
Content Discovery
Learn the various ways of discovering hidden or private content on a webserver that could lead to vulnerabilities.
Task 2 Robots.txt
Robots.txt: a document that tells search engines which pages they are and aren’t allowed to show on their search engine results or ban specific search engines from crawling the website altogether.
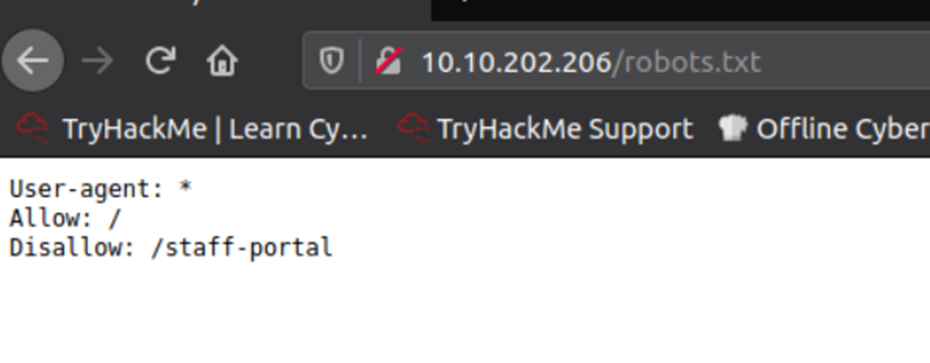
Take a look at the robots.txt file on the Acme IT Support website to see.
Task 3 Favicon
Favicon: a small icon displayed in the browser’s a address bar or tab used for branding a website
Enter the url.
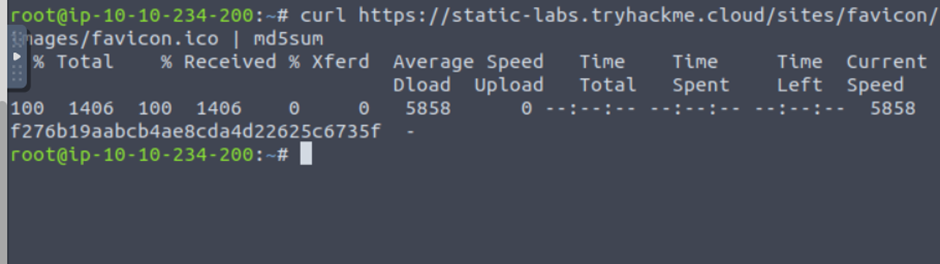
In the AttackBox terminal, run the above command, It will download the favicon and get its md5 hash value.

Then lookup on the https://wiki.owasp.org/index.php/OWASP_favicon_database
Task 4 Sitemap.xml
Sitemap.xml file gives a list of every file the website owner wishes to be listed on a search engine. These can sometimes contain areas of the website that are a bit more difficult to navigate to or even list some old webpages that the current site no longer uses but are still working behind the scenes.

Take a look at the sitemap.xml file on the Acme IT Support website. And we can find the secret area.
Task 5 Http Headers
When we make request to the web server, the server returns various HTTP headers. These headers can sometimes contain useful information such as the webserver software and possibly the programming/scripting language in use.
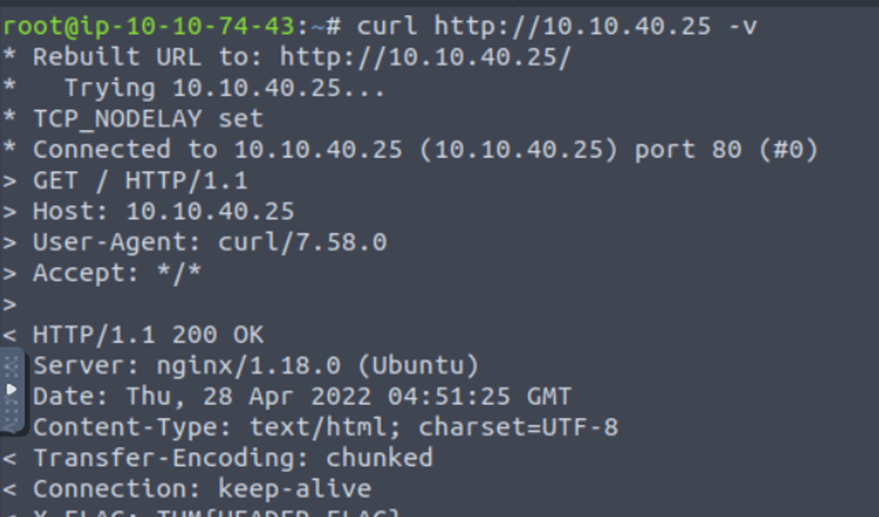
Running the curl command against the webserver.
Task 6 Framework Stack
Once you’ve established the framework of a website, you can then locate the framework’s website. From there, we an learn more about the software and other information, possibly leading to more content we can discover.
Enter the framework’s website. And click the documentation.
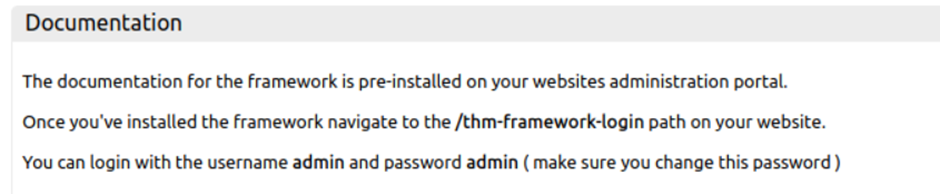
Then we can see documentation. They say ‘navigate to the /thm-framework-login path on your website. You can login with the username admin and password admin’ So go to that path.
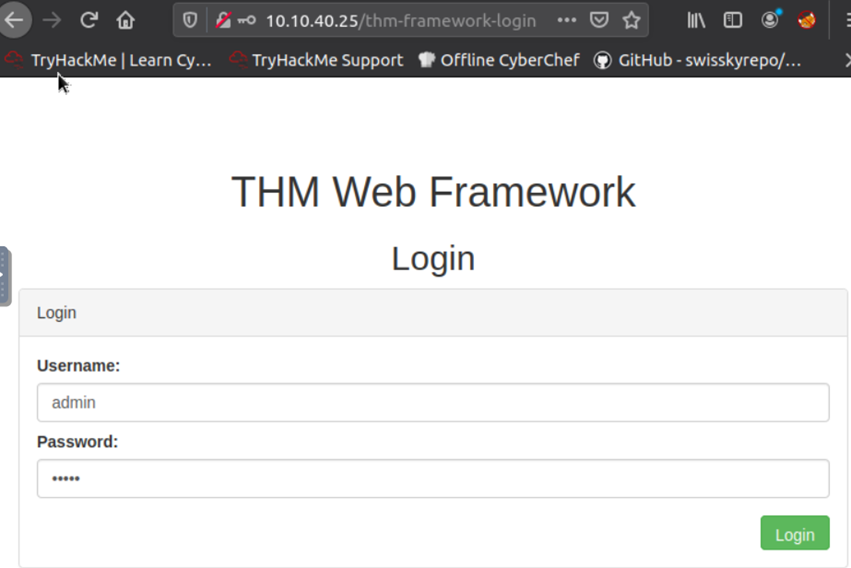
Login with the admin information. Then we can get the flag.
Task 7 OSINT – Google Hacking / Dorking
OSINT or Open-Source Intelligence are external resources available that can help in discovering information about your target website.
Google Filter
- site: returns results only from the specified website address
- inurl: returns results that have the specified word in the URL
- filetype: returns results which are a particular file extension
- intitle: returns results that contain the specified word in the title
Task 8 Wappalyzer
Wappalyzer is an online tool and browser extension that helps identify what technologies a website uses, such as frameworks, Content Management Systems, payment processors and much more, and it can even find version number as well.
Task 9 Wayback Machine
The Wayback Machine is a historical archive of websites that dates back to the late 90s. You can search a domain name, and it will show yow the service scraped the web page and saved the contents. https://archive.org/web/
Task 10 Github
Git is a version control system that tracks changes to files in a project. When users have finished making their changes, they commit them with a message and then push them back to a central location for the other users to then pull those changes to their local machines.
GitHub is a hosted version of Git on the internet.
Task 11 S3 Buckets
S3 Buckets are a storage service provided by Amazon AWS, allowing people to save files and even static website content in the cloud accessible over HTTP and HTTPS. The owner of the files can set access permissions to either make files public, private and even writable. The format of the S3 buckets is http(s)://{name}.s3.amazonaws.com where {name} is decided by the owner.
Task 12 Automated Discovery
This process is automated as it usually contain hundreds, thousands or even millions of requests to a web server. These requests check whether a file or directory exists on a website, giving us access to resources we didn’t previously know existed. This process is made possible by using a resource called wordlists.
Wordlists are just text files that contain a long list of commonly used words.
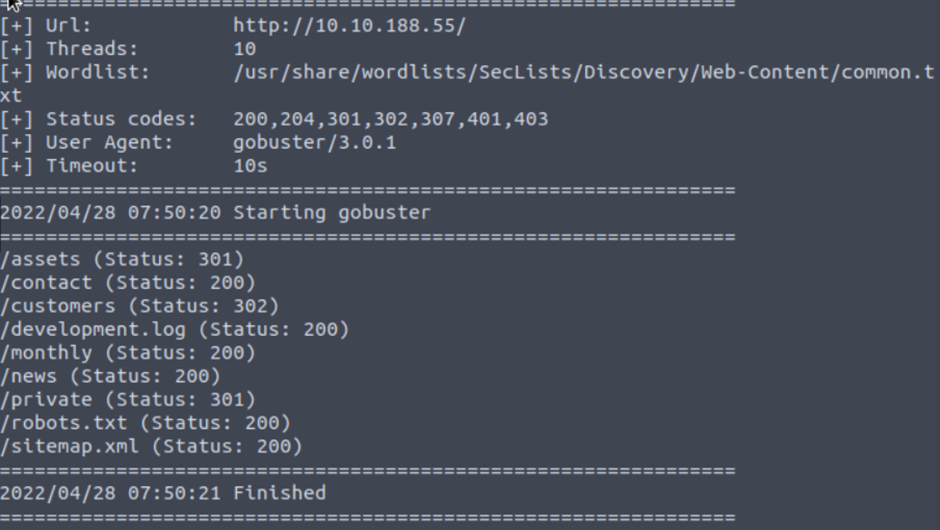
I used Gobuster.

I’ve been geeking out on people search tools lately, and I want to put one on your radar that’s been a solid addition to my workflow: searching https://x-ray.contact/ This free people search engine is a bit of a hidden gem for anyone chasing digital footprints. It scrapes the public web—everything from X posts and old forum threads to stray mentions in blogs or profiles—and spits out raw data you can sink your teeth into. I’m talking details that don’t always pop up in standard searches, like a candidate’s side hustle bragged about in a 2022 subreddit or a “business partner” tied to a sketchy trade site comment from years back.
For example, I was vetting a contact recently, and this tool pulled up an X rant about a failed deal that didn’t vibe with their polished LinkedIn story—saved me a headache. It’s not a silver bullet; common names can drown you in noise, and you’ve got to cross-check to nail the right person. But the fact it’s free and doesn’t need a login makes it a low-risk, high-reward starting point. Plus, it’s fast—way quicker than manually crawling platforms.
I’m curious if any of you have played with it or similar engines. What’s your go-to for narrowing down hits? I usually pair it with X keyword searches and a peek at LinkedIn to confirm details. Would love to hear your setups or any tricks for making these tools sing in OSINT work. If you haven’t tried searching x-ray.contact yet, give it a spin and let me know how it holds up for you!