01. 데이터베이스(H2)
H2가 무엇인가! Java로 개발된 경량의 오픈소스 관계형 데이터베이스 관리 시스템(RDBMS)이다!
아무래도 가볍고 빠르니 이렇게 실습할 때에 사용하기 좋은 것 같으다

DB(H2)사용 방식 3가지
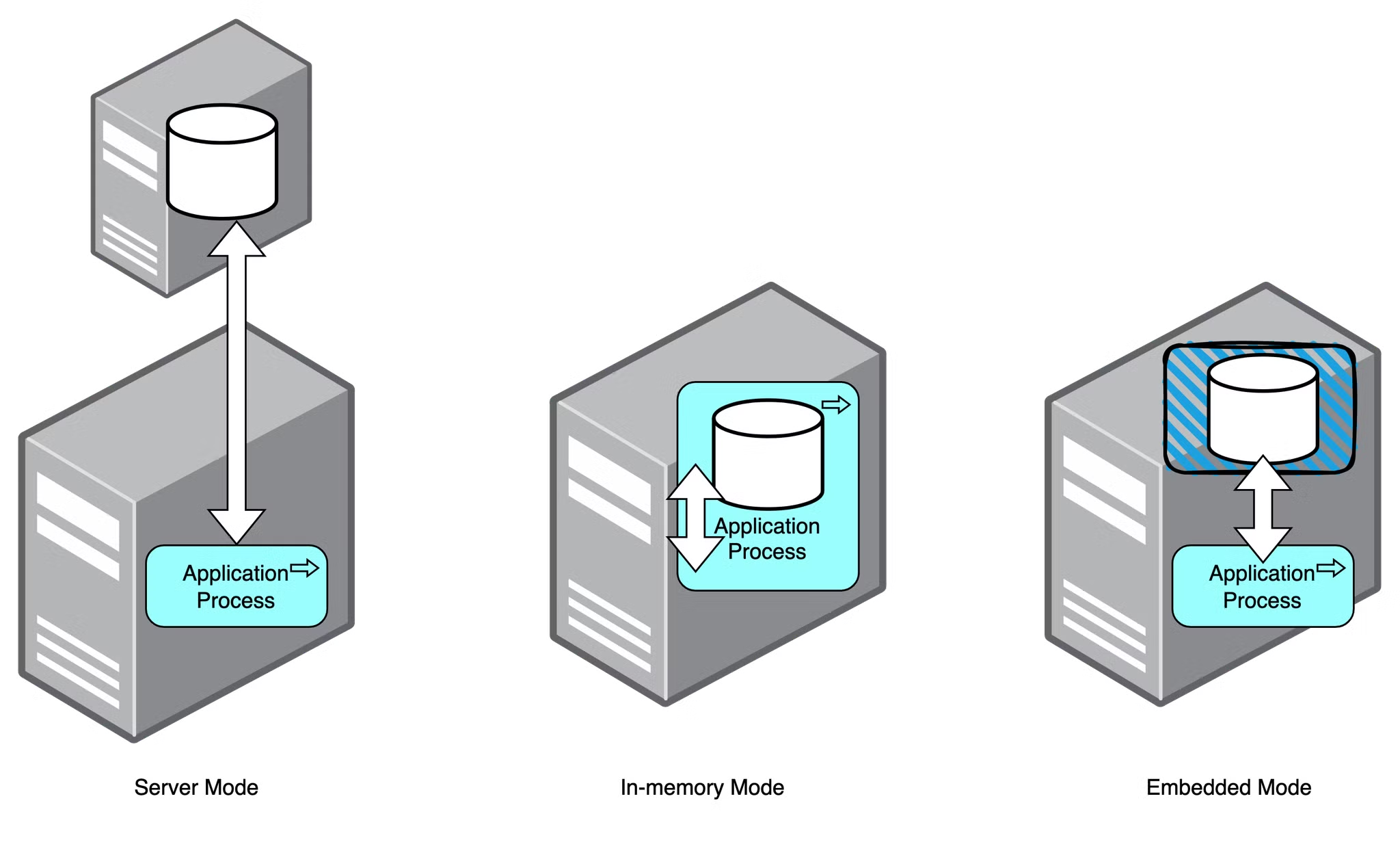
- Server Mode(<-In-memory방식과 정반대)
- 직접 엔진을 설치해서 사용하는 방식
- 애플리케이션과 상관 없는 외부에서 DB 엔진이 구동된다.
- 데이터가 애플리케이션 외부에 저장되므로 애플리케이션을 종료해도 데이터가 사라지지 않는다!
-In-memory Mode(<-Server Mode와 정반대)
- 엔진을 설치하지 않고, 애플리케이션 내부의 엔진을 사용하는 방식
- build.gradle 이나 application.properties 설정을 통해서 실행이 가능하다.
- 애플리케이션을 실행하면 DB 엔진이 함께 실행되고 애플리케이션을 종료하면 DB엔진이 함께 종료된다.
- 데이터가 애플리케이션 메모리에 저장되므로 애플리케이션을 종료하면 데이터가 사라진다..!
-Embedded Mode
- 엔진을 설치하지 않고 애플리케이션 내부의 엔진을 사용하는 방식
- build.gradle 이나 application.properties 설정을 통해서 실행이 가능하다.
- 애플리케이션을 실행하면 DB 엔진이 함께 실행되고 애플리케이션을 종료하면 DB엔진이 함께 종료된다.
- 데이터가 애플리케이션 외부에 저장되므로 애플리케이션을 종료해도 데이터가 사라지지 않는다.
| Mode | H2 다운로드 여부 | 실행주체 | DB저장 위치 | 사용 용도 |
|---|---|---|---|---|
| Server Mode | O | 외부 | 로컬(파일 시스템) | 배포용도 |
| In-Memory Mode | X | 스프링 | 메모리 | 테스트 용도 |
| Embedded Mode | X | 스프링 | 로컬(파일 시스템) | 개발 용도 |
1. Server Mode
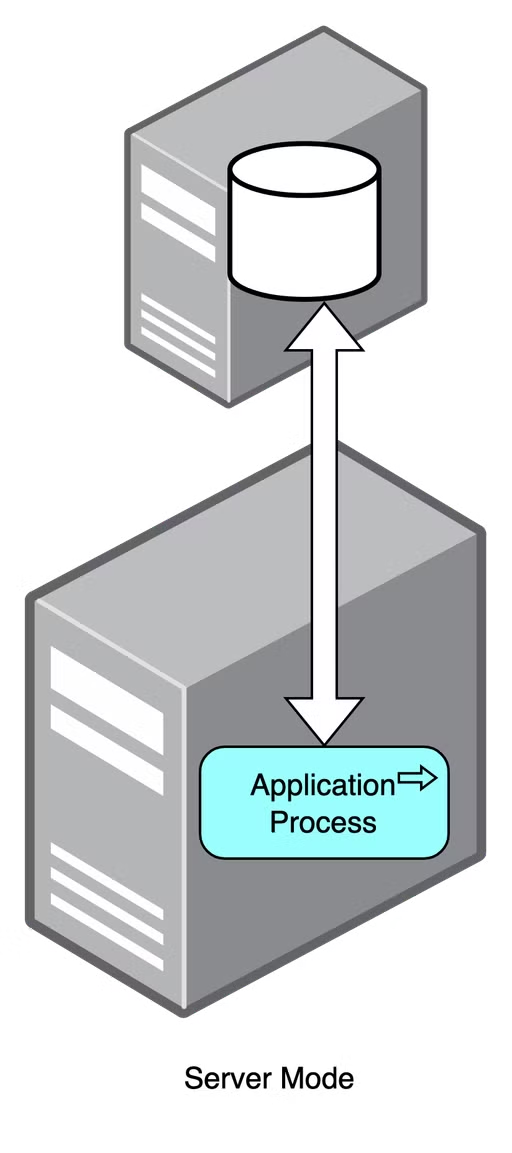
- 서버 모드는 현업에서 사용하는 모드로 컴퓨터에 Db엔진을 설치하고, 엔진을 구동하여 사용하는 방식이다
- 애플리케이션과 DB가 분리되어있다!!! -> 따라서 여러 애플리케이션에서 동일한 DB를 사용하기에 적합
2. In-memory Mode
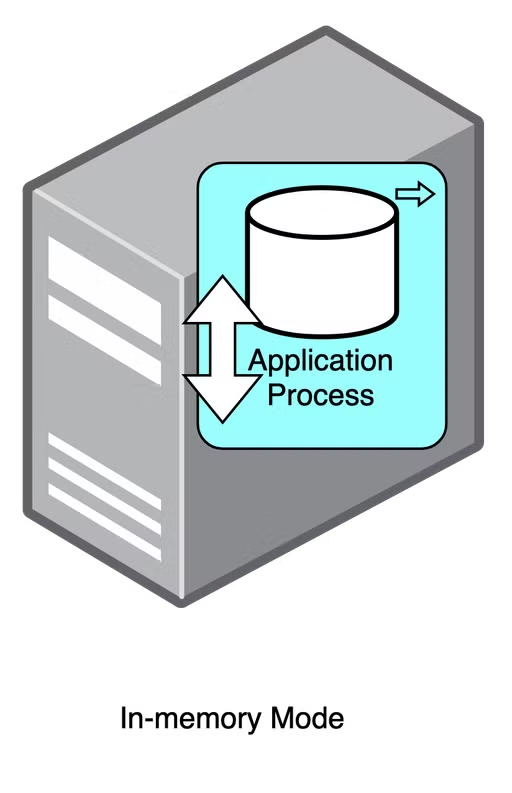
- 인메모리 모드는 애플리케이션에 Db엔진이 내장되어서 애플리케이션과 함께 실행되고 종료한다
- 데이터가 애플리케이션의 메모리에 저장되기 때문에 애플리케이션이 종료되면 모든 데이터가 사라지는 휘발성의 특징을 갖고 있다
- 그래서 보통 단위테스트를 할 때! 사용한다
- 스프링부트 프로젝트에서 H2를 인메모리 모드로 사용하려면 application.yml이나 application.properties에서 아래와 같이 설정하면 된다.
# application.yml
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:mem:{DB 이름}
username: sa
password:
# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:mem:{DB 이름}
spring.datasource.username=sa
spring.datasource.password=datasource의 url에는 일반적으로 DB 서버의 호스트와 포트 번호, DB 이름 등의 접속 정보를 기재하는데 H2에서는 여기에 me을 기재해서 애플리케이션이 실행되는 메모리 자체에서 DB를 사용하겠다는 것을 선언한다.
Embedded Mode
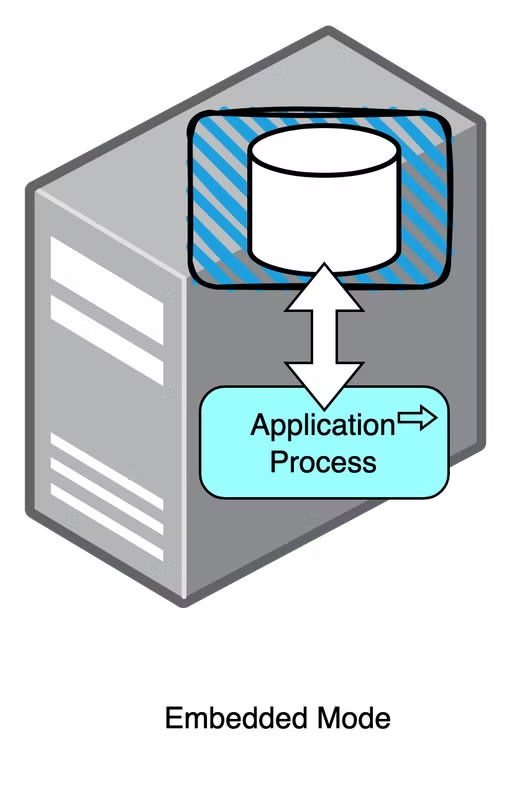
- 임베디드(내장) 모드는 인메모리 모드와 동일하게 애플리케이션에 DB엔진이 내장되어 애플리케이션과 함께 실행되고 종료되는 방식이다.
- 인메모리 모드와 다른 점은 데이터를 로컬에 저장하기 때문에 데이터 휘발에서 자유롭다는 점이다. 이로 인해 간단한 애플리케이션에서 사용하기 좋다.
- 스프링부트 프로젝트에서 H2를 임베디드 모드로 사용하는 방법은 Url을 제외하고 동일하게 설정한다.
# application.yml
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:{DB가 저장될 경로}
username: sa
password:# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:{DB가 저장될 경로}
spring.datasource.username=sa
spring.datasource.password=- 위의 인메모리 모드와 차이점이라면 mem이 사라지고, jdbc:h2: 이후에 바로 DB가 저장될 경로를 입력한다는 부분이다!
02.데이터베이스에서 데이터 다루기(SQL)
SQL 기본 구문을 사용해서 데이터를 생성,조회,수정,삭제 하는 법을 알아야겠다! 이를 통해서 db관리의 기본이 되는 SQL문법 공부까쥐

SQL 입문
- SQL 소개 : SQL은 db시스템을 조작하는데 사용하는 언어이다.
- SQL 종류 : SQL은 DDL(데이터 정의 언어),DML(데이터 조작 언어),DCL(데이터 제어 언어)로 나뉜다!
DDL(데이터 정의 언어) - 테이블 관리하기
- CREATE TABLE : 새로운 테이블을 생성한다.(열의 데이터 타입과 속성을 어떻게 정의할지 고민)
- ALTER TABLE :이미 만든 테이블에 변화를 준다.(데이터를 추가/제거)
- DROP TABLE : 사용하지 않는 테이블을 없앤다.
DML(데이터 조작 언어) - 데이터 찾기
- SELCET : 필요한 데이터를 찾아 본다.
- WHERE : 특정 조건을 만족하는 데이터만 찾을 수 있다.
- ORDER BY : 데이터를 순서대로 정렬하고
- GROUP BY : 비슷한 재료들을 그룹화 해서 관리할 수 있다.
- JOIN : 여러 장소에서 가져온 데이터를 합칠 수 있다.
DML - 데이터 조리 및 제거
- INSERT INTO : 새로운 데이터를 추가
- UPDATE : 기존의 데이터를 수정
- DELETE FROME : 불필요한 데이터 제거
(갑분)트랜잭션?

JPA는 트랜잭션 및 영속성 전이 개념을 이해해야 한다...(쉽알)
따라서 가볍게 짚고 넘어가보쟈
- 트랜잭션은 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위를 말한다.
- 요리로 치면, 조리대를 의미하며 재료(데이터)들을 조회해서 생성/수정/삭제 후 최종 결과물을 만들때까지 하나의 작업을 트랜잭션으로 관리할 수 있다. 또한 트랜잭션은 조리(데이터처리)중에 문제가 발생하면, 그전에 했던 변경을 아무일도 없던 것처럼 모두 되돌린다!!

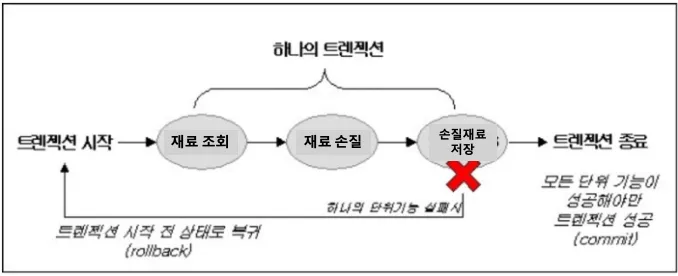
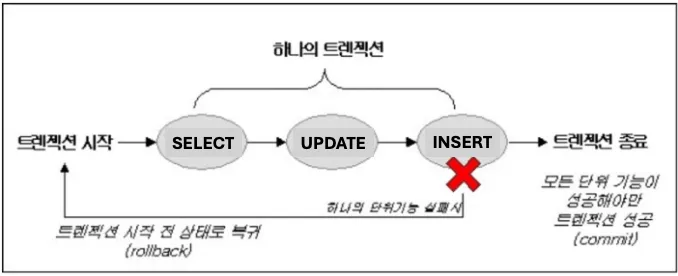
트랜잭션의 3가지 특징
- 원자성(All or Nothing)
- 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야한다.
- 트랜잭션은 사람이 설계한 논리적인 작업 단위로, 일처리는 작업단위별로 이루어져야 사람이 다루는데 무리가 없다.
- 만약 트랜잭션 단위로 데이터가 처리되지 않으면, 설계한 사람은 데이터 처리 시스템을 이해하기 힘들뿐아니라, 오작동시에 원인을 찾기가 힘들어진다.
- 일관성(Keeps Data Correct)
- 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다.
- 트랜잭션이 진행되는 동안에 데이터 베이스가 변경 되더라도 업데이트된 데이터베이스로 트랜잭션이 진행되는게 아니라, 처음에 트랜잭션을 진행하기 위해 참조했던 데이터 베이스로 진행된다.
- 이렇게 함으로써, 각 사용자는 일관성있는 데이터를 볼 수 있다.
- 독립성(Independent)
- 둘 이상의 트랜잭션이 동시에 실행되고 있을 경우, 어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없다는 점이다.
DCL(데이터 제어 언어) - 트랜잭션 관리와 보안
- BEGIN,COMMIT,ROLLBACK : 트랜잭션(조리대)에서의 사고(다른 데이터와 섞이거나 잘못 버려지는 경우)를 방지하기 위해 이와 같은 명령어로 트랜잭션을 관리 할 수 있다.
- BEGIN : START TRANSACTION과 동일하며, 새로운 트랜잭션을 생성 및 시작하는 연산이다.
- COMMIT : 하나의 트랜잭션이 성공적으로 끝났고, 데이터베이스가 일관성있는 상태에 있을 때, 하나의 트랜잭션이 끝났다는 것을 알려주기 위해 사용하는 연산이다. 이 연산을 사용하면 수행했던 트랜잭션이 로그에 저장되며, 후에 Rollback연산을 수행했었던 트랜잭션 단위로 하는 것을 도와준다.
- ROLLBACK : 하나의 트랜잭션 처리가 비정상적으로 종료되어서 트랜잭션의 원자성이 깨졌을 때, 트랜잭션을 처음부터 다시 시작하거나, 트랜잭션의 부분적으로만 연산된 결과를 다시 취소시킨다.
- GRANT, REVOKE : 접근 권한을 설정할 수 있다.
쿼리 예시
- DDL - 테이블 생성/삭제
CREATE TABLE users (id SERIAL, name VARCHAR(255));
DROP TABLE users;- DML - 데이터 추가
INSERT INTO users (name) VALUES (?)- DML - 데이터 조회
SELECT name FROM users WHERE id = ?- DML - 데이터 수정
UPDATE users SET name = ? WHERE id = ?- DCL -트랜잭션 커밋/롤백
COMMIT
ROLLBACK좀 더 복잡한 쿼리 예시
- 테이블 확장
기존 테이블
CREATE TABLE users (
id SERIAL,
name VARCHAR(255)
);칼럼 추가
- email : 사용자의 이메일 주소
- created_at : 계정 생성 날짜
- status : 계정 상태(활성/비활성)
ALTER TABLE users
ADD COLUMN email VARCHAR(255);
ALTER TABLE users
ADD COLUMN created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP;
ALTER TABLE users
ADD COLUMN status ENUM('active', 'inactive') DEFAULT 'active';
추가 테이블 생성
- orders : 사용자 주문 정보 저장 테이블
- products : 상품 정보 저장 테이블
CREATE TABLE products (
id SERIAL,
name VARCHAR(255),
price DECIMAL(10, 2),
PRIMARY KEY (id)
);
CREATE TABLE orders (
id SERIAL,
user_id BIGINT,
product_id BIGINT,
quantity INT,
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
- 데이터 삽입
users 테이블에 데이터 삽입
INSERT INTO users (name, email, status) VALUES
('Alice', 'alice@example.com', 'active'),
('Bob', 'bob@example.com', 'inactive'),
('Charlie', 'charlie@example.com', 'active');
products 테이블에 데이터 삽입
INSERT INTO products (name, price) VALUES
('Laptop', 1000.00),
('Phone', 500.00),
('Tablet', 300.00);
orders 테이블에 데이터 삽입
INSERT INTO orders (user_id, product_id, quantity) VALUES
(1, 1, 1),
(1, 2, 2),
(2, 3, 1),
(3, 1, 3);
쿼리 실습
- WHERE절
- 활성상태(active)인 사용자만 조회
SELECT * FROM users
WHERE status = 'active';- JOIN
- 사용자와 주문내역을 함께 조회
SELECT users.name, orders.id AS order_id, products.name AS product_name, orders.quantity, orders.order_date
FROM orders
JOIN users ON orders.user_id = users.id
JOIN products ON orders.product_id = products.id;
- ORDER BY
- 사용자 이름으로 정렬해서 조회
SELECT * FROM users
ORDER BY name;
- 주문 내역을 주문 날짜 순으로 내림차순 정렬해서 조회
SELECT users.name, products.name AS product_name, orders.quantity, orders.order_date
FROM orders
JOIN users ON orders.user_id = users.id
JOIN products ON orders.product_id = products.id
ORDER BY orders.order_date DESC;
- 실습을 위한 데이터 리셋
- 데이터 초기화를 원한다면, 이 쿼리로 테이블 내용을 지울 수 있다
TRUNCATE TABLE orders;
TRUNCATE TABLE products;
TRUNCATE TABLE users;추가 연습 예제
- 특정 날짜 이후에 생성된 계정을 가진 사용자 조회
SELECT * FROM users
WHERE created_at > '2023-01-01';
- 각 사용자별 총 주문 금액 조회
SELECT users.name, SUM(products.price * orders.quantity) AS total_spent
FROM orders
JOIN users ON orders.user_id = users.id
JOIN products ON orders.product_id = products.id
GROUP BY users.name;
03. 데이터베이스 연결(Driver)
데이터베이스 드라이버의 역할과 중요성을 이해하고, 적절한 드라이버를 선택 하는 방법을 정리해보겟숩니다.
데이터베이스 Driver의 역할 및 종류
- 드라이버의 역할 : 데이터베이스 드라이버는 애플리케이션과 데이터베이스간의 통신을 중개하는 역할을 한다.
즉, 드라이버는 애플리케이션의 요청을 DB가 이해할 수 있는 언어로 변환해주는 역할을 한다. - 드라이버 종류 : 다양한 DB시스템마다 호환되는 드라이버가 있다!
예를 들어서 Oracle, MySQL, PostgreSQL등 각 데이터베이스 제품마다 맞는 특정 드라이버가 필요하다.
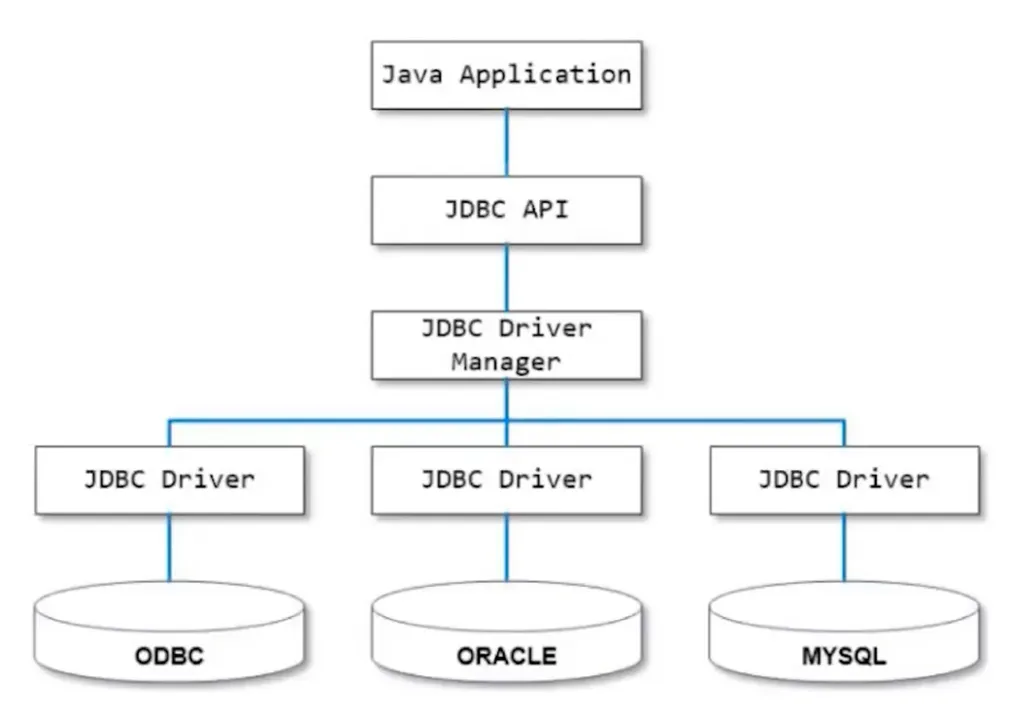
드라이버의 동작 방식
데이터베이스 드라이버는 애플리케이ㅕㄴ과 데이터베이스 간의 데이터 교환을 조절하고 관리하는 역할을 한다.
- 연결 초기화
- 요청 수신 : 애플리케이션은 데이터베이스 작업을 시작하기 위해 드라이버에 연결을 요청한다!
- 연결 설정 : 드라이버는 데이터베이스 서버에 로그인하고 필요한 설정을 수행해서 연결을 완료한다. 이 과정은 네트워크 정보, 인증자격증명 등을 사용해 이루어진다.
- SQL 전송 및 실행
- SQL 명령 변환 : 애플리케이션에서 발송된 SQL 명령을 받은 드라이버는 해당 명령을 데이터베이스가 이해할 수 있는 형태로 변환한다.
- 명령 처리 : 변환된 명령은 데이터베이스 서버로 전송되어서 실행된다.
데이터베이스는 쿼리를 처리하고, 요구된 데이터를 검색하거나 데이터에 변화를 준다.
- 결과 처리
- 결과 수신 : 데이터베이스에서 작업의 결과를 보내면, 드라이버는 이 결과를 받아서 애플리케이션에서 해석할 수 있는 형태로 변환한다.
- 결과 전달 : 최종적으로 드라이버는 이 결과를 애플리케이션에 전달한다. 애플리케이션은 이 정보를 사용자에게 표시하거나 다음 작업을 진행한다.
- 연결 종료
-
연결 해제 : 작업이 완료되면, 드라이버는 데이터베이스 서버와의 연결을 정리한다! 자원을 정리하고, 다음 세션을 위해 세스템을 초기화한다.
JDBC Driver Manager는 애플리케이션이 실행되고 있는 런타임 시점에서
-Connections(연결)을 생성해서 쿼리를 요청할 수 있는 상태를 만들어주고
-Statement(상태)를 생성해서 쿼리를 요청하게 하고
-ResultSet(결과셋)을 생성해서 쿼리결과를 받아올 수 있게 한다.
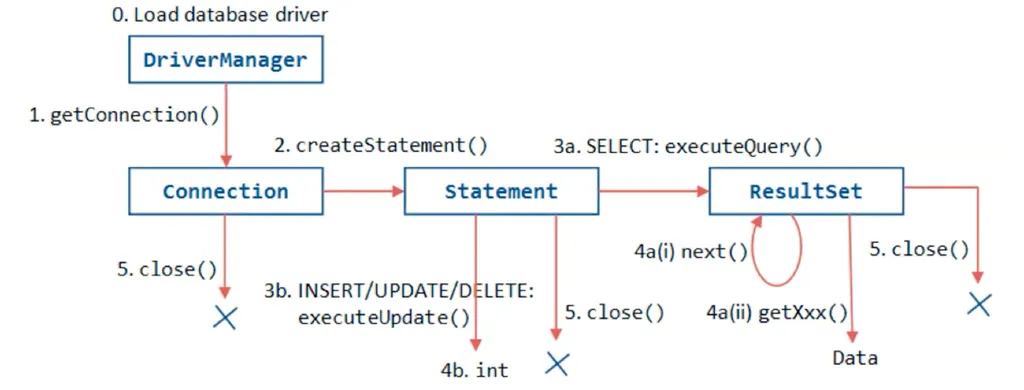
04. JDBC와 JPA

JDBC와 JPA는 데이터베이스와 상호작용하는 방법이다. 드라이버 위에서 동작하는 프로그래밍 인터페이스나 프레임워크 라고 생각하면 된다!
JDBC(Java Database Connectivity)
- 정의 : Java 애플리케이션이 관계형 데이터베이스와 통신 할 수 있도록 해주는 저수준 API
- 드라이버 : JDBC 드라이버를 사용(MySQL JDBC 드라이버 등)
- 특징 :
- SQL 쿼리를 직접 작성 및 실행 가능
-Connection,Statement,ResultSet같은 객체로 db에 접근 가능 - db와의 연결을 수동으로 관리하며 접근 로직이 복잡해질 수 있다
- 장점 : 세밀한 제어가 가능하고, 원하는 SQL을 직접 작성해서 최적화를 시도할 수 있다.
- 단점 : 복잡하고 재사용성 및 유지보수가 어렵당...

JPA(Java Persistence API)
- 정의 : 객체지향적인 방식으로 db에 접근하는 고수준 API로,ORM(Object Relational MApping)을 통해 객체와 데이터베이스 테이블간의 매핑을 자동으로 처리해준다.
- 드라이버 : JPA 자체는 JDBC를 추상화한 API로 실제로는 내부적으로 JDBC 드라이버를 사용해 데이터베이스와 통신한다.
- 구현체 : JPA는 표준스펙이라서 실제 동작을 담당하는 구현체가 필요하다(Hibernate,EclipseLink 등)
- 특징 :
- SQL을 직접 작성할 필요 없이 엔티티객체 사용해서 db와 상호작용 가능
- 데이터베이스에 대한 추상화를 제공해서 데이터베이스에 종속되지 않게 도와준다.
- db연동 로직을 간소화해서 유지보수와 개발속도를 높힌다.
- 구현체가 JPA표준을 지원하고, 실제 db와 상호작용한다.
-
장점 : 객체지향 패러다임과 잘 맞고, 코드 재사용성과 유지보수성이 높다. 또 데이터베이스 독립적인 코드를 작성할 수 있어서, 다른 db로의 이식이 상대적으로 용이하다.
-
단점 : 내부적으론 복잡한 SQL쿼리가 생성되기 때문에, 성능이 중요한 경우엔 세밀한 튜닝이 필요할 수 있다.
그래도....

결론적으로, JDBC 드라이버는 데이터베이스에 연결하기 위한 필수 구성 요소이고, JPA는 이 JDBC 위에서 더 고수준의 ORM 기능을 제공하는 프레임워크이다. JDBC와 JPA 모두 드라이버가 아니라 API 또는 프레임워크로 이해하는 것이 맞을 것 같으네요!
그럼 오늘은 20k
