 다시 계산
UPDATE 주문
SET 주문총금액 = (
SELECT SUM(수량 * 단가)
FROM 제품주문상세 d
JOIN 제품 p ON d.제품번호 = p.제품번호
WHERE d.주문번호 = :NEW.주문번호
)
WHERE 주문번호 = :NEW.주문번호;
END;사용자 정의 함수
프로시저와 유사하며 RETURN을 이용하여 처리결과를 1개 반환한다.
예시) 사원의 급여(sal)에 보너스(10%)를 더한 금액을 반환하는 함수
CREATE OR REPLACE FUNCTION get_bonus_salary(p_sal NUMBER)
RETURN NUMBER
IS
v_total NUMBER;
BEGIN
-- 보너스 10%를 더한 급여 계산
v_total := p_sal + (p_sal * 0.1);
RETURN v_total;
END;
-- SELECT 문 안에서 함수 사용
SELECT ename, sal, get_bonus_salary(sal) AS total_salary
FROM emp;프로시저와 사용자 정의 함수의 차이점
프로시저는 DML, DCL까지 가능하고 반환값이 여러 개 가능하지만, 사용자 정의 함수는 반드시 1개의 값만 반환하며 SELECT 안에서만 사용할 수 있다
| 구분 | 프로시저 (Procedure) | 사용자 정의 함수 (User Defined Function) |
|---|---|---|
| 반환값 | 없거나 1개 이상 가능 | 1개 |
| 파라미터 | 입력, 출력 가능 | 입력만 가능 |
| 사용 가능 명령문 | DML, DCL 사용 가능 | SELECT 로 제한 |
| 호출 | 프로시저, 사용자 정의 함수 모두에서 호출 가능 | 사용자 정의 함수 내에서만 호출 가능 |
| 사용 방법 | 실행문으로 직접 실행 | DML 문장에 포함하여 사용 |
2과목 3장 최적화 기본원리
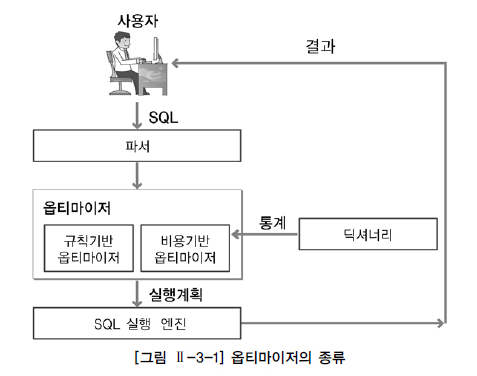
옵티마이저와 실행계획
옵티마이저(Optimizer)는 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할을 수행한다. 이러한 최적의 실행 방법을 실행계획(Execution Plan)이라고 한다.
실행계획을 생성한다는 것은 SQL을 어떤 순서로 어떻게 실행할 지를 결정하는 작업이다.
규칙기반 옵티마이저(RBO, Rule Based Optimizer)
규칙(우선 순위)을 가지고 실행계획을 생성한다.
이용 가능한 인덱스 유무와 종류, 연산자(=, <, <>, LIKE, BETWEEN 등)의 종류, 참조하는 객체(힙 테이블, 클러스터 테이블 등)의 종류 따라 우선 순위(규칙)가 정해져 있고, 이 우선 순위를 기반으로 실행계획을 생성한다.
실행계획을 생성한다는 것은 SQL을 어떤 순서로 어떻게 실행할 지를 결정하는 작업이다.
비용기반 옵티마이저(CBO, Cost Based Optimizer)
비용기반 옵티마이저는 이러한 규칙기반 옵티마이저의 단점을 극복하기 위해서 출현하였다. 비용기반 옵티마이저는 SQL문을 처리하는데 필요한 비용이 가장 적은 실행계획을 선택하는 방식이다. 여기서 비용이란 SQL문을 처리하기 위해 예상되는 소요시간 또는 자원 사용량을 의미한다. 비용기반 옵티마이저는 비용을 예측하기 위해서 규칙기반 옵티마이저가 사용하지 않는 테이블, 인덱스, 칼럼 등의 다양한 객체 통계정보와 시스템 통계정보 등을 이용한다. 통계정보가 없는 경우 비용기반 옵티마이저는 정확한 비용 예측이 불가능해져서 비효율적인 실행계획을 생성할 수 있다. 그렇기 때문에 정확한 통계정보를 유지하는 것은 비용기반 최적화에서 중요한 요소이다.
규칙기반 옵티마이저는 조건절에서 ‘=’ 연산자와 'BETWEEN' 연산자가 사용되면 규칙에 따라 ‘=’ 칼럼의 인덱스를 사용하는 것이 보다 적은 일량 즉, 보다 적은 처리 범위로 작업을 할 것이라고 판단한다. 그러나 실제로는 ‘BETWEEN’ 칼럼을 사용한 인덱스가 보다 일량이 적을 수 있다. 단순한 몇 개의 규칙만으로 현실의 모든 사항을 정확히 예측할 수는 없다.
인덱스 기본
조인 수행 원리
정규형
제1정규형
제1 정규형은 릴레이션에 속하는 속성의 속성 값이 모두 원자값(Atomic Value)만으로 구성되어야 한다.
원자값이란 더 이상 쪼개질 수 없는 단위를 말한다.
제1 정규형에서 이상현상이 발생하는 이유는, 기본키(primary key)가 아닌 속성들이 기본키에 완전 함수 종속되지 못하고 부분 함수 종속되어 있기 때문이다. 즉, 기본키의 일부 속성에만 의존하고 있기 때문이다.
- 삽입 이상 : 학생이 새 과목을 수강 신청할 때 반드시 학생의 학과와 지도교수를 알아야 한다. (불필요한 정보)
- 삭제 이상 : 300번 학생이 C400 과목을 취소하면, 해당 과목에 대한 정보가 모두 사라진다.
- 갱신 이상 : 100번 학생이 지도교수를 변경할 때, P1인 행을 모두 찾아서 변경해주어야 한다.
제2정규형
제2 정규형은 제1 정규형이면서, 기본키(primary key)에 속하지 않은 속성 모두가 기본키에 완전 함수 종속인 정규형을 말한다.
제2 정규형에도 여전히 이상현상이 존재한다. '이행적 함수 종속성' 때문이다. 이행적 함수 종속성은 속성이 A→B이고, B→C이면서 A→C의 관계에 있는 것을 말한다.
- 삽입 이상 : 지도교수가 학과에 소속되어 있음을 추가할 때 반드시 지도 학생이 있어야 한다. (불필요한 정보 필요)
- 삭제 이상 : 300번 학생이 자퇴하는 경우 P3 교수의 학과 정보가 사라진다.
- 갱신 이상 : 지도교수의 학과가 변경되는 경우 모두 찾아서 변경시켜주어야 한다. (지도교수가 동일한 학생이 여러 명 있는 경우)
제3정규형
제3 정규형은 제2 정규형이면서, 이행적 함수 종속성을 제거한 정규형을 말한다.
즉, 기본키에 속하지 않은 모든 속성이 기본키에 이행적 함수 종속이 아닐 때 제3 정규형이라고 한다. 다르게 표현하면, 기본키 이외의 속성이 그 외 다른 속성을 결정할 수 없는 것이다.
BCNF (Boyce and Codd Normal Form)은 제3 정규형을 조금 더 강화시킨 개념이다. 강한 제3 정규형이라고도 한다. 이상현상을 해결하기 위해서 모든 결정자는 항상 후보키가 되도록 릴레이션을 분해해주면 강한 제3 정규형, 즉 BCNF를 만족하게 된다.
- 삽입 이상 : 새로운 교수가 특정 과목을 담당한다는 새로운 정보를 추가할 수 없다. 적어도 한 명 이상의 수강 학생이 필요하다.
- 삭제 이상 : 학번 100이 C234 과목을 취소하면, P2가 C234 과목을 담당한다는 정보도 삭제된다.
- 갱신 이상 : P1의 과목이 변경되면 P1인 행을 모두 찾아 변경시켜주어야 한다.
<참고자료>
정규형-Rebro의 코딩 일기장:티스토리
