
■ 메시지 브로커 (message broker)
송신자의 메시지 프로토콜 형식으로부터의 메시지를 수신자의 메시지 프로토콜 형식으로 변환하는 중간 프로그램 모듈이다.
■ 메시지 브로커의 두 가지 방식
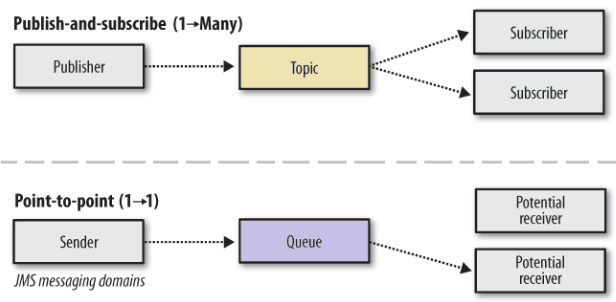
● Topic
JMS 에서 Topic은 발행(publish)과 구독(subscribe)을 구현한 것이다.
메시지를 발행(publish)하면 관심있어하는 모든 구독자(subscribers)에게 전달된다.
- 따라서 다수의 구독자가 메시지 카피본을 받을 수 있게 된다.
브로커가 메시지를 받는 시점에 활성 구독(active subscription)이 있는 구독자만 메시지를 받을 수 있다.
● Queue
JMS 에서 Queue 는 로드 발란서를 구현한 것이다.
하나의 메시지는 정확히 하나의 소비자(consumer)에게 전달된다.
- 메시지를 보내는 시점에 소비자(consumer)가 하나도 없는 경우 소비자가 메시지 처리가 가능해 질 때까지 보관된다.
- 소비자가 메시지를 받았는데, closing 전까지 인지(acknowledge)되지 않을 경우 메시지는 다른 소비자에게 재전송된다.
■ 대표적인 메시지 브로커 3가지
Apache Kafka (Topic)
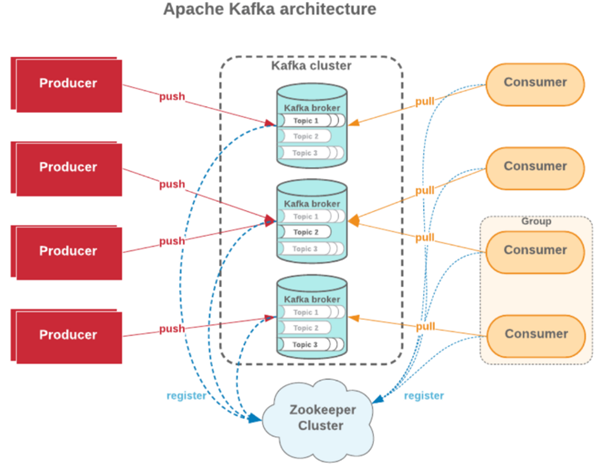
실시간 스트리밍 데이터 파이프라인 및 애플리케이션을 구축하기 위한 오픈 소스. 고성능, 내결함성 및 확장 가능한 플랫폼이다.
Kafka는 스트리밍 데이터 저장소로 스트리밍 데이터를 생산하는 애플리케이션(생산자)을 데이터 저장소에서 스트리밍 데이터를 소비하는 애플리케이션(소비자)와 데이터 저장소로 분리한다.
■ Apache kafka 구성요소
- 레코드 : 키(선택 사항), 값 및 타임스탬프가 있을 수 있다, 한 번 작성되면 수정이 불가능하다.
- 주제 : 레코드의 스트림이며 피드 이름으로 생각할 수 있다.
- 로그 : 디스크에 있는 주제의 저장소
- 파티션 및 세그먼트 : 각 토픽 로그를 세분화하는 역할을 한다.
■ Kafka의 네 가지 주요 API
- Producer API : 데이터 스트림을 Kafka 클러스터의 주제로 보낸다.
- Consumer API : Kafka 클러스터의 주제에서 데이터 스트림을 읽는다.
- Streams API : 데이터 스트림을 입력 주제에서 출력 주제로 변환한다.
- Connect API : 일부 소스 시스템 또는 앱에서 Kafka로 일관디게 가져오거나 Kafka에서 다른 것으로 푸쉬하는 커텍터를 구현한다.
■ Kafka의 핵심 기능 요약
- 높은 처리량: 대기시간이 2ms 미만인 머신 클러스터를 사용하여 제한된 네트워크 처리량으로 메시지를 전달한다.
- 확장성
- 영구 저장소
- 고가용성
- 파이프라인의 관리를 쉽게 해줌
Amazon Kinesis (Topic)
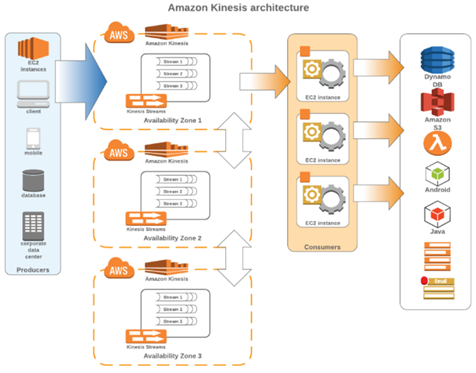
AWS Kinesis Streams를 사용하면 스트리밍 데이터의 대규모 데이터 수집 및 실시간 처리가 가능하다. 동일한 순서로 레코드를 읽거나 재생하는 기능뿐만 아니라 레코드의 순서를 보장한다.
Kinesis 고유의 주요 기능은 시간당 수백 테라바이트의 대용량 데이터 스트림을 처리하는 기능이다.
이는 운영 로그, 소셜 미디어 피드, 게임 내 소액 거래 또는 플레이어 활동 또는 금융 거래와 같은 소스에서 지속적으로 캡쳐될 수 있다. 이전 기술에 비해 장점은 특정 앱의 개발 프로세스를 단순화할 수 있다는 것이다.
■ Amazon Kinesis 구성요소
- 샤드 : Amazon Kinesis 데이터 스트림의 기본 처리량 단위
- 데이터 생산자 : 데이터 레코드가 생성될 때 내보낸다.
- 데이터 소비자 : 스트림의 모든 샤드에서 데이터가 생성될 때 데이터를 검색한다.
- 스트림 : 샤드의 논리적 그룹
- 레코드 : Amazon Kinesis 스트림에 저장된 데이터 단위
- 파티션 키 : 일반적으로 사용자 ID 또는 타임 스탬프와 같은 의미 있는 식별자
- 시퀀스 번호 : 각 데이터 레코드에 대한 고유 식별자
■ Amazon Kinesis의 특징
- 최대 1MB의 레코드 크기 허용
- 메시지 수준이 아닌 샤드 수준에서 작동한다.
- Auto Scaling이 없다, 개발자는 샤드 사용량을 추적하고 필요할 때 Kinesis 스트림을 다시 샤딩 해야한다.
- 제한된 읽기 처리량 (샤드당 초당 5개의 트랜잭션)
- 스트림의 샤드 수가 최대 처리량을 결정한다.
- 여러 소비자를 단일 스트림에 연결할 수 있으며 각 소비자는 모든 레코드를 개별적으로 처리할 수 있다.
(shard-iterator 덕분에) 빅데이터를 실시간으로 처리하는 AWS이다.
Amazon SQS (Queue)
AWS Simple Queue Service(SQS)는 분산 애플리케이션 구성 요소 간에 메시지를 젖아하고 데이터를 쉽게 이동할 수 있도록 안정적이고 확장성이 뛰어난 서버리스 호스팅 대기열을 제공한다.
■ Amazon SQS의 특징
- 최대 256KB의 비교적 작은 메시지 크기 허용
- 각 메시지는 독립적으로 처리될 수 있다.
- 대기열에서 읽는 작업의 수를 조정하여 읽기 처리량을 동적으로 증가시키는 자동 조정이 가능하다.
- 메시장 시맨틱(예: 메시지 수준 승인/실패) 및 메시지 가시성 시간 초과를 제공한다.
- 표준 대기열의 경우 인플라이트 메시지 수에 대한 120,000개 제한 및 FIFO 대기열의 경우 20,000개 제한
■ 메시지 브로커 비교
Apache Kafka vs AWS Kinesis
| - | Apache Kafka | AWS Kinesis |
|---|---|---|
| 비용 | 비용이 많이 든다 | 온디맨드 |
| 사용의 용의성 | 설정에 많은 시간과 비용을 들여야 한다. | 몇 분안에 시작 가능하다. |
| 관리 오버헤드 | 높다. (자율성이 높다.) | 낮다. (자율성이 낮다.) |
| 확장성 | 확장하기 힘들다. | 몇 초만에 확장이 가능하다. |
| 처리량 | 무한 | 샤드로 확장한다, 최대 1mb 페이로드를 지원한다. |
| 내구성 | 구성이 가능하다. | 기본값의 3배정도의 내구성을 보장한다. |
| 하부구조 | 직접 관리 | AWS의 관리 |
| 쓰기-읽기 대기시간 | 100ms 미만 달성 가능 | 100ms(HTTP/2 사용) |
| 오픈 소스 | O | X |
AWS SQS vs AWS Kinesis
| AWS SQS | AWS Kinesis | |
|---|---|---|
| 메시지 내구성 | 보관기간 또는 삭제시까지 유지 | 보간기간까지 유지 (삭제 불가) |
| 메시지 보관기간 | 60초 ~ 최대 14일 | 24시간 ~ 최대 7일 |
| 순서 보장 | 표준 순서 보장 | Shard 내 순서 보장 |
| 메시지 전달 | Queue 당 여러 consumer | shard당 여러 Application 별 consumer |
| Scaling | 자동 | shard별 리샤딩이 필요하다. |
| 메시지 간 iterate | No | shard iterators |
| 전달 목적지/방식 | SQS Consumers / pull | Kinesis Consumers / pull |
