하둡(Hadoop)이란?
대용량 데이터를 분산 처리할 수 있는 자바기반의 오픈소스 프레임워크
하둡의 탄생 배경
구글에서 쌓여지는 수많은 빅데이터들을 RDBMS에 입력하고 데이터를 저장/처리하려고 시도했으나 데이터가 너무 방대해지자 실패하고 자체적으로 빅데이터를 저장할 기술을 개발하고 논문을 발표 → 더그커팅이 이 논문을 기반으로 자바로 구현함 → 하둡 탄생
하둡의 장점
-
정형화 된 데이터는 RDBMS에 저장하기가 쉽지만 비정형화된 데이터 (텍스트, 동영상, 이미지) 들은 RDBMS에 저장하기엔 사이즈도 크고 구성하기도 힘들다. 하둡은 이런 비정형화된 데이터들을 저장하고 관리하기 유용하다.
-
무료이다.
-
여러대의 서버에서 분산처리가 가능하다. ( 서버들의 자원을 합쳐서 큰 자원으로 이용이 가능하다. → 처리와 검색을 빠르게 할 수 있다. )
-
데이터를 다른 서버로 쉽게 복제할 수 있다. ( 백업으로 안정성을 상향시킨다. )
하둡 아키텍처
-
데이터 저장 (Storage Layer) : HDFS
-
데이터 분석 (Application Layer) : MapReduce, Other Application ...
-
자원 관리 (Resource Management Layer): YARN
하둡 에코 시스템
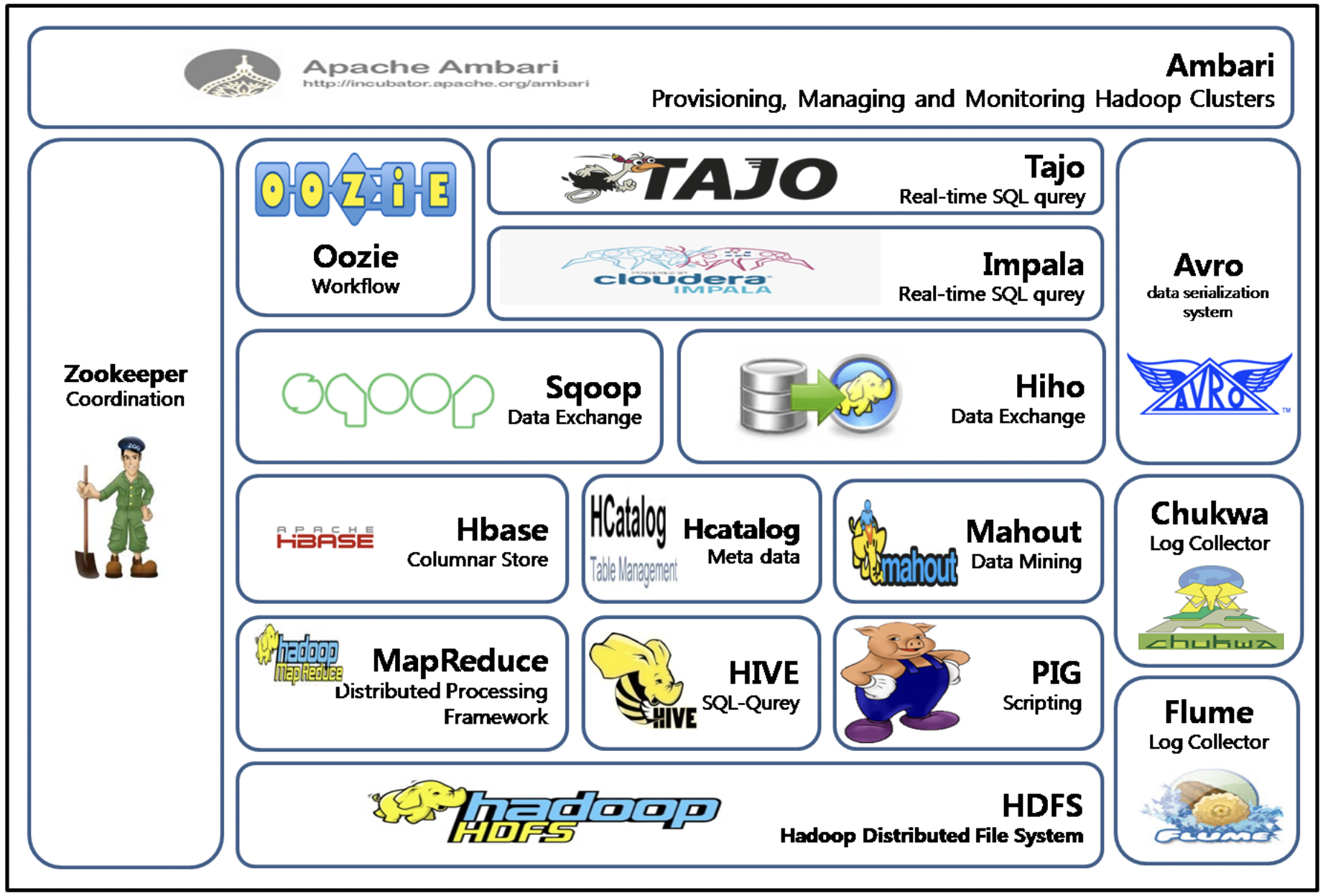
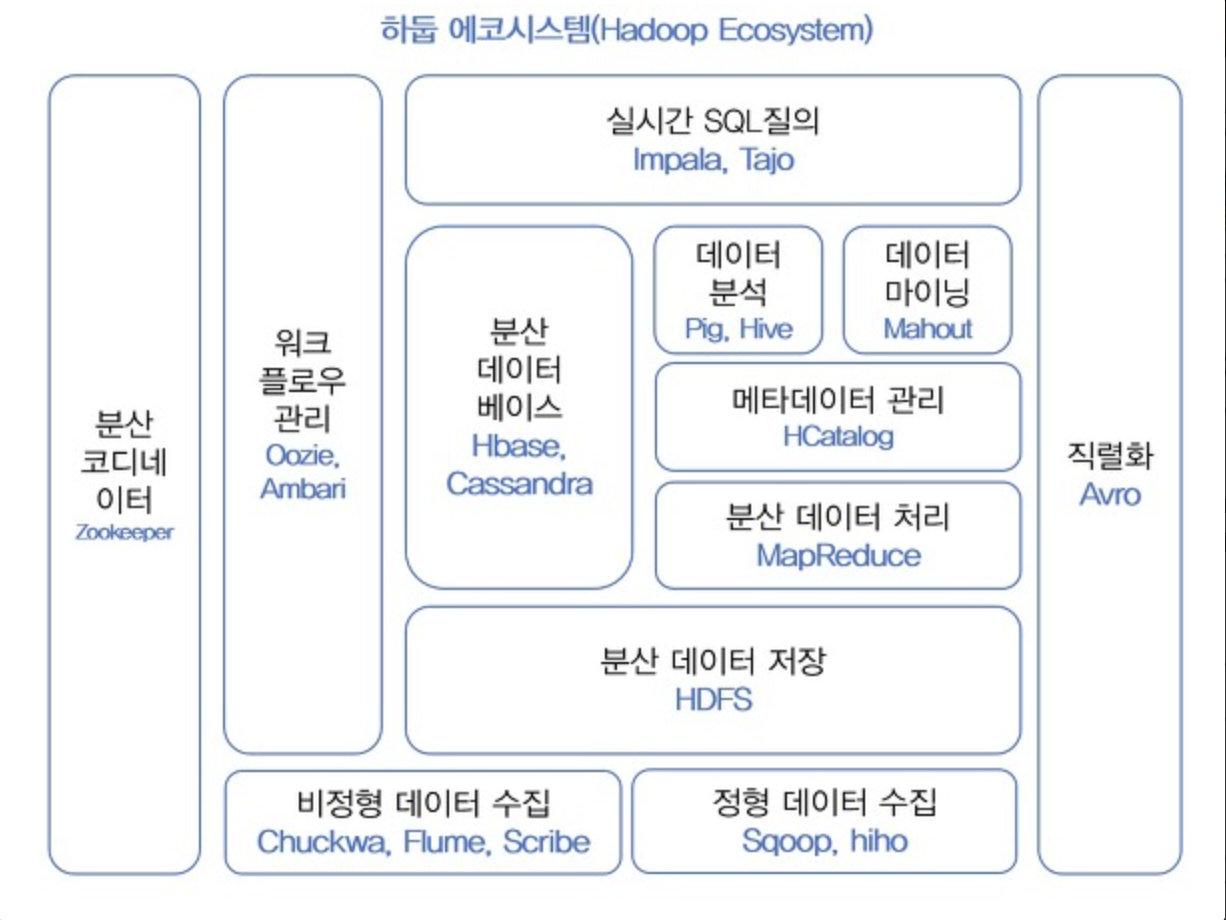
-
Sqoop : 커넥터를 사용해서 RDBMS와 하둡간의 데이터를 전송하는 기술
-
Zookeeper : 하둡 클러스터 내에서 구성 서버들 끼리 공유되는 데이터를 유지하거나 연산을 조율하기 위해서 사용되는 프로그램 (여러대의 서버간의 공유되는 데이터를 관리)
-
Spark (빅데이터 처리를 위한 오픈소스 병렬 분산 플랫폼) : 디스크에 저장되어 있는 데이터를 메모리로 읽어와서 처리하기 때문에 디스크 기반의 하둡에 비해 10-100 배 정도 빠름. 여러개의 메모리를 묶어서 하나인 것처럼 사용할 수 있음.
-
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼이다. A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있다.
-
Hive : 하둡 기반의 데이터웨어하우징용 솔루션 = 하둡에서 동작하는 웨어하우스 인프라 구조. SQL과 매우 유사한 HiveQL이라는 쿼리를 제공한다.
-
HBASE : 하둡 플랫폼을 위한 (공개형, 비 관계형) 분산 데이터베이스.
실시간 랜덤 조회 및 업데이트가 가능하며, 각 각의 프로세스들은 개인의 데이터를 비동기적으로 업데이트할 수 있다. 단, MapReduce는 일괄 처리 방식으로 수행된다. -
mahout : 머신러닝을 쉽게 구현할 수 있도록 도와주는 프로그램
-
Pig : NoSQL로 데이터를 검색하는 기술. 복잡한 MapReduce 프로그래밍을 대체할 Pig Latin이라는 자체 언어를 제공한다. MapReduce API를 매우 단순화시키고, SQL과 유사한 형태로 설계됐다.
HDFS (Hadoop Distribute File System) overview
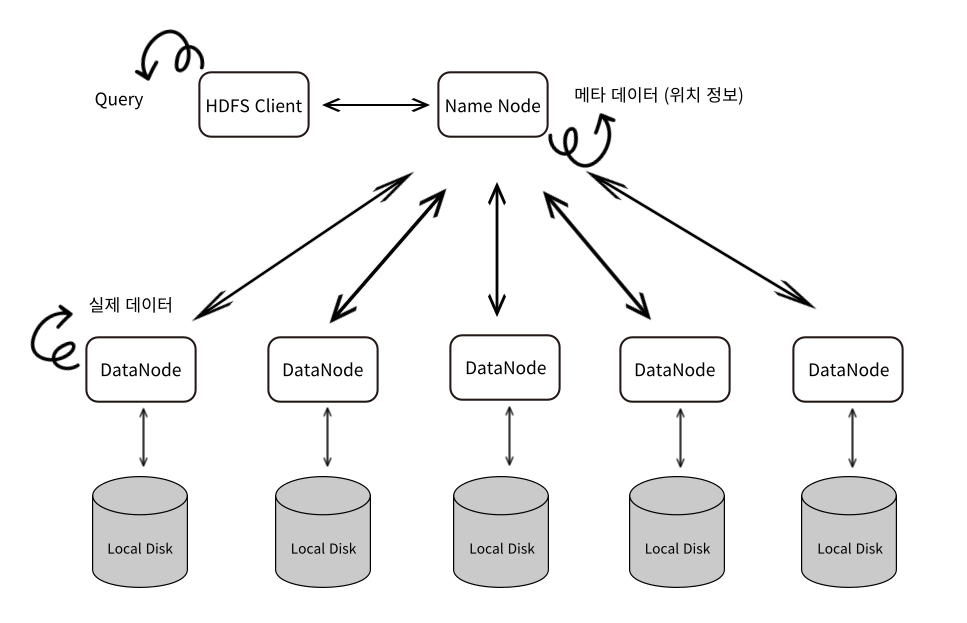
-
HDFS Client에서 쿼리를 날리면 NameNode를 통해서 위치정보를 얻어서 DataNode에서 조회를 할 수 있다.
-
Meta data(위치 정보)는 매우 중요하기 때문에 보조 NameNode를 통해 백업을 한다.
-
DataNode도 서로 다른 노드에 백업을 한다.
-
DataNode들은 서로 signal을 통해 노드의 생존을 확인한다.
하둡 설치
하둡 설치는 [M1] Mac OS에 하둡(Hadoop) 설치 게시물을 참고했습니다.
-
하둡 설치 중 keygen 생성에 관한 내용
하둡은 SSH protocol을 이용해 하둡 클러스터간의 내부 통신을 수행한다. (네임노드가 설치된 서버의 데이터 노드, 태스크 트래커등)
만약 이때 SSH 키가 복사되어 있지 않다면, 매번 데몬을 띄울 때마다 암호를 물어볼 것 이고, 암호에 답하지 않는다면 하둡이 제대로 실행되지 않는다.
이러한 문제점들을 예방하고자, 미리 SSH 키를 복사하는 것이다. -
하둡 설치 중 환경설정에 관한
hadoop-env.sh : 자바 홈디렉토리와 하둡 홈디렉토리가 어딘지 지정 core-site.xml : 하둡의 네임노드가 어느 서버인지를 지정 mapred-site.xml : java로 만들어진 mapreduce 프레임워크와 관련된 정보를 지정하는 파일 hdfs-site.xml : HDFS와 관련된 정보를 저장하는 파일
하둡 실행
실행과 종료
// 경로에서 실행
cd /opt/homebrew/Cellar/hadoop/3.3.2/libexec
sbin/start-all.sh
//로컬에서 맵리듀스 실행
sbin/start-dfs.sh
//yarn에서 맵리듀스 실행
sbin/start-yarn.sh
// 종료 명령어
sbin/stop-all.sh
sbin/stop-dfs.sh
sbin/stop-yarn.sh상태 체크
- Cluster status: http://localhost:8088
- HDFS status: http://localhost:9870 ( 3.x는 9870, 2.x는 50070 )
- Secondary NameNode status: http://localhost:9868 ( 3.x는 9868, 2.x는 50090 )
명령어 테스트
-
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
64비트 리눅스에서 32비트 하둡을 돌렸을 때 발생하는 메세지이다. 하둡의 성능이나 기능에는 문제가 없으므로 무시해도 무방하다.
put {localsrc} {dst}
Local의 파일들을 hdfs에 저장
// dept.csv 와 emp.csv 두개의 파일을 hdfs에 저장했다.
3.3.4 % hdfs dfs -put /Users/sonar0/Downloads/dept.csv /user/sonar0
3.3.4 % hdfs dfs -put /Users/sonar0/Downloads/emp.csv /user/sonar0dept.csv
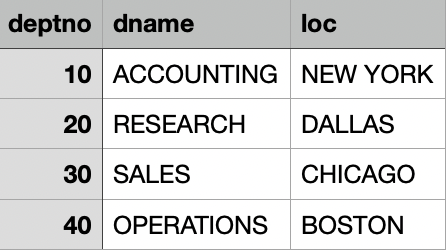
emp.csv
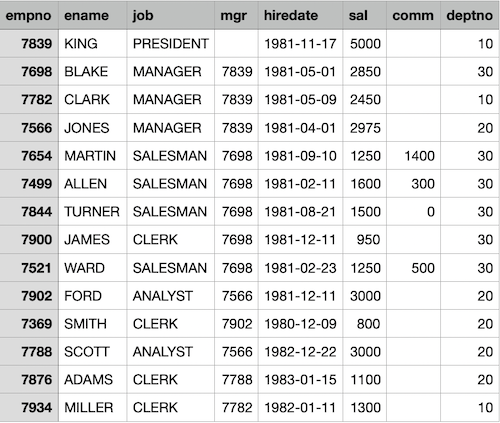
ls [-r] {args}
해당 경로에 파일과 디렉토리 정보를 조회
-r : 특정 디렉토리 이하에 대해서 정보를 보여줌// put으로 저장한 두개의 파일이 존재함을 확인
3.3.4 % hdfs dfs -ls /user/sonar0
Found 2 items
-rw-r--r-- 1 sonar0 supergroup 102 2022-12-22 17:06 /user/sonar0/dept.csv
-rw-r--r-- 1 sonar0 supergroup 679 2022-12-22 17:05 /user/sonar0/emp.csv- 브라우저에서도 확인할 수 있다.
http://localhost:9870/explorer.html#/user/sonar0
cat {uri}
해당 파일을 stdout으로 출력
- 리눅스 명령어와 동일하게 사용이 가능하다
3.3.4 % hdfs dfs -cat /user/sonar0/dept.csv
deptno,dname,loc
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTONgrep [option] [pattern]
특정 파일에서 지정한 문자열이나 정규표현식을 포함한 행을 출력해주는 명령어
[option]
-c : 일치하는 행의 수를 출력한다.
-i : 대소문자를 구별하지 않는다.
-v : 일치하지 않는 행만 출력한다.
-n : 포함된 행의 번호를 함께 출력한다.
-l : 패턴이 포함된 파일의 이름을 출력한다.
-w : 단어와 일치하는 행만 출력한다.
-x : 라인과 일치하는 행만 출력한다.
-r : 하위 디렉토리를 포함한 모든 파일에서 검색한다.
-m [num] : 최대로 표시될 수 있는 결과를 제한한다.
-E : 찾을 패턴을 정규 표현식으로 찾는다.
-F : 찾을 패턴을 문자열로 찾는다.// grep 을 이용해 emp.csv에서 'scott' 행 조회하기
3.3.4 % hdfs dfs -cat /user/sonar0/emp.csv | grep -i 'scott'
7788,SCOTT,ANALYST,7566,1982-12-22,3000,,20
// grep 을 이용해 emp.csv에서 'salesman'을 포함하는 행들의 개수 출력
3.3.4 % hdfs dfs -cat /user/sonar0/emp.csv | grep -i salesman | wc -l
4awk [option] [awk program] [args]
[option]
-F : 필드 구분 문자 지정.
-f : awk program 파일 경로 지정.
-v : awk program에서 사용될 특정 variable값 지정.
[awk program]
-f 옵션이 사용되지 않은 경우, awk가 실행할 awk program 코드 지정.
[args]
입력 파일 지정 또는 variable 값 지정.
// emp.csv 파일에서 모든 레코드의 이름(2번째 행 = $2) 과 월급 (6번쨰 행 = $6)을 조회
3.3.4 % hdfs dfs -cat emp.csv | awk -F "," '{print $2,$6}'
ename sal
KING 5000
BLAKE 2850
CLARK 2450
JONES 2975
MARTIN 1250
ALLEN 1600
TURNER 1500
JAMES 950
WARD 1250
FORD 3000
SMITH 800
SCOTT 3000
ADAMS 1100
MILLER 1300
// emp.csv에서 2행(이름)이 "SCOTT"인 레코드의 2행과(이름) 6행(월급)을 조회
3.3.4 % hdfs dfs -cat emp.csv | awk -F ',' '$2=="SCOTT" {print $2,$6}'
SCOTT 3000du [-s] {uri}
hdfs내부의 특정 file이나 directory의 size를 보여줌
-s : 각각의 파일(혹은 directory) size의 sum 값을 보여줌3.3.4 % hdfs dfs -du -h /user/sonar0/emp.csv
679 679 /user/sonar0/emp.csv
3.3.4 % hdfs dfs -du
102 102 dept.csv
679 679 emp.csvget {src} {localdst}
hdfs의 파일을 local directory로 다운로드
mkdir [-p] {paths}
directory 생성
-p : 존재하지 않는 중간 디렉토리 자동 생성rm [-r] [-skipTrash] {uri}
특정 폴더 혹은 파일을 삭제
-r : 특정 디렉토리 이하의 폴더 모두 제거
-skipTrash : 즉시 완전 삭제count [-q] {uri}
Directory, file 개수를 카운트하여 숫자로 보여준다.
-q : q : QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, FILE_NAME 을 보여준다.