
Spring Boot 편
1. @Builder 보다는 생성자
@Builder를 사용해서 객체를 생성하는 경우
@Builder
public class ExampleDto {
private String email;
private String password;
}public ExampleDto test() {
return ExampleDto.builder()
.email("이메일")
.password("비밀번호");
}- 생성자를 사용해서 객체를 생성하는 경우
@AllArgsConstructor
public class ExampleDto {
private String email;
private String password;
}public ExampleDto test() {
return new ExampleDto("이메일", "비밀번호");
}얼핏 보면 Builder가 어느 필드에 값이 들어가는지 한눈에 보여 가독성이 좋습니다.
하지만 Builder는 필드에 값이 들어갈 것을 보장해주지 않습니다.
필드에 값이 주어지지 않으면 null을 대입하고, 컴파일 에러를 일으키지도 않습니다.
심지어 IDE에서 자동으로 링크해주지 않아서 필드가 수정될 시 ExampleDto.builder() 문자열 자체를 검색해야 하는 경우도 많습니다.
// ExampleDto.java
@Builder
@Getter
public class ExampleDto {
private String email;
private String password;
private String name; // 필드를 추가
}
public ExampleDto test() {
return ExampleDto.builder()
.email("이메일")
.password("비밀번호") // 오류를 일으키지 않고 name에 null 대입
.build();
}
public void willFail() {
ExampleDto dto = test();
dto.getName().equals("이름"); // NullPointerException: name is null
}따라서 생성자를 사용해서 객체를 생성할 때 아예 값이 들어가는 것을 보장해주면
더 예측 가능한 코드가 될 것입니다.
'생성자의 몇번째 매개변수에 어떤 것이 들어갈 지 알기 힘들다' 라는 단점이 있을 수 있지만,
요즘 IDE는 필요한 경우에 매개변수의 이름을 표시해주기도 하며,
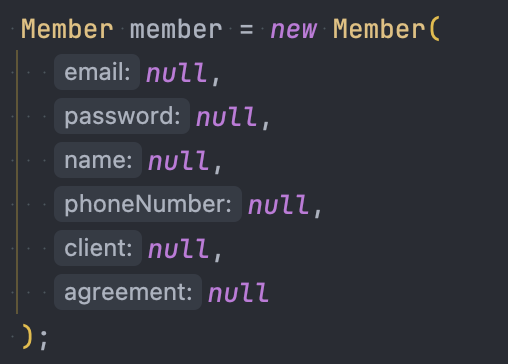
예시를 위해 모두 null을 넣어줬습니다. (null 일땐 무조건 보여주더라구요)
차라리 타입 불일치로 오류를 일으켜주는 것이 휴먼 에러를 더 줄일 수 있을 것입니다.
2. 주입을 사용할 때 @RequiredArgsConstructor 어노테이션 사용
Spring 자체에서도 필드 주입을 지양하는 것은 유명합니다.
따라서 되도록이면 생성자 주입을 사용해야하는데, 이때 생성자를 직접 작성하기보단
Lombok의 @RequiredArgsConsturctor를 사용합니다.
@RequiredArgsConsturctor는 final로 선언된 필드에 대하여 생성자를 자동 생성해줍니다.
이것으로 코드가 깔끔해집니다.
@Service
@RequiredArgsConstructor
public class ExampleService {
private final ExampleRepository exampleRepository;
}이 형태는 아래와 같은 과정을 거쳐서 만들어집니다.
// 처음 형태
@Service
public class ExampleService {
private final ExampleRepository exampleRepository;
@Autowired
public ExampleService(ExampleRepository exampleRepository) {
this.exampleRepository = exampleRepository;
}
}@Service
public class ExampleService {
private final ExampleRepository exampleRepository;
// @Autowired 생략 가능
public ExampleService(ExampleRepository exampleRepository) {
this.exampleRepository = exampleRepository;
}
}@Service
@RequiredArgsConstructor // 생성자 축약
public class ExampleService {
private final ExampleRepository exampleRepository;
}3. application.yml은 각 설정값마다 필요한 도메인으로 나눔
도메인 별로 나누지 않았을 경우 (환경으로 나눔)
# application.yml
---
spring:
config:
activate:
on-profile:
- ci
- local
server:
port: 80
jpa:
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
"[format_sql]": true
datasource:
url: ***
username: ***
password: ***
---
spring:
config:
activate:
on-profile: alpha
server:
port: 5000
jpa:
show-sql: true
hibernate:
ddl-auto: validate
properties:
hibernate:
"[format_sql]": true
datasource:
url: ***
username: ***
password: ***
---
spring:
config:
activate:
on-profile: prod
server:
port: 5000
jpa:
show-sql: false
hibernate:
ddl-auto: validate
properties:
hibernate:
"[format_sql]": false
datasource:
url: ***
username: ***
password: ***'이 환경에서는 이 설정값이다'라고 직관적으로 보일 수 있으나,
추후 설정값을 수정해야할 때 같은 도메인들의 값들이 어디에 있는지 찾기 힘듭니다.
보통 개발할 때는 도메인 별로 설정값들이 나뉠 때가 많기 때문에
도메인 별로 설정값들을 나눠두면 유지보수 하기 편합니다.
(application-프로필이름.yml 으로 나누는 방법도 동일한 문제가 존재합니다.)
도메인 별로 나눌 경우
# application.yml
spring:
config:
import:
- database.yml
- security.yml
- springdoc.yml
- logging.yml
- sentry.yml
- server.yml
- wordpress.yml
- messages.yml# database.yml
---
spring:
config:
activate:
on-profile:
- ci
- local
jpa:
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
"[format_sql]": true
datasource:
url: ***
username: ***
password: ***
---
spring:
config:
activate:
on-profile: alpha
jpa:
show-sql: true
hibernate:
ddl-auto: validate
properties:
hibernate:
"[format_sql]": true
datasource:
url: ***
username: ***
password: ***
---
spring:
config:
activate:
on-profile: prod
jpa:
show-sql: false
hibernate:
ddl-auto: validate
properties:
hibernate:
"[format_sql]": false
datasource:
url: ***
username: ***
password: ***# server.yml
---
spring:
config:
activate:
on-profile:
- ci
- local
server:
port: 80
---
spring:
config:
activate:
on-profile: alpha
server:
port: 5000
---
spring:
config:
activate:
on-profile: prod
server:
port: 50004. Json으로 받게 되는 DTO에는 class 보다 record 사용
코드가 깔끔해집니다.
@Getter, @AllArgsConstructor 같은 어노테이션도,
private final 같은 키워드도 붙이지 않아도 됩니다.
record에는 DTO로 사용할 때 필요한 모든 것이 이미 들어가 있습니다.
Java에서 아예 DTO로 사용하라고 만들어준 셈입니다.
@Getter
@AllArgsConstructor
public class MemberRequestDto {
private final @NotBlank String email;
private final @NotBlank String name;
private final String phoneNumber;
private final String memo;
private final @NotNull MemberRole role;
}
public record MemberRequestDto(
@NotBlank String email,
@NotBlank String name,
String phoneNumber,
String memo,
@NotNull MemberRole role
) {}하지만 이미 class로 구현되어 있다면 굳이 건드리지 않는게 좋을 것입니다.
getEmail()이 email()로 바뀔 뿐만 아니라,
final이 기본적으로 붙어서 필드가 바뀔 것을 산정하고 구현된 로직이 있을 수 있기 때문입니다.
만약에 record를 적용한다면, 새로운 로직 또는 프로젝트에 적용하는 것이 좋을 것 같습니다.
5. Json DTO에 사용되는 필드에는 Wrapper Class 사용
Json Response의 경우는 상관없지만,
Json Request의 경우에는 Frontend의 실수나 예상치 못한 변수로 DTO의 필드에 null이 들어올 수 있습니다.
그 null이 들어오는 것을 DTO에서 원시타입(Primitive type)으로 받는다면
예상치 못한 동작을 유발할 수 있습니다.
예를 들어서 아래와 같은 DTO가 있다고 가정합니다.
public record ExampleRequestDto(
@NotNull int sequence,
@NotBlank @Size(max = 255) String name
) {}그리고 이 DTO에 맞춰 아래와 같은 Json 형식으로 요청을 보내지만,
모종의 이유로 sequence에 null이 들어가게 된다면
{
"sequence": null, // 실수!
"name": "example"
}null이 들어갈 수 없는 원시타입에 맞추기 위하여,
Spring은 필드에 억지로 0을 집어넣습니다.
@NotNull 어노테이션이 먼저 동작하지 않습니다.
실패해야 할 동작이지만 요청이 성공하며 후에 오류를 잡기 위해 시간을 쓰게 되죠.
따라서 Json에서 변환되는 DTO에서는 웬만하면 Wrapper Class로 필드를 선언하여
좀 더 예상 가능한 작동을 하도록 합니다.
public record ExampleRequestDto(
@NotNull Integer sequence,
@NotBlank @Size(max = 255) String name
) {}그럼 정상적으로 null 필드에 대한 Exception이 반환되어, 올바른 조치를 취하게 할 수 있습니다.

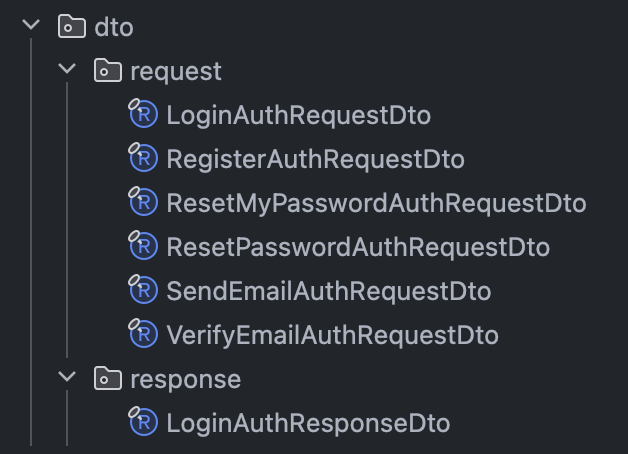
6. Request 시에 사용하는 DTO와 Response 시에 사용하는 DTO 분리
두 DTO의 형태가 비슷하거나 아예 같을 때도 있는데,
그 요구사항은 수시로 바뀔 수 있습니다.
그리고 보통은 두 DTO가 달라져 나누게 되는 상황이 되는 경우가 많았습니다.
처음부터 분리하고 시작하는 것도 나쁘지 않은 방법인 것 같습니다.
저의 경우에는 아예 클래스명에 Request와 Response를 붙여 분리해두고,
패키지도 분리해둡니다.
이렇게 개발 시간을 단축시킬 수 있는 몇가지 저만의 규칙을 적어봤습니다.
어쩌면 위의 규칙들이 성가셔보이고 '굳이 이렇게까지 해야하나?' 싶을 수 있는데,
해보시면 아시겠지만 이런 사소한게 2~3시간 잡아먹게 합니다... 심하면 한달까지 갈 때도 있습니다.
그러기엔 개발자에겐 시간이 생명이니 기반을 단단하게 잡고 가자구요! :)
앞으로 또 개발하면서 추가할만한 내용이 있으면 이 시리즈에 추가하도록 하겠습니다.
