
1. Introduction
ResNet 논문은 기존의 딥러닝 모델이 네트워크 깊이가 깊어질수록 오히려 정확도가 떨어지는 현상, 즉 degradation problem을 관찰하며 시작된다. 이는 단순히 overfitting의 문제가 아닌, optimization의 어려움에서 비롯된다고 저자는 주장한다. 깊은 네트워크는 이론적으로 더 높은 표현 능력을 가질 수 있지만, 실제 학습에서는 gradient vanishing, 학습 불안정 등의 이유로 성능 저하가 발생한다.
이 논문을 읽는 동안 나는 먼저 "gradient 소실과 폭발"의 메커니즘을 다시 짚어보았고, **역전파(backpropagation)**와 SGD의 수렴 특성이 깊은 네트워크에서 어떤 방식으로 제한되는지 학습했다. 또한, **정규화된 초기화 기법(He initialization)**과 Batch Normalization이 이러한 문제를 어느 정도 완화시킬 수는 있지만, 근본적인 해결책은 아니었다는 점도 확인했다.
2. Related Work
기존의 깊은 신경망들은 네트워크 깊이를 늘릴수록 **학습 오류(training error)**가 증가하는 문제가 있었다. 이는 더 깊은 네트워크가 단순히 더 많은 파라미터를 가진다는 것과는 별개로, 최적화의 어려움을 반영한다.
대표적인 선행 연구로는 Highway Networks와 FitNet이 있으며, 이들은 중간 층 supervision 또는 gate를 활용해 정보 흐름을 조절하려 했다. 하지만 ResNet은 이보다 더 단순하면서도 효과적인 방법인 identity shortcut connection을 제안한다.
3. Deep Residual Learning
Residual Learning의 기본 아이디어
기존의 딥러닝 구조는 각 블록이 **입력 **로부터 직접적으로 원하는 출력 를 학습하도록 한다. 하지만 ResNet은 이를 다음과 같이 재정의한다:
여기서:
- : 우리가 실제로 학습하고자 하는 mapping
- : 학습할 잔차 함수(residual function)
- : identity connection을 통해 shortcut으로 전달되는 입력
이 구조는 학습이 어려운 전체 함수를 학습하는 대신, **입력과 출력의 차이(잔차)**를 학습하는 방식이다. 실제로 많은 경우 는 입력 와 유사하므로, 가 0에 가까운 작은 값이면 충분한 경우가 많다.
이 구조 덕분에 역전파 시 gradient가 shortcut을 따라 더 깊은 층까지 효과적으로 전달될 수 있어, vanishing gradient 문제가 완화된다.
수식 정리
Residual Block 내부 연산은 다음과 같다:
- : 두 개 이상의 weight layer를 포함한 비선형 transformation
- : identity shortcut connection
- : 블록의 출력
만약 차원이 다르면 를 projection (예: 1x1 conv)으로 바꿔주어 합 연산이 가능하게 만든다.
4. Identity Mapping by Shortcuts
이 섹션에서는 identity shortcut이 학습을 얼마나 단순화시키는지를 설명한다.
이 구조는 추가적인 파라미터 없이도 기존의 네트워크보다 훨씬 더 깊은 구조(최대 152 layers)를 학습할 수 있게 해주며, 이는 plain network 대비 명확한 성능 향상으로 이어졌다.
또한, 저자들은 학습을 단순히 “깊게 만드는 것”이 아니라, 학습이 실제로 이뤄지는지를 강조하며, residual 구조가 효율적인 정보 흐름을 제공한다는 점을 수치 실험과 함께 제시한다.
5. Experiments
ResNet은 ImageNet 분류 과제에서 가장 높은 성능을 기록했다. 특히, ResNet-152는 plain network보다도 더 낮은 error rate을 기록했으며, top-5 error는 3.57%로, ILSVRC 2015 classification task 1위 성능이었다.
또한, ResNet은 CIFAR-10에서도 실험되었고, 적은 파라미터 수에도 불구하고 더 깊은 구조가 더 나은 일반화 성능을 보였다. 이는 Residual Learning이 단순히 깊이에 대한 방어 수단을 넘어서, 일반화 성능까지 확보하는 학습 구조임을 보여준다.
내 실험 추가: ResNet18 vs SimpleCNN on CIFAR-10
코랩에서 직접 CIFAR-10 데이터셋을 사용하여 ResNet18과 내가 만든 SimpleCNN을 비교 실험했다.
다음은 각 모델의 학습 및 테스트 정확도 변화이다.
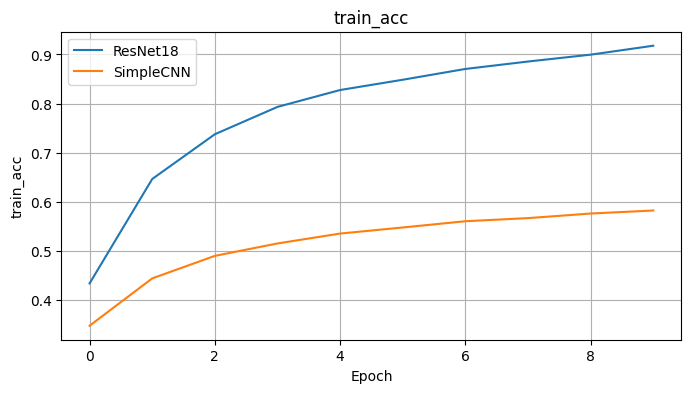
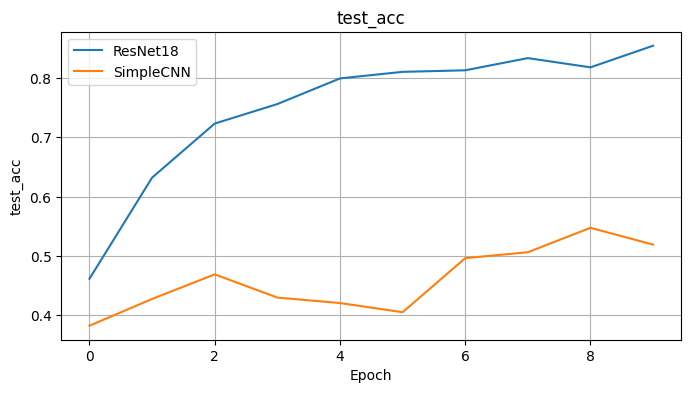
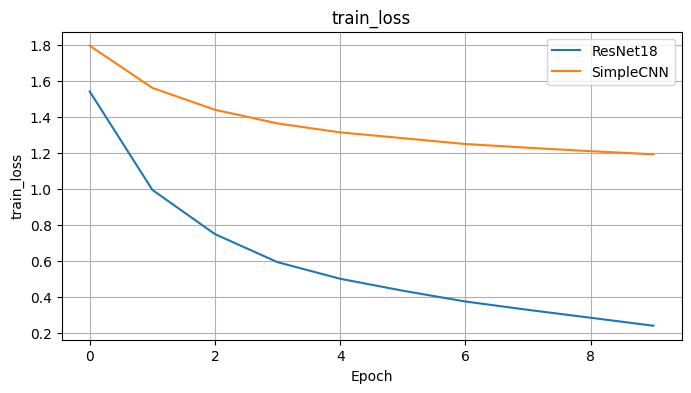
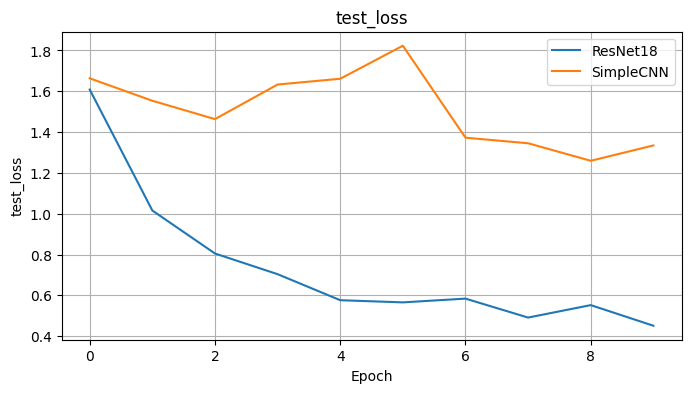
→ 실험 결과, ResNet18이 단순 CNN 대비 훨씬 더 빠르게 수렴하고, 일반화 성능(테스트 정확도)도 높게 유지함을 확인했다. 이는 residual 구조의 학습 안정성과 효율성을 직접 체감한 경험이었다.
6. 마무리 및 개인적인 관점
ResNet 논문은 단순한 구조 제안 이상의 가치가 있었다. 이 논문을 읽으면서, 나는 등장하는 개념 하나하나를 따로 정리하면서 전체 구조를 이해하는 방식으로 접근했다. 단축 연결, 잔차 학습, 수렴 안정화, gradient 흐름 등은 모두 딥러닝이 왜 잘 작동하는지를 설명해주는 단서들이었다.
이번 리뷰를 작성하면서 다음과 같은 개념들은 아직 명확하게 이해되지 않아 추후 학습할 주제로 메모를 남긴다:
- Pre-activation Residual Block의 구체적 수식 및 동작 원리
- Gradient flow가 수렴에 미치는 영향의 수치적 분석
- ResNet이 왜 optimization landscape을 smoother하게 만드는지에 대한 이론적 근거
- BatchNorm과 shortcut connection이 상호작용하는 방식
마치며
앞으로도 논문을 단순히 읽는 것을 넘어서, 배경 지식 → 개념 학습 → 수식 분석 → 전체 흐름 이해라는 내 방식대로 꾸준히 확장해가고자 한다.

Real recognize real.
진짜는 진짜를 알아보는 법이죠. 글 잘 읽었습니다!!!!