여러 블로그에 정리된 내용을 읽으며 학습하고
거기서 궁금한 부분들은 또 검색해 가며 읽는데
여러 번 읽다 보니 이해는 가는 듯한데
뭔가 뇌에 와닿는 느낌이 아니다.
직접 활용을 하면서 이해가 돼야 할 거 같은데...
휘발까지 반나절이면 족할 것 같아서 후다닥 정리해 본다.
영단어 외우듯 매일 한 번씩 들여다봐야 할 듯!
Hash Tables의 개념
해시 테이블은 key와 value 형태로 데이터를 저장하는 자료구조를 말하는데
원하는 데이터를 빠르게 검색할 수 있는 특징을 가진다.
검색이 빠른 이유는 내부적으로 배열(bucket)을 사용하여 데이터를 저장하기 때문인데
그림으로 표현하면 아래와 같다.
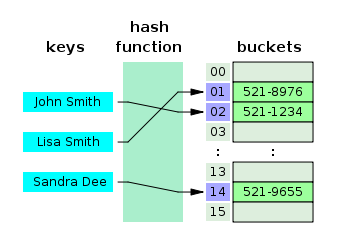
그림에 보이듯 key를 인자로 해시 함수에 넣으면 해시값이 나오는데
이 해시값을 통해 배열 고유의 인덱스를 생성하고
이 인덱스를 활용해 값을 저장하거나 검색하게 된다.
Hash Function
여기서 해시 함수란 해시 알고리즘이라고도 하는데
임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
쉽게 말해 key를 고정된 길이의 해시로 변경해 주는 역할을 하는데
이 과정을 해싱(hashing)이라고 한다.
해싱 과정을 통해 나온 해시값을 주소로 해서 key와 value를 저장하게 되는데 그곳을 버킷 혹은 슬롯이라고 부른다.
해시 함수는 보통 해시 테이블이라는 자료구조에서 많이 쓰이는데
큰 파일에서 중복되는 레코드를 찾을 수 있기 때문에
데이터베이스 검색이나 테이블 검색 속도를 가속화할 수 있고
이로 인해 DNA 시퀀스에서 유사한 패턴을 찾는 데 사용되기도 한다.
또 암호학에서도 사용될 수 있고 전송된 데이터의 무결성을 확인해 주는 데
사용되기도 하는데, 누구로부터 온 것인지 입증해 주는
HMAC를 구성하는 블록으로 사용되기도 한다.
HMAC란?
암호학에서 암호화 해시 함수와 암호화 키를 수반하는 특정한 유형의
메시지 인증 코드를 말한다.
해시 함수는 결정론적으로 작동해야 하며, 만약 두 해시값이 다르다면
해시값의 원래 데이터도 달라야 함을 의미한다.
(역은 성립 불가)
또한 해시 함수는 암호학적 해시 함수와 비암호학적 해시 함수로 구분되곤 하는데,
암호학적 해시 함수의 종류로는 MD5, SHA 계열이 있으며
비암호학적 해시 함수로는 CRC32 등이 있다.
MD5란?
메시지 축약 알고리즘으로서 파일 무결성 검사 용도로 많이 쓰인다.
128bit 해시를 제공하며 암호화&복호화를 통해 보안 용도로 많이 쓰이는데
암호화에 결함이 발견됨에 따라 SHA와 같은 다른 알고리즘을 사용하는 것이
권장되고 있다.
SHA란?
Secure Hash Algorithm의 약자로 안전한 해시 알고리즘을 말한다.
한 가지를 일컫는 게 아니고 관련된 여러 암호학적 함수들의 모음의 총칭이다.
SHA-1, SHA-256 이렇게 여러 종류가 존재한다.
암호화에 결함이 발견된 MD5를 대신해 SHA-1가 많이 쓰였으나
좀더 중요한 기술에 보안을 두텁게 하기 위해서는 SHA-256이나
그 이상의 알고리즘 사용을 권장하기도 한다.
hash collision
간혹 해시값이 중복되는 경우가 있다.
key는 다른데 결과인 해시값이 똑같아 발생하는 문제인데
이런 경우를 해시 충돌이라고 부른다.
해시 충돌은 해시 함수를 이용한 자료구조나 알고리즘의 효율성을 떨어뜨리는데
해시 충돌이 자주 발생하지 않도록 구성하는 것이 중요하다.
만약 해시 충돌이 발생했다면 분리 연결법과 개방 주소법,
크게 이 두 가지 방법으로 해결할 수 있다.
-
분리 연결법(Separate Chaining)
분리 연결법이란 동일한 버킷의 데이터에 대해 추가 메모리를 사용해서
다음 데이터의 주소를 저장하는 방법을 말한다.
위 그림처럼 존과 산드라의 해시값이 152로 일치할 경우
두 value 값을 분리하되 연결해 놓는 방식으로 충돌을 해결한다.이러한 방식의 장점은 해시 테이블을 확장할 필요가 없고
비교적 손쉽게 구현이 가능하며, 삭제 또한 용이하다.
단점으로는 데이터 수가 많아지게 되면 당연히 연결되는 데이터의 수가 많아지게 되며
그로 인해 캐시 효율성이 감소하게 된다. -
개방 주소법(Open Addressing)
개방 주소법은 분리 연결법처럼 추가 메모리를 사용하지 않고
비어 있는 해시 테이블의 공간을 활용한다.이를 구현하기 위한 세 가지 방법은 아래와 같다.
-
Linear Probing: 현재 버킷의 인덱스로부터 고정폭만큼 이동하여
차례대로 빈 버킷에 데이터를 저장하는 방식이다. -
Quadratic Probing: 해시의 저장 순서의 폭을 제곱으로 하는 방식이다.
처음 충돌이 발생하면 1만큼 이동하고 다음 계속 충돌이 일어나면 2의 제곱, 3의 제곱
이렇게 옮기는 방식이다. -
Double Hasing Probing: 해시된 값을 한번 더 해싱해서
규칙성 자체를 없애버리는 방식이다.
이렇게 되면 새로운 주소를 할당하기 때문에 당연히 다른 방식들보다는
더 많은 연산을 하게 된다.
Hash Tables vs Arrays
해시 테이블과 배열에 대한 비교를 하기 전에
먼저 시간복잡도에 대한 개념을 알아야 한다.
시간복잡도
특정 알고리즘이 어떤 문제를 해결하는 데 걸리는 시간을 의미한다.
결과가 같더라도 어떻게 프로그래밍하느냐에 따라
결과가 나올 때까지의 소요 시간이 달라질 수 있는데,
같은 결과라면 최대한 시간이 적게 걸리는 게 좋은 소스이다.
Big-O 표기법
시간복잡도에는 여러 개념들이 있지만
'아무리 많이 걸려도 이 시간 안에는 끝날 것'이라는 개념이 가장 중요하다.
동전을 튕겨 뒷면을 나오게 한다고 했을 때
운이 좋으면 한 번데 나올 수도 있지만 운이 나쁘면 3, 4번,
혹은 최악의 경우 n번만큼 시도해야 할 수도 있다.
바로 이 최악의 경우를 계산하는 방식을 Big-O 표기법이라고 부르며
이 방식을 가장 많이 사용한다.

(시간복잡도 그래프)
- O(1) - Constant
입력 데이터의 크기에 상관 없이 언제나 일정한 시간이 걸리는 알고리즘을 나타낸다.
데이터 증가량과 관계 없이 일정한 성능을 보여준다.

일반적으로 1라인이 실행되는 것을 1이라고 한다.
위 코드의 시간복잡도는 O(1)이다.
- O(n) - Linear
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘이다.
데이터가 10배가 되면 처리 시간도 10배가 된다.

위와 같은 1차원 반복문이 이에 해당한다.
반복문이 N번만큼 반복하므로 시간복잡도는 O(n)이다.
그런데 만약 반복문이 두 개가 있다면?
중첩된 반복문이 아니라 위와 같은 1차원 반복문이 두 개 있다면
그건 O(n²)이라 생각할 수 있지만 그것도 역시 O(n)이다.
시간복잡도 계산은 가장 큰 영향을 미치는 알고리즘 하나만 계산한다.
- O(n²) - quadratic
데이터가 많아질수록 처리 시간이 제곱으로 늘어나는 알고리즘이다.
데이터가 10배가 되면 처리 시간은 최대 100배가 된다.
2중 루프가 대표적이다.

-
O(log₂ n) - Logarithmic
입력 데이터의 크기가 커질수록 처리 시간이 로그만큼 짧아지는 알고리즘이다.
데이터가 10배가 되면 처리 시간은 2배로 줄어든다.
이진 탐색이 대표적이며 재귀가 순기능으로 이루어지는 경우도 이에 해당한다. -
O(n log₂ n) - Linear-Logarithmic
데이터가 많아질수록 처리 시간이 로그의 배만큼 더 늘어나는 알고리즘이다.
데이터가 10배가 되면 처리 시간은 약 20배가 된다.
정렬 알고리즘 중 병합정렬과 퀵정렬이 대표적인 예이다. -
O(2ⁿ) - Exponential
데이터가 많아질수록 처리 시간이 기하급수적으로 늘어나는 알고리즘이다.
대표적인 예로 피보나치 수열과 재귀가 역기능을 할 때가 있다.
Hash Tables와 Arrays의 유사성
해시 테이블과 배열은 모두 데이터를 저장할 수 있는 메모리 셀의 모음이다.
Dot Notation이나 Bracket Notation을 사용해
항목을 검색할 수 있다.
Hash Tables와 Arrays의 차이점
Hash Tables
- 크기에 제한이 없다.
- key, value를 쌍으로 설정 가능하다.
key는 객체의 속성이고 value는 key에 할당되는 것이다. - 질서라는 개념이 없다.
- 항목을 검색하기 위해 다른 요소를 반복할 필요가 없다.
- 항목을 삽입하거나 삭제할 때 다른 key 값은 변경되지 않는다.
- 각 key에 대한 값을 저장할 공간이 필요하므로 메모리를 더 많이 사용한다.
Arrays
- 고정된 크기를 갖는다. (python의 리스트는 고정된 크기를 갖지 않는다.)
- 숫자인 인덱스와 요소인 value로 이루어진다.
- 항목을 검색하려면 배열을 반복해야 한다.
- 항목을 삽입하거나 삭제할 때 인덱스 번호가 변경되고
배열의 길이가 변경된다. - 각 항목에 대한 값을 저장할 필요가 없으므로
메모리를 덜 사용한다.

Hash Table 코드 예제(Python)
해시 테이블 생성
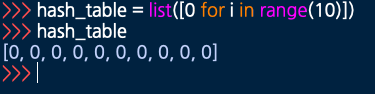
- 리스트 컴프리헨션으로 10자리 인덱스를 가진 해시 테이블을 생성한다.
해쉬 함수 생성 - Division 방식

- 해시 함수로 key를 넣으면 해시값(키를 5로 나눈 나머지)을 반환한다.
해시 테이블에 저장 및 값 가져오기
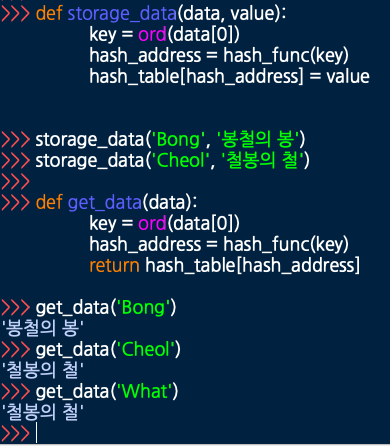
먼저 storage_data 함수는 data와 value 2개의 인자를 받는다.
data는 첫 글자를 따서 key로 만드는데
상황에 따라 키 생성 방법엔 정의가 필요하다고 한다.
여기서는 아스키코드를 반환하는 ord() 함수를 사용했는데
스트링 1개만 넣어야 하는 관계로 data[0]
이렇게 첫 글자를 지정했다.
데이터의 첫 글자가 아스키코드로 변환해 key가 되었고
이 key를 인자로 위에서 만들어둔 hash_func() 해시 함수를 실행한다.
그럼 Division 방식으로 해싱을 통해 해시값을 반환하고
이 해시값을 hash_address로 지정해
해시 테이블에서 이 주소에 해당하는 value 값을 매핑해 준다.
저장된 값을 가져오려면 사진에 보이듯
data를 인자로 해서 똑같은 방식으로 해시 주소를 얻고
이걸 바탕으로 해시 테이블에서 해당 주소에 저장된 value를
뽑아올 수 있다.
그런데 사진의 예시에 보면 매핑 결과가 뭔가 이상하다.
data = 'Bong'
key = '66' # B에 대한 아스키코드
value = '봉철의 봉'data = 'Cheol'
key = '67' # C에 대한 아스키코드
value = '철봉의 철'data = 'What'
key = '87 # W에 대한 아스키코드
value = ?
What을 넣으면 value 지정이 안 돼 있으니
오류가 나야 할 거 같은데 '철봉의 철'이 나온다.
바로 해시 충돌이 일어나서 그렇다.
Division 방식으로 key % 5를 반환하도록 해시 함수를 구성했는데
아스키코드 67과 87은 모두 5로 나눴을 때 나머지가 2이다.
주소값이 겹치니까 같은 위치를 가리키게 되는 것이다.
그렇다면 위에서 배운 해시 충돌 해결법을 사용해 보자.
먼저 분리 연결법이다.
체이닝 기법이라고 해서 인덱스가 중복되면 해당 인덱스와 연결된 곳에
데이터를 넣는 방식이다.

사실 파이썬은 딕셔너리가 바로 해시 테이블의 기능을 한다.
하지만 해시 테이블이 어떻게 생겼고
충돌이 일어나면 어떻게 처리되는지를 보여주기 위해
리스트를 이용해 마치 딕셔너리처럼 표현해 보았다.
이중 리스트가 사용됐는데 해당 인덱스에 중복된 (어드레스 충돌) 값이 있으면
해당 인덱스 안에 이중 리스트로 다음 값을 연결해 준다.
리스트는 key, value의 형태를 띄지 않기 때문에
0번 인덱스를 key로, 1번 인덱스를 value로 쓰고 있다.
로직은 간단하다.
입력된 데이터를 아스키코드로 바꾼 후 해시 함수를 통해 해시값으로 만들고
이 값을 해시 테이블의 인덱스 값으로 사용한다.
만일 같은 인덱스에 값이 이미 존재한다면 해당 인덱스에 존재하는 리스트의 요소가 몇 개인지 파악해 하나씩 가져오고
각 요소의 key 값을 현재 입력된 key 값과 같은지 비교한다.
동일하다면 key 값의 중복은 허용할 수 없으므로 새로운 value로 덮어씌우며,
만일 동일하지 않다면 해당 중복된 인덱스 위치에 새로운 리스트로
key, value 값을 저장해 준다.
그러면 위 사진과 같이 해시 테이블의 2번 인덱스에 철봉의 철 옆으로
뭐라는 값이 연결되어 들어가게 되는 것이다.
그럼 이제 값을 가져와보자.

데이터를 가져올 때도 마찬가지로
먼저 해시 테이블의 어드레스에 값이 있는지 먼저 확인하고
이중 리스트로 여러 개의 리스트가 있다면 하나씩 요소를 가져와
입력된 key와 비교하는 작업을 거친다.
일치하는 게 있으면 해당하는 value를 가져오면 끝이다.
만약 이중 리스트가 아니라도 (충돌이 아닌 곳)
요소는 어차피 하나만 나올 테니까 입력된 key와 일치하면
해당하는 value를 반환할 것이다.
여기서는 두 가지 예외처리가 돼 있는데
하나는 입력된 키를 통해 어드레스 위치를 확인했을 때
입력된 값이 아예 없는 경우 비어 있으니까 None을 반환하고,
두 번째는 입력된 키를 통해 어드레스 위치에 값이 존재는 하는데
입력된 key와 일치하는 리스트가 없을 때 가져올 값이 없으므로
마찬가지로 None을 반환한다.
이런 상황이 생기는 이유는 데이터를 아스키코드로 바꾸고
해시 함수를 통해 어드레스 값을 만들어내는데,
key가 달라도 어드레스 값(해시값)이 일치하게 되는 경우가 생기기 때문이다.
위에 보면 'Cheol'과 'What'의 경우가 이에 해당한다.
C와 W는 서로 다른 key이지만 이를 아스키코드로 변경 후
해시 함수를 통하면 같은 어드레스를 가지기 때문이다.
다음 방법으로는 개방 주소법이 있는데
연결 주소법과는 다르게 비어 있는 인덱스를 찾는 방식이다.
찾는 방법에 따라 위에 정리해 놓았듯 3가지 정도로 나뉘는데
반복문을 통해 해시 테이블 전체를 뒤지는 거라고 보면 된다.
이 부분은 별도로 소스코드로 구현하진 않았다.
참고사항
나는 ord() 함수를 통해 입력값의 첫 글자를 따서
아스키코드로 변환 후 해시 함수를 사용했는데
파이썬에는 hash() 함수가 별도로 존재한다.
입력된 값을 아예 랜덤한 해시값으로 만들어준다.
다만 어드레스로 쓰기엔 매우 긴 숫자가 나오므로
해시 함수를 별도로 돌려서 한 자릿수의 어드레스로 뽑아내주는 게 좋다.이 hash() 함수의 특징은 같은 데이터를 넣어도 해시값이
변화한다는 것이다.
해시값이 변화해도 원래의 데이터는 그대로이기 때문에
ord()를 대신해 hash() 써서 구현할 수도 있다.
로드 팩터(load factor)
해시 테이블의 효율적인 활용을 위해 로드 팩터라는 개념이 쓰이는데
여기서 로드 팩터란 해시 테이블이 얼마나 가득차 있는지를 측정하는 지표를 말한다.
Load Factor = 해시 테이블에 입력된 key의 개수/해시 테이블 전체 인덱스 개수
로드 팩터를 활용해서 현재 해시 테이블의 상태를 체크하여
해시 함수를 재작성할지, 해시 테이블의 크기를 재조정할지 결정할 수 있다.
로드 팩터를 낮출수록 해시 테이블의 성능은 올라간다.
