
- Transaction
- Database Lock
- Isolation Level
- MySQL은 아니지만 분산 시스템에서 트랜잭션 관리법
트랜잭션이란 무엇인가?
데이터베이스 관리 시스템에서 실행하는 작업의 단위.
데이터베이스를 일관된 상태로 유지하고 데이터의 무결성을 보장하기 위해 사용함.
ACID - 원자성, 일관성, 고립성, 지속성
-
원자성
더 이상 쪼개질 수 없는 가장 작은 단위.
모두 성공하거나 모두 실패해야 함. -
일관성
트랜잭션 전후에 데이터베이스의 무결성 규칙을 준수해야 함.
오류가 없어야 한다는 뜻임.
데이터베이스가 판단하기는 어렵고 애플리케이션단에서 관리해줘야 함. -
고립성
동시에 발생하는 트랜잭션은 서로 격리되어 독립적이어야 함.
서로간에 영향을 주어서는 안 됨.
여러 격리 수준이 있는데 아래에서 다룸. -
영속성
트랜잭션이 커밋되면 그 내용은 영구적으로 보존됨.
해당 데이터 변경이 손실되지 않는다는 것을 의미함.ㅇ 단일 시스템의 경우
Write-Ahead Log(WAL)
데이터베이스 시스템은 데이터 변경이 있을 경우
실제 파일에 쓰기 전에 로그에 기록됨.
이로 인해 문제가 생겨 작업이 중간에 중단되더라도 복구 가능함.ㅇ 복제 시스템의 경우
데이터가 여러 노드에 복제되어 저장됨.
충분한 수의 노드에 데이터가 복제되었는지 확인하는 것이 중요함.
데이터 손실 방지를 위한 조치 중 하나임.
SQL 엔진과 스토리지 엔진
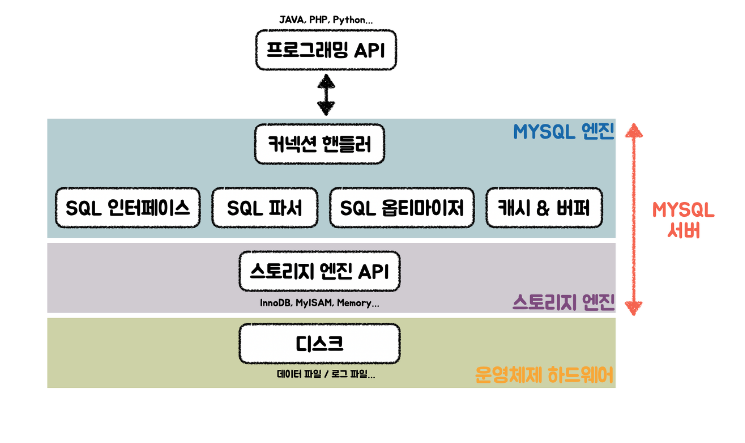
MySQL은 크게 SQL 엔진과 스토리지 엔진으로 나눌 수 있음.
위 이미지의 파란색 배경 부분 참고.
쿼리 관련된 처리를 이곳에서 함.
스토리지 엔진은 디스크에 저장하거나 읽어오는 작업을 함.
하나의 MySQL 서버 내에서 여러 개의 스토리지 엔진을 사용할 수도 있음.
SQL 엔진과 스토리지 엔진은 핸들러 API를 통해 데이터를 주고받음.
스토리지 엔진에 대해 좀더 살펴보면,
InnoDB도 있고 MyISAM 등이 있는데 요즘은 대부분 InnoDB를 사용함.
- 버퍼링
InnoDB는 데이터와 인덱스에 대한 버퍼 풀을 사용하여 데이터를 메모리에 캐싱함.
자주 액세스되는 데이터가 메모리에 유지됨.
그래서 쿼리의 읽기 속도가 향상됨.
MyISAM은 캐싱이 있긴 하지만 InnoDB만큼 효과적이진 않음.
테이블 수준의 캐싱만 지원함.
데이터와 인덱스는 파일 기반으로 저장되므로 I/O 비용이 더 높을 수 있음.
-
외래키
InnoDB는 외래키 제약조건을 지원함.
MyISAM은 외래키 제약조건을 지원하지 않음. -
트랜잭션 관리
InnoDB는 트랜잭션을 지원하고 ACID 원칙을 준수함.
MyISAM은 트랜잭션 처리와 롤백을 지원하지 않음.
결론
대부분 InnoDB를 사용함.
UNDO Log
트랜잭션의 롤백 등 데이터 일관성을 유지하는 데 사용됨.
커밋 되기 전의 모든 사항을 저장하고 있다가 문제가 생기면
이전 상태로 되돌려줌. -> 일관성 보장됨.
주로 RDBMS에서 사용됨.
트랜잭션의 변경 내용, 시간 정보, 트랜잭션 ID 등의 정보를 포함하고 있음.
데이터베이스 락
단어 그대로 데이터베이스 잠금을 의미함.
하나의 데이터를 동시에 여러 명이 조작하지 못하도록 하기 위함.
이를 통해 동시성을 보장할 수 있음.
데이터베이스 락에는 여러 종류가 있음.
글로벌 락, 테이블 락, 네임드 락, 메타데이터 락, 레코드 락, Auto Increment Lock
-
글로벌 락
전역적으로 동작하는 락
이 락이 걸리면 조회는 가능하지만 수정이 불가능해짐.
요즘은 트랜잭션이 적용돼서 잘 사용하지 않음. -
테이블 락
말 그대로 테이블을 잠금.
READ LOCK과 WRITE LOCK이 있음.
조회 락을 걸면 내가 조회할 동안 아무도 수정할 수 없게 함.
쓰기 락을 걸면 내가 쓸 동안 아무도 읽지도 쓰지 못하게 함.
MyISAM이나 MEMORY 엔진에서는 자동으로 사용되는 락임.
다만 InnoDB는 트랜잭션이 지원되므로 이 락은 불필요함.
-
네임드 락
전역적으로 동작하는데 내가 임의로 락을 잡을 수 있음.
락의 타임아웃 설정이 가능함.
다양한 로직 처리에 유리할 수 있음. -
메타데이터 락
테이블 정보를 수정할 때 자동으로 획득되는 락임. -
레코드 락
스토리지 엔진단에서 잡는 락을 말함.
row의 index에 락을 획득한다고 보면 됨. -
Auto Increment Lock
여러 클라이언트가 동시에 데이터를 추가하려고 할 때를 대비함. (동시성 처리 개선)
같은 PK 가진 row가 여러 개 생기는 것을 방지함. (일관성 유지)
하지만 병목 현상으로 인해 성능 저하가 생길 수 있음.
Isolation level
격리 수준을 지정할 수 있는데 각 단계는 아래와 같음.
-
READ UNCOMMITTED
가장 낮은 격리 수준임.
다른 트랜잭션에서 커밋되지 않은 데이터를 읽을 수 있음.
데이터 무결성과 일관성을 보장하지 않음.ㅇ Dirty Read
한 트랜잭션이 커밋되지 않은 다른 트랜잭션의 내용을 읽는 것을 말함.
무결성을 해치게 됨.ㅇ Dirty Write
한 트랜잭션이 커밋되지 않은 다른 트랜잭션에서 사용 중인 데이터를
수정하거나 덮어쓰는 상황을 말함.
무결성을 해치게 됨. -
READ COMMITTED
다른 트랜잭션에서 커밋된 데이터만 읽거나 수정할 수 있음.
다만 여러 명이 동시에 같은 레코드를 수정하는 걸 막을 순 없음.
커밋된 데이터의 일관성을 보장하며, 커밋되지 않은 데이터는 읽지 못함.
READ COMMITTED는 Dirty Read와 Dirty Write를 방지할 수 있지만
Non-Repeatable Read, Phantom Read라는 문제점이 있음.ㅇ Non-Repeatable Read
한 트랜잭션에서 동일한 쿼리를 여러 번 실행하면
다른 트랜잭션에서 변경한 데이터가 반영되어 결과가 달라지는 걸 말함.BEGIN; SELECT * FROM account WHERE account_id = 1; UPDATE account SET balance = balance + 100 WHERE account_id = 1; COMMIT;잔액을 조회하는 트랜잭션과 잔액을 업그레이드하는 트랜잭션이 있을 때,
1. 조회 트랜잭션에서 잔액 조회 쿼리 날림
2. 수정 트랜잭션에서 잔액 증가 쿼리 날림
3. 조회 트랜잭션에서 잔액 조회 쿼리 날림 -> 1번과 다른 결과를 반환하게 됨.ㅇ Phantom Read
한 트랜잭션에서 조회한 데이터가 다른 트랜잭션에서 추가되거나 삭제돼서
조회 결과가 달라지는 걸 말함.BEGIN; SELECT * FROM account WHERE balance > 100; INSERT INTO account (balance) VALUES (101); COMMIT;1. 첫 번째 트랜잭션에서 잔액이 100보다 큰 계좌를 조회.
2. 두 번째 트랜잭션에서는 잔액이 101인 계좌를 추가.
3. 첫 번째 트랜잭션에서 동일한 쿼리 날리면 2번의 결과가 반환됨.READ COMMITTED는 성능이 좋긴 하지만 위 두 가지 이슈 같은
데이터의 부정합 문제가 발생할 수 있음.이를 막기 위해서는
SELECT FOR UPDATE, SERIALIZABLE, 동시성 제어 알고리즘 등을 통해
위 두 문제를 완화할 수 있음.ㅇ SELECT FOR UPDATE
다른 트랜잭션이 해당 데이터를 변경할 수 없도록 락을 걸어줌.ㅇ SERIALIZABLE
가장 높은 격리 수준. 다른 트랜잭션이 변경한 데이터를 조회할 수 없음.ㅇ 동시성 제어 알고리즘(2단계 락킹, MVCC, Timestamp Ordering)
2단계 락킹은 데이터베이스 리소스를 획득하는 단계와 해제하는 단계를 나눠서
동시성 제어를 수행함. 성능 저하될 수 있음.MVCC는 테이블에 여러 버전을 저장해서 동시성 제어를 수행함.
성능은 좋으나 데이터 부정합이 발생할 수 있음.Timestamp Ordering은 트랜잭션에 타임스탬프를 부여해서 동시성 제어를 수행함.
타임스탬프가 낮은 트랜잭션은 높은 트랜잭션에 의해 영향을 받지 않게 함.
성능도 좋고 데이터 부정합 발생 가능성도 낮음.
-
REPEATABLE READ
가장 많이 쓰이는 격리 레벨임.
트랜잭션이 시작될 때 읽은 데이터는 종료될 때까지 동일한 값을 유지함.
다른 트랜잭션이 데이터를 수정하더라도 해당 트랜잭션에서 읽은 데이터는 변하지 않음.트랜잭션이 발생되는 시점에 스냅샷을 떠놓고 그걸 통해 read/write를 하는 방식임.
-
SERIALIZABLE
가장 높은 격리 수준임.
여러 트랜잭션이 동시에 실행되는 것처럼 보이지 않도록 데이터를 격리함.
데이터의 무결성과 일관성을 가장 엄격하게 유지함.
다만 성능 저하가 발생할 수 있음.
Lost Updates
여러 개의 트랜잭션들이 동시에 write를 시도하는 경우에 발생하는 문제.
Read -> modify -> write 할 때 특정 트랜잭션의 write가 무시될 수 있음.
data = 1이라고 할 때,
1. 트랜잭션 T1이 data를 조회
2. 1인 걸 확인 후 +1 연산.
3. 트랜잭션 T2가 data를 조회. data = 1인 걸 확인.
4. T1의 연산 결과 저장. data = 2가 됨.
5. T2도 +1을 함.
6. T2의 연산 결과 저장. data = 2가 됨.
7. T1의 write는 무시되는 결과 발생.
이러한 상황을 레이스 컨디션이라고 함.
레이스 컨디션(Race Condition)이란?
두 개 이상의 프로세스가 공통 자원에 접근해 읽거나 쓸 때
경합 상황이 벌어지는 것을 말함.
공통 자원에 대한 접근이 어떤 순서로 이루어지냐에 따라
그 실행 결과가 달라짐.
모든 프로세스에 원하는 결과를 보장할 수 없다는 것이 문제임.
Lost Updates에 대한 해결 방법은 아래와 같음.
-
Atomic write operation
여러 수정 작업을 단일한 원자적 작업으로 처리해서
중간 단계에서 작업이 실패해도 데이터 일관성을 유지할 수 있게 함.
보통 많은 DB들이 이 기능을 제공하고 있음.
DB 내부에서 Execlusive Lock을 통해 구현됨.(FOR UPDATE 키워드 사용)
-> update 할 땐 다른 트랜잭션들이 해당 자원을 읽고 쓸 수 없게 만듬. -
Automatically detecting lost updates
병렬 작업을 허용함. 다만 Transaction manager가 lost update를 감지하면
트랜잭션을 중단하고 강제로 read -> modify -> write를 재시도함. -
Compare-and-set
CAS 연산이라고 부르는 방법임.
업데이트 전에 값이 변경된 이력이 있는지 확인하고 업데이트를 진행하는 걸 말함.
처음 read 했을 때의 값과 업데이트 시도할 때의 값이 다르다면 업데이트 안 함.
만약 변경이 일어났다면 read -> modify -> write 연산을 재시도함.
분산 시스템에서 트랜잭션 관리법
Conflict resolution and replication
분산 시스템에서는 여러 노드에 복제된 데이터가 동시에 업데이트될 수가 있는데
이로 인해 일관성 유지가 어려워질 수 있음.
특히 다중 리더가 존재할 경우 리더 간 업데이트와 충돌될 수 있음.
이를 해결하기 위해선 충돌이 발생하게 두고,
어플리케이션단에서 어떤 것이 옳은 업데이트인지 결정하도록 함.
일반적인 충돌 해결방식 중에 Last write wins라는 게 있는데,
가장 마지막에 업데이트 된 데이터를 최신으로 인정하는 방식임.
하지만 이 방법은 위에서 언급한 Lost Updates 문제를 쉽게 일으킬 수 있음.
정리하자면,
두 개 이상의 동시 쓰기로 문제가 발생한다면
해당 사이클을 통째로 묶든지,
동시 수행을 제한하든지,
일단 진행하고 오류 발견 시 다시 시도하는 형태로 해결함.
분산 환경이라면 동시다발적으로 여러 노드에서 복제와 연산이 일어나므로,
싱글 리더를 통해 제어하든지,
마지막에 write 한 값으로 저장하든지,
어플리케이션단에서 관리하면 됨.
