
문제 설명
H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다. 위키백과1에 따르면, H-Index는 다음과 같이 구합니다.
어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h의 최댓값이 이 과학자의 H-Index입니다.
어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요.
제한 사항
- 과학자가 발표한 논문의 수는 1편 이상 1,000편 이하입니다.
- 논문별 인용 횟수는 0회 이상 10,000회 이하입니다.
함정
이 문제에는 함정이 존재한다. 주의하자.
- 이 부분을 주의하자. 문제에서 말한대로 하나하나 따라야 한다.

-
인용된 횟수는 리스트(citations)의 원소값이 아닐 수 있다.
처음에 왜 해도 안되지? 라며 고민하다 보니 내가 짠 로직에 오류가 있었다.
바로 오직 원소 값만을 인용된 횟수로 고려하여 h = citations[i] 이렇게 코드를 작성했었다.
예를 들어 [1,1,4,5,6] 인 경우, h=3이다. 3번 이상 인용된 논문은 [4,5,6]으로 3개 이상이고 3번 이하 인용된 논문은 [1,1]으로 3번보다 작다.
즉, 3은 리스트 안에 원소 값으로 없지만 답이 될 수 있다. -
만약 모든 논문의 인용값이 논문개수보다 많다면 답은 논문 개수가 되어야 한다.
함정1의 사진을 보면, h가 되는 조건에는 인용 회수만이 아니라 h편 이상. 이하 로 논문의 개수가 중요하다. 예를 들어보자.
[58,33,68,60] 인 경우, 함정에 빠지면 답은 33으로 착각할 수 있다.
하지만 답은 4이다. 4번 이상 인용된 논문 개수는 4이고 4번 이하 인용된 논문 개수는 0이기 때문이다.
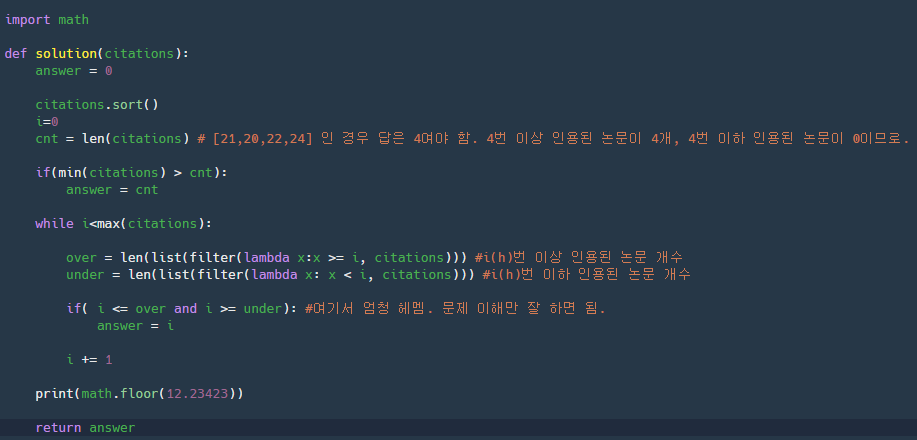
코드
리뷰
문제 자체는 절대 어렵지 않지만, 문제에 대한 충분한 이해없이는 절대 금방 풀 수 없는 문제였던 것 같다.
나도 그랬고 질문하기에 들어가보면 많은 사람들이 함정에 빠져 금방 풀 수 있음에도 불구하고 그러지 못했던 것 같다.
항상 차분히 문제를 잘 이해하자.
출처
프로그래머스 https://programmers.co.kr/learn/courses/30/lessons/42747#
