프로젝트에 태그 기능을 도입하면서 생각보다 많은 설계 고민이 필요했다. 단순히 태그를 저장하고 보여주는 것을 넘어서, 사용자 경험과 검색 효율성 사이의 균형을 찾아야 했다.
초기 요구사항
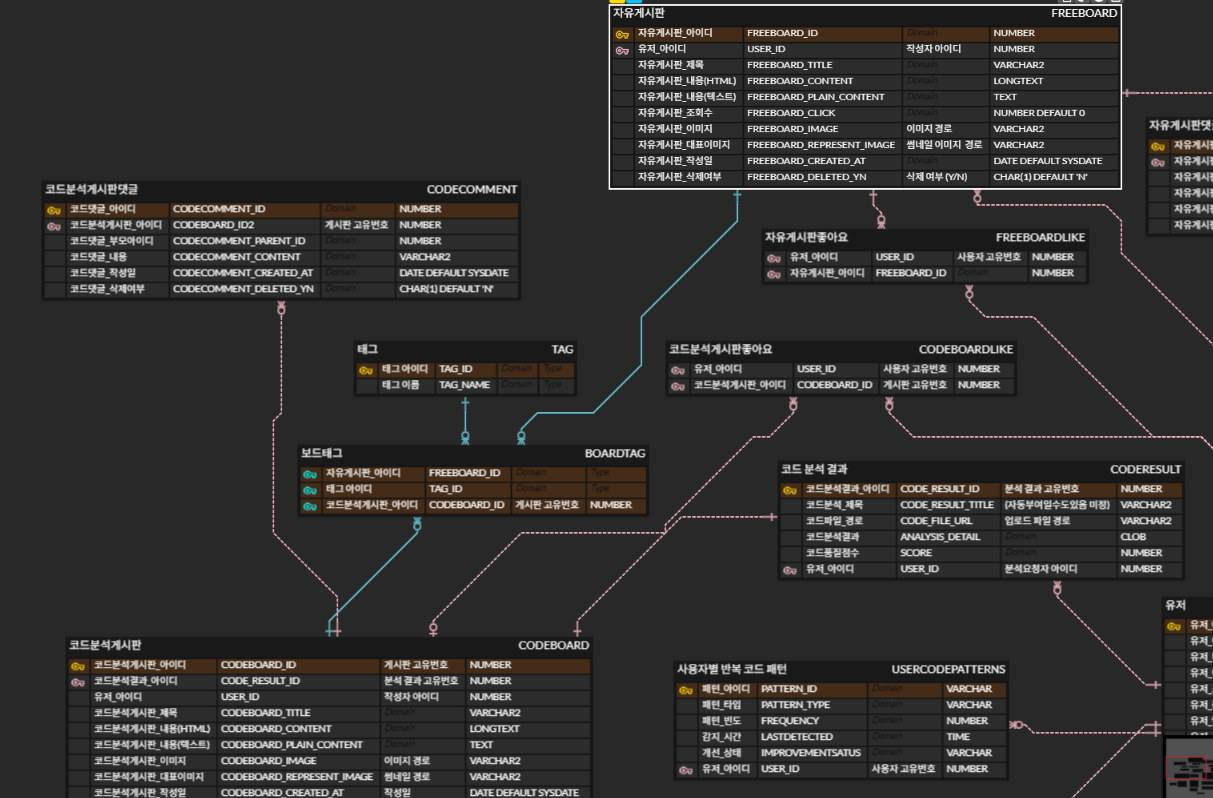
(위 ERD 설계는 오류가 있습니다. 아래에 수정된 ERD를 참고하세요.)
자유게시판과 코드게시판 두 곳에서 태그를 사용할 예정이었다.
사용자들은 "유머", "일상" 같은 일반적인 태그부터 "Spring", "React" 같은 기술 태그까지 자유롭게 입력할 수 있어야 했다. 태그를 클릭하면 해당 태그가 달린 게시글들을 검색할 수 있어야 하고, 입력 시 자동완성 기능도 필요했다.
첫 번째 고민 : 태그 생성 권한과 관리 방식
태그를 어떻게 관리할 것인가에 대한 고민이 먼저 있었다.
관리자가 미리 정의한 태그만 사용하게 할 것인지, 사용자가 자유롭게 생성하게 할 것인지 결정해야 했다.
Netflix 기술 블로그처럼 엄격하게 관리되는 환경에서는 사전 정의된 태그만 사용한다. 태그의 일관성이 보장되고 관리가 쉽지만, 사용자의 자유도는 낮아진다. 반면 Stack Overflow나 Medium 같은 커뮤니티 플랫폼은 사용자가 자유롭게 태그를 생성할 수 있다.
ㅋ, 이것은정말로엄청나게길고의미없는태그인데과연누가이런태그를만들까요하하하하...50자,
!@#$%^&*(), www.광고.com, fuck, 010-1234-5678, 🤗와 같은 태그들을 자유롭게 만들 수 있게 할지, 아니면 어느 정도 통제할지 결정이 필요하다. 너무 엄격하면 사용자 불편이 크고, 너무 느슨하면 시스템 품질이 떨어진다.
"'; DROP TABLE tags; --", <script>alert('xss')</script>, SQL Injection, XSS 시도 같은 보안에 위협적인 요소도 제어해야 한다.
나는 서비스는 개발자 커뮤니티 성격이 강하지만, 자유 게시판에서는 다양한 주제와 기술이 논의될 것으로 예상했다. 관리자가 모든 기술 스택과 주제를 미리 예측해서 태그로 만들어두는 것은 비현실적이었다. 따라서 자유 생성 방식을 선택했다. 사용자가 입력한 태그가 데이터베이스에 없으면 자동으로 생성하고, 이미 존재하면 기존 태그를 재사용하는 방식이다.
두 번째 고민 : 대소문자 처리
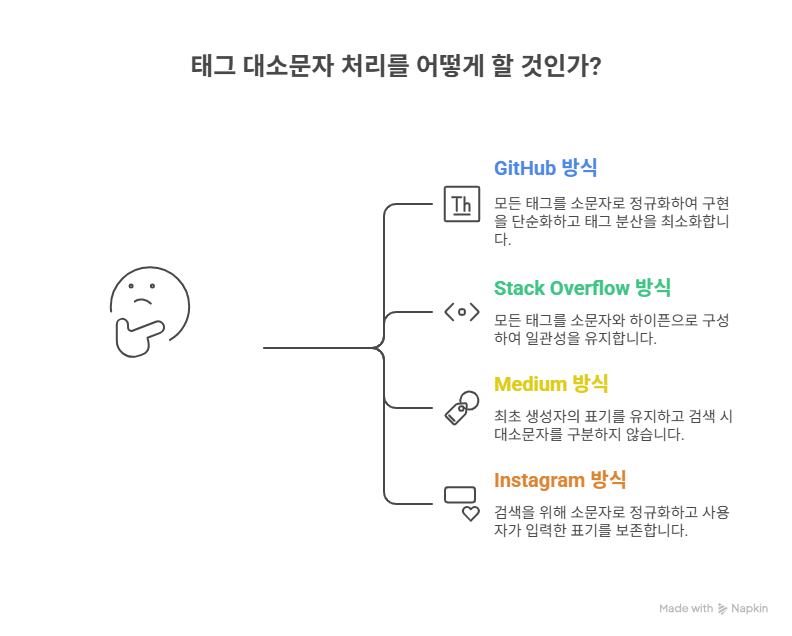
가장 큰 고민은 대소문자 처리였다. Spring과 spring을 같은 태그로 볼 것인가, 다른 태그로 볼 것인가. 한 사용자는 React라고 쓰고 싶고, 다른 사용자는 리액트나 react라고 쓰고 싶다면 어떻게 해야 하는가.
대기업 서비스들의 사례를 살펴봤다. GitHub는 모든 태그를 소문자로 정규화한다. 대소문자 구분 없이 완전히 통일된 방식이다. Stack Overflow도 마찬가지로 모든 태그가 소문자와 하이픈으로만 구성된다. 개발자 커뮤니티 특성상 일관성을 중시하는 선택이었다.
Medium은 최초 생성자의 표기를 유지하는 방식을 사용한다. JavaScript를 먼저 만든 사람이 있으면 자동완성에서 JavaScript가 보이고, javascript를 입력해도 JavaScript 태그로 연결된다. 다만 검색 시에는 대소문자 구분 없이 동작한다.
반면 Instagram과 Twitter 같은 SNS는 다른 접근을 한다. 해시태그 자체는 대소문자를 구분하지 않지만, 각 게시물에는 사용자가 입력한 표기 그대로 보여준다. #Spring과 #spring은 검색 결과가 같지만, 게시물에는 작성자가 입력한 형태로 표시된다.
처음에는 GitHub 방식의 완전 정규화를 고려했다. 모든 태그를 소문자로 저장하면 구현이 단순하고, 태그 분산도 최소화된다. 하지만 한 가지 문제가 있었다. react를 선호하는 사람이 자동완성에서 React만 보인다면 불만을 가질 수 있다. 게다가 스프링과 Spring은 근본적으로 다른 문자이므로, 한글과 영문까지 통합할 수는 없었다.
최종적으로 Instagram 방식을 선택했다. 검색과 중복 체크는 소문자로 정규화하되, 각 사용자가 입력한 표기는 보존하는 방식이다. Spring을 먼저 입력한 사람이 있다면, 나중에 spring을 입력한 사람도 같은 태그로 연결되지만, 자기 게시글에는 spring으로 표시된다.
세 번째 고민 : 자동완성 전략
자동완성에서는 어떤 표기를 보여줄 것인가도 중요한 문제였다. spring 태그에 대해 100명이 Spring이라고 입력하고 5명이 spring이라고 입력했다면, 자동완성에서는 Spring을 보여주는 것이 합리적이다.
이를 위해 BOARDTAG 테이블에서 각 TAG_ID별로 TAG_DISPLAY_NAME을 그룹핑하고, 가장 많이 사용된 표기를 찾는다. 사용자가 spr을 입력하면, TAG 테이블에서 spr로 시작하는 태그들을 찾고, 각 태그의 가장 인기있는 표기를 자동완성 목록으로 제공한다.
다만 이 방식은 자동완성 요청마다 GROUP BY 연산이 발생한다는 문제가 있다. 초기에는 태그 개수가 적어서 괜찮지만, 태그가 수만 개로 늘어나면 성능 문제가 될 수 있다. 이는 나중에 Redis 캐싱이나 TAG 테이블에 POPULAR_DISPLAY_NAME 컬럼을 추가하는 방식으로 최적화할 수 있다.
입력하는 문자열에 따라 기존에 생성되어 있던 해시태그를 추천받아 선택을 유도하는 기능이 있으므로 맨 처음 만든 사람이 괴짜라서 sPrInG 이라고 입력했다면 두번째 입력할 때 자동 완성이 sPrInG를 추천하겠지만 사용 빈도가 높은 태그를 자동 완성으로 추천할 것이므로 시간이 지나면 가장 많은 사용자가 주로 선택하는 태그가 추천될 것 이다.
(자동완성 검색어에 매칭되는 태그가 50개라면 50번의 COUNT 쿼리가 발생하므로 자동완성 정렬 성능에 대해서는 추가적으로 고려해야한다)
네 번째 고민 : N+1 쿼리 문제와 해결
설계 과정에서 반드시 해결해야 할 성능 문제가 하나 있었다. 게시글 목록을 조회할 때 각 게시글마다 태그를 별도로 조회하면 N+1 쿼리 문제가 발생한다.
게시글 100개를 조회하는 상황을 가정해보자. 먼저 게시글 목록을 가져오는 쿼리가 1번 실행된다. 그 다음 각 게시글의 태그를 조회하기 위해 100번의 추가 쿼리가 실행된다. 총 101번의 데이터베이스 요청이 발생하는 것이다.
이를 해결하기 위해 IN 쿼리를 사용한다. 게시글 목록을 먼저 조회하고, 모든 게시글 ID를 모은다. 그 다음 BOARDTAG 테이블에서 해당 ID들에 속하는 모든 태그를 한 번의 쿼리로 가져온다. 조회된 태그들을 게시글 ID별로 그룹핑하면 각 게시글에 어떤 태그들이 연결되어 있는지 알 수 있다. 이렇게 하면 게시글 100개를 조회할 때 총 2번의 쿼리만 실행된다.
다섯 번째 고민 : 동시성 문제 처리
여러 사용자가 동시에 같은 태그를 생성하려 할 때 문제가 발생할 수 있다. 사용자A와 사용자B가 동시에 2028 로스앤젤레스 올림픽 태그를 입력한다고 가정하자. 두 요청 모두 TAG 테이블에서 2028 로스앤젤레스 올림픽가 없음을 확인하고 새로 저장하려 시도한다. TAG_NAME에는 UNIQUE 제약조건이 걸려있으므로 UNIQUE 제약 조건 위반 예외가 발생하여 둘 중 하나는 실패한다.
이를 처리하기 위해 예외를 잡아서 재조회하는 로직을 추가한다. 저장 시도가 실패하면 다른 요청이 이미 생성했다는 의미이므로, 다시 조회해서 방금 생성된 태그를 가져온다. 이렇게 하면 동시성 상황에서도 안전하게 동작한다.
public Tag getOrCreateTag(String tagName) {
String normalizedName = tagName.toLowerCase().trim();
Optional<Tag> existingTag = tagRepository.findByTagName(normalizedName);
if (existingTag.isPresent()) {
return existingTag.get();
}
try {
return tagRepository.save(Tag.builder().tagName(normalizedName).build());
} catch (DataIntegrityViolationException e) {
// UNIQUE 제약 위반 시 재조회
return tagRepository.findByTagName(normalizedName)
.orElseThrow(() -> new RuntimeException("태그 생성 실패"));
}
}여섯 번째 고민 : 사용 되지 않는 태그 삭제
게시글이 삭제되면 BOARDTAG 레코드도 삭제되지만, TAG 테이블의 레코드는 남는다.
// 게시글 삭제 시
@Transactional
public void deletePost(Long postId) {
boardTagRepository.deleteByCodeboardId(postId); // BOARDTAG 삭제
codeBoardRepository.deleteById(postId);
// TAG 테이블의 레코드는 그대로 남음
}더 이상 사용되지 않는 TAG 레코드가 계속 쌓인다.
해결방법: 스케줄러로 주기적 정리
java@Scheduled(cron = "0 0 3 * * *") // 매일 새벽 3시
public void cleanupUnusedTags() {
jdbcTemplate.update("""
DELETE FROM TAG
WHERE TAG_ID NOT IN (
SELECT DISTINCT TAG_ID FROM BOARDTAG
UNION
SELECT DISTINCT TAG_ID FROM 자유게시판태그
)
""");
}일곱 번째 고민 : 태그 검색 성능
태그를 누르거나 해당 태그명을 검색하여 게시물들을 찾을 수 있다.
게시글이 10만개면 BOARDTAG도 10만개 스캔해야하는데 인덱스를 추가하여
API 응답 속도가 100ms 이내로 동작하게 만들고자 했다.
CREATE INDEX IDX_BOARDTAG_TAG_ID ON BOARDTAG(TAG_ID, 코드분석게시판_아이디);
CREATE INDEX IDX_BOARDTAG_CODEBOARD_ID ON BOARDTAG(코드분석게시판_아이디);동작 원리
태그 저장 과정
사용자A가 코드게시판에 게시글을 작성하면서 Spring과 Backend를 태그로 입력했다고 가정하자. 시스템은 먼저 각 입력값을 소문자로 정규화한다. Spring은 spring으로, Backend는 backend로 변환된다.
정규화된 spring이 TAG 테이블에 존재하는지 확인한다. 처음 입력된 태그라면 TAG 테이블에 새로운 레코드를 생성한다. 이미 다른 사람이 만든 태그라면 기존 레코드의 TAG_ID를 재사용한다. backend도 같은 방식으로 처리한다.
TAG_ID를 확보한 후에는 CODEBOARD_TAG 테이블에 관계를 저장한다. 여기서 중요한 점은 사용자가 입력한 원본 표기를 TAG_DISPLAY_NAME 컬럼에 그대로 저장한다는 것이다. 게시글 ID가 100번이라면, (100, TAG_ID, Spring)과 (100, TAG_ID, Backend)가 저장된다.
나중에 사용자B가 같은 주제로 글을 쓰면서 spring과 백엔드를 태그로 입력했다면, spring은 이미 TAG 테이블에 존재하므로 새로 생성하지 않고 기존 TAG_ID를 재사용한다. 백엔드는 backend와 다른 단어이므로 TAG 테이블에 새로운 레코드로 추가된다. CODEBOARD_TAG에는 (101, TAG_ID, spring)과 (101, TAG_ID, 백엔드)가 저장된다.
게시글 조회와 표시
사용자A의 게시글을 조회할 때는 CODEBOARD_TAG 테이블에서 CODEBOARD_ID가 100번인 레코드들을 찾는다. TAG_DISPLAY_NAME 컬럼에서 Spring, Backend를 가져와 화면에 표시한다. 사용자B의 게시글을 조회할 때는 CODEBOARD_ID가 101번인 레코드들을 찾아 spring, 백엔드를 표시한다.
각 게시글마다 작성자가 입력한 표기가 그대로 보인다. TAG 테이블에는 spring으로 정규화되어 있지만, 사용자A는 자기 게시글에서 Spring을 보고, 사용자B는 자기 게시글에서 spring을 본다. 이것이 Instagram 방식의 핵심이다.
태그 검색
사용자가 게시글 목록에서 Spring 태그를 클릭했다고 가정하자. 시스템은 클릭된 태그명 Spring을 소문자로 정규화해서 spring으로 만든다. TAG 테이블에서 TAG_NAME이 spring인 레코드를 찾아 TAG_ID를 얻는다.
그 TAG_ID를 사용해서 CODEBOARD_TAG 테이블을 조회한다. 해당 TAG_ID와 연결된 모든 CODEBOARD_ID를 찾으면, 그것이 검색 결과가 된다. 사용자A의 게시글 100번과 사용자B의 게시글 101번 모두 TAG_ID가 같으므로 함께 검색된다.
검색 결과 화면에서도 각 게시글의 태그는 작성자가 입력한 표기 그대로 보인다. 게시글 100번에는 Spring이 표시되고, 게시글 101번에는 spring이 표시된다. 검색은 통합되지만 표기는 보존되는 것이다.
sPring이나 SPRING 같은 다른 대소문자 조합으로 태그를 클릭해도 마찬가지다. 모두 spring으로 정규화되어 같은 TAG_ID를 찾게 되므로, 동일한 검색 결과를 얻는다.
자동완성 동작
사용자가 태그 입력란에 spr을 입력하면 자동완성이 작동한다. TAG 테이블에서 TAG_NAME이 spr로 시작하는 태그들을 찾는다. spring이 발견되면 해당 TAG_ID를 가져온다.
이제 이 태그가 실제로 어떤 표기로 가장 많이 사용되었는지 확인한다. CODEBOARD_TAG와 FREEBOARD_TAG 테이블에서 해당 TAG_ID의 모든 TAG_DISPLAY_NAME을 조회하고, 각 표기의 사용 횟수를 센다. Spring이 50번, spring이 5번, sPring이 1번 사용되었다면, 가장 많이 사용된 Spring을 자동완성 목록에 보여준다.
하지만 이것은 추천일 뿐 강제가 아니다. 사용자가 자동완성을 무시하고 spring이나 sPring을 직접 입력해도 된다. 어떤 표기를 입력하든 소문자로 정규화되어 같은 TAG_ID로 연결되므로, 검색 시에는 모두 함께 묶인다.
ERD 재설계
글 상단을 보면 알다시피 처음에는 BOARDTAG 테이블 하나로 두 게시판을 모두 처리하려 했다. 리액트나 스프링 같은 기술 태그는 고작 태그일 뿐이고 변하지도 않을 것이므로, 같은 태그를 두 테이블에 중복으로 저장하는 것이 비효율적으로 느껴졌다.
CREATE TABLE BOARDTAG (
FREEBOARD_ID BIGINT,
CODEBOARD_ID BIGINT,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL
);자유게시판 게시글이면 FREEBOARD_ID에 값이 들어가고 CODEBOARD_ID는 NULL이 되고, 코드게시판 게시글이면 그 반대가 된다. 두 게시판의 게시글을 전체 조회하는 경우는 없기 때문에 각 게시판 내에서만 쿼리가 발생한다는 점에서 하나의 테이블에 복합키 사용은 충분히 합리적인 접근처럼 보였다.
데이터베이스 정규화 관점에서 보면 BOARDTAG_ID라는 인조키 대신 자연키인 (FREEBOARD_ID, CODEBOARD_ID, TAG_ID)를 복합키로 사용하는 것이 더 자연스러워 보였다. 불필요한 AUTO_INCREMENT 컬럼을 추가하지 않아도 되고, 세 컬럼의 조합으로 각 레코드를 유일하게 식별할 수 있기 때문이다.
그러나 MySQL과 Oracle 모두 기본키에는 NULL 값을 허용하지 않는다. 자유게시판 게시글의 태그를 저장할 때 CODEBOARD_ID는 NULL이 되고, 코드게시판 게시글의 태그를 저장할 때 FREEBOARD_ID는 NULL이 된다. NULL이 포함된 복합키는 성립할 수 없다.
또한 중복 방지를 표현할 수 없다. 같은 게시글에 같은 태그를 두 번 다는 것을 막으려면 적절한 UNIQUE 제약조건이 필요하다. 자유게시판에서는 (FREEBOARD_ID, TAG_ID)가 유일해야 하고, 코드게시판에서는 (CODEBOARD_ID, TAG_ID)가 유일해야 한다. 하지만 복합키로는 이러한 조건부 유일성을 표현할 수 없다.
해결방법 1 : 단일 테이블 + 인조키
BOARDTAG_ID라는 인조키를 기본키로 추가하고, UNIQUE 제약조건으로 중복을 방지하기.
CREATE TABLE BOARDTAG (
BOARDTAG_ID BIGINT PRIMARY KEY AUTO_INCREMENT,
FREEBOARD_ID BIGINT,
CODEBOARD_ID BIGINT,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL,
CONSTRAINT UK_BOARDTAG_FREEBOARD UNIQUE (FREEBOARD_ID, TAG_ID),
CONSTRAINT UK_BOARDTAG_CODEBOARD UNIQUE (CODEBOARD_ID, TAG_ID),
CONSTRAINT CHK_BOARDTAG_ONE_FK
CHECK (
(FREEBOARD_ID IS NOT NULL AND CODEBOARD_ID IS NULL) OR
(FREEBOARD_ID IS NULL AND CODEBOARD_ID IS NOT NULL)
)
);기능적으로는 완벽하게 동작한다. CHECK 제약조건으로 둘 중 하나만 값을 가지도록 강제하고, 각 게시판별로 UNIQUE 제약조건으로 중복을 방지한다. TAG 테이블도 하나만 유지하면 되므로 초기 의도대로 같은 태그를 중복 저장하지 않는다.
하지만 몇 가지 불편한 점들이 있다. NULL 컬럼이 존재하면 인덱스 크기가 커지고, WHERE 절에서 NULL 체크가 필요할 수 있다. CHECK 제약조건도 매번 검증 오버헤드를 발생시킨다. 코드를 작성할 때도 항상 두 컬럼을 체크해야 하므로 로직이 복잡해진다.
public String getBoardType(BoardTag boardTag) {
if (boardTag.getFreeboardId() != null) {
return "FREEBOARD";
} else if (boardTag.getCodeboardId() != null) {
return "CODEBOARD";
}
return "UNKNOWN";
}방법 2 : 테이블 분리
간 테이블을 게시판별로 분리하기
CREATE TABLE CODEBOARD_TAG (
CODEBOARD_ID BIGINT NOT NULL,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL,
PRIMARY KEY (CODEBOARD_ID, TAG_ID),
FOREIGN KEY (CODEBOARD_ID) REFERENCES CODEBOARD(CODEBOARD_ID) ON DELETE CASCADE,
FOREIGN KEY (TAG_ID) REFERENCES TAG(TAG_ID) ON DELETE CASCADE
);
CREATE TABLE FREEBOARD_TAG (
FREEBOARD_ID BIGINT NOT NULL,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL,
PRIMARY KEY (FREEBOARD_ID, TAG_ID),
FOREIGN KEY (FREEBOARD_ID) REFERENCES FREEBOARD(FREEBOARD_ID) ON DELETE CASCADE,
FOREIGN KEY (TAG_ID) REFERENCES TAG(TAG_ID) ON DELETE CASCADE
);테이블을 분리하면 NULL 문제가 완전히 사라진다. 복합 기본키를 자연스럽게 사용할 수 있고, CHECK 제약조건도 필요 없다. UNIQUE 제약조건을 별도로 추가할 필요도 없다. 복합 기본키 자체가 중복을 방지하기 때문이다.
성능 비교
먼저 인덱스 크기를 살펴보면, 옵션 1은 NULL 값이 인덱스에 포함되어 공간을 차지한다. FREEBOARD_ID 인덱스의 절반은 NULL이고, CODEBOARD_ID 인덱스의 절반도 NULL이다. 옵션 2는 모든 값이 NOT NULL이므로 인덱스가 더 작고 효율적이다.
쿼리 실행 속도는 거의 차이가 없다. 게시글 수천 개 수준에서는 NULL 체크 오버헤드가 체감되지 않는다. 다만 옵션 2의 쿼리가 조금 더 단순하다.
통계 쿼리에서는 차이가 조금 더 명확하다. 전체 태그 사용 빈도를 계산할 때 옵션 1은 단순히 BOARDTAG를 GROUP BY하면 되지만, 옵션 2는 UNION이 필요하다. 하지만 이러한 통계 쿼리는 자주 실행되지 않는다. 스케줄러로 주기적으로 계산해서 TAG 테이블의 TAG_COUNT 컬럼에 저장해두면, 실시간으로 계산할 필요가 없다. 자동완성 같은 빈번한 작업은 TAG 테이블만 조회하면 되므로 중간 테이블 구조와 무관하다.
결국 테이블 분리 방식을 선택했다. 성능 차이는 미미하거나 거의 없는 반면, 코드 명확성과 유지보수성에서 압도적으로 유리했다.
테이블을 분리하면 NULL 처리 로직이 완전히 사라진다. CHECK 제약조건도 필요 없고, 복합 기본키로 중복 방지가 자동으로 처리된다. 쿼리가 더 단순하고 명확해지며, 인덱스도 더 작고 효율적이다.
같은 태그를 두 테이블에 저장하는 것이 비효율적으로 느껴질 수 있지만, 실제로는 TAG 테이블은 하나만 존재한다. CODEBOARD_TAG와 FREEBOARD_TAG는 단지 연결 정보만 저장할 뿐이다. "Spring" 태그 자체는 TAG 테이블에 한 번만 저장되고, 중간 테이블들은 "어느 게시글이 어떤 태그를 사용하는가"라는 관계만 기록한다. 그리고 사용자가 입력한 표기(TAG_DISPLAY_NAME)도 함께 저장한다.
-- TAG 테이블: 정규화된 태그 정의 (소문자)
TAG_ID | TAG_NAME | CREATED_AT
1 | spring | 2025-01-01 10:00:00
2 | react | 2025-01-01 10:05:00
3 | 유머 | 2025-01-01 10:10:00
4 | javascript | 2025-01-01 10:15:00
5 | 일상 | 2025-01-01 10:20:00
-- CODEBOARD_TAG: 코드게시판의 게시글-태그 관계
CODEBOARD_ID | TAG_ID | TAG_DISPLAY_NAME
100 | 1 | Spring -- 사용자A가 "Spring"이라고 입력
100 | 2 | React -- 사용자A가 "React"라고 입력
101 | 1 | spring -- 사용자B가 "spring"이라고 입력
101 | 4 | JavaScript -- 사용자B가 "JavaScript"라고 입력
102 | 2 | react -- 사용자C가 "react"라고 입력
102 | 4 | JS -- 사용자C가 "JS"라고 입력 (javascript의 다른 표기)
-- FREEBOARD_TAG: 자유게시판의 게시글-태그 관계
FREEBOARD_ID | TAG_ID | TAG_DISPLAY_NAME
200 | 3 | 유머 -- 사용자D가 "유머"라고 입력
200 | 5 | 일상 -- 사용자D가 "일상"라고 입력
201 | 1 | 스프링 -- 사용자E가 "스프링"이라고 입력 (한글 표기, spring과 다른 TAG_ID)
201 | 3 | 유머 -- 사용자E가 "유머"라고 입력
202 | 5 | 일상 -- 사용자F가 "일상"이라고 입력이 구조는 명확하고, 안전하며, 유지보수하기 쉽다. 초기에는 하나의 테이블로 통합하려는 욕심이 있었지만, 때로는 명확한 분리가 더 나은 선택이다. 데이터베이스 설계에서 지나친 통합은 오히려 복잡성을 증가시킬 수 있다.
데이터베이스 설계
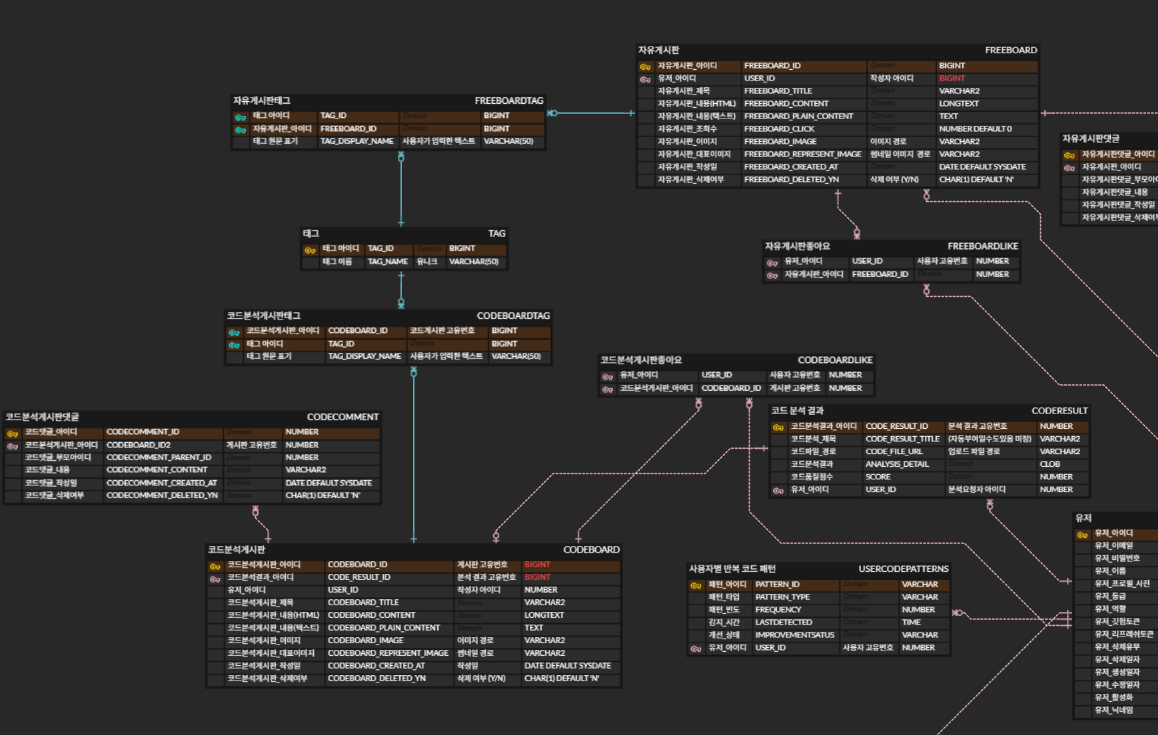
-- TAG 테이블
CREATE TABLE TAG (
TAG_ID BIGINT PRIMARY KEY AUTO_INCREMENT,
TAG_NAME VARCHAR(50) NOT NULL UNIQUE
);
CREATE INDEX IDX_TAG_NAME ON TAG(TAG_NAME);
-- CODEBOARD_TAG 테이블
CREATE TABLE CODEBOARD_TAG (
CODEBOARD_ID BIGINT NOT NULL,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL,
PRIMARY KEY (CODEBOARD_ID, TAG_ID),
CONSTRAINT FK_CODEBOARD_TAG_CODEBOARD
FOREIGN KEY (CODEBOARD_ID)
REFERENCES CODEBOARD(CODEBOARD_ID)
ON DELETE CASCADE,
CONSTRAINT FK_CODEBOARD_TAG_TAG
FOREIGN KEY (TAG_ID)
REFERENCES TAG(TAG_ID)
ON DELETE CASCADE
);
CREATE INDEX IDX_CODEBOARD_TAG_TAG ON CODEBOARD_TAG(TAG_ID);
-- FREEBOARD_TAG 테이블
CREATE TABLE FREEBOARD_TAG (
FREEBOARD_ID BIGINT NOT NULL,
TAG_ID BIGINT NOT NULL,
TAG_DISPLAY_NAME VARCHAR(50) NOT NULL,
PRIMARY KEY (FREEBOARD_ID, TAG_ID),
CONSTRAINT FK_FREEBOARD_TAG_FREEBOARD
FOREIGN KEY (FREEBOARD_ID)
REFERENCES FREEBOARD(FREEBOARD_ID)
ON DELETE CASCADE,
CONSTRAINT FK_FREEBOARD_TAG_TAG
FOREIGN KEY (TAG_ID)
REFERENCES TAG(TAG_ID)
ON DELETE CASCADE
);
CREATE INDEX IDX_FREEBOARD_TAG_TAG ON FREEBOARD_TAG(TAG_ID);참고자료
