훈련세트와 테스트세트 : 모델을 훈련 시키는 훈련 세트와 검증하는 테스트 세트로 나누어 학습하기
train_input = fish_data[:35] #슬라이싱
train_target = fish_target[:35]
test input = fish_data[35:]
test_target = fist_target[35:]
2개의 특성(도미,빙어) 을 가진 49개의 생물 -> 훈련세트 35개 , 테스트세트 14개로 나누어준다.
- 테스트 세트에서 평가하기
from sklearn.neighbors improt KNeighborsClassifier
kn = KNeighborsClassifier() -> 모델선언
kn = kn.fit(train_input , train_target) -> fit 메서드로 학습
kn.score(test_input , test_target) -> score 메서드로 테스트
0.0샘플링 편향 :
테스트세트 ,훈련세트는 특성 2가지를 골고루 섞어주어야 함. 한쪽으로 데이터가 쏠리지 않도록
- 넘파이 사용하기
import numpy as np
imput_arr = np.array(fish_data)
target_arr = np.array(fish_target)
print(input_arr)
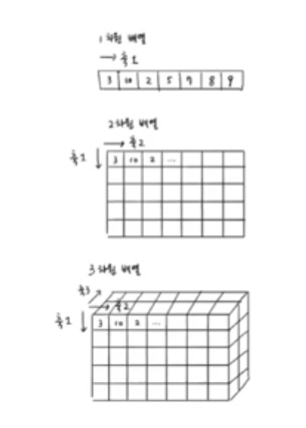
- 데이터 섞기
index = np.arange(49)
np.random.shuffle(index) -> random,shuffle 함수는 무작위로 섞어주는 함수
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(test_input[:,0] , test_input[:.1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
두번째 머신러닝 프로그램
kn = kn.fit(train_input , train_target)
kn.score(test_input, test_target)
1.0
python 의 배열 라이브러리인 numpy 패키지를 사용하여 머신러닝을 해보았습니다.
훈련세트와 테스트세트중 한쪽으로 데이터가 많이 몰리는 것(샘플링 편향) 을 방지하기 위해
파이썬으로 할 수 있지만 numpy 패키지를 사용해보았고,
numpy 를 사용하여 데이터를 섞고 나눌 때 배열자체를 섞지 않고 (특성 데이터와 타겟 데이터가 잘 못 섞일 수 있어서) 따로따로 쌍을 이루어서 섞어야 하기 때문에 배열에 인덱스 배열을 만들어서 인덱스를 섞은 후, 섞인 인덱스를 가지고 배열 슬라이싱 기능을 사용해서 훈련 세트와 테스트 세트를 나누었다. 그 후에 최근접모델을 다시 만들어서 평가 하니 결과가 더 좋게 나왔다.

Analytics Engineer