로그를 수집하는 이유
로그란?
Log 란, 컴퓨터가 수행하는 도중 유의미한 내용을 남기는 기록을 말한다.
보통 파일로 남기는 기록을 말한다.
로그의 내용
로그에는 다음 내용이 들어간다.
-
로그를 남긴 시간
-
로그 레벨 (심각성의 정도)
a. TRACE : 어플리케이션에서 어떤 상황이 일어나는지 상세한 내용을 보고 싶을 때 남긴다.
라이브러리의 내부 동작을 주로 TRACE로 남기는 경우가 많다.
예) network handshake 내용. service discovery 과정.
b. DEBUG : 디버깅 용도로 남기는 로그. 어플리케이션의 개발단계에서 유의미한 정보를 주로 남긴다.
c. INFO : 단순 정보를 남기는 용도이다.
d. WARN : 시스템의 주요기능을 제공 못하는 것은 아니지만, 반복해서 발생한다면 원인을 파악하거나 해소해야하는 로그.
e. ERROR : 시스템의 주요 기능을 제공 못하게 된 경우. 발생한 경우 빠르게 원인을 파악하거나 해소해야 하는 로그.
f. FATAL : 시스템이 이용 불가능하게 된 경우.
예) Memory Crash, Disk Full- 로그 내용
- 로그가 발생한 위치
- 로그를 남긴 패키지, 클래스의 정보는 필수로 남겨야 한다.
- 로그가 WARN, ERROR라면, 해당 로그가 발생한 코드의 위치(정확한 Line)를 알 수 있다면 문제점을 파악하는 데 도움이 많이된다.
로그를 수집하는 이유
로그가 파일에 남아있다면 문제가 될 때 찾아보면 될텐데, 왜 수집이 필요할까?
-
시스템(HW)에 장애가 나면 로그파일에 다시 접근할 수 없을 수 있다.
-
사용하는 프로그램이 많아지거나, 인스턴스의 수가 많다면 일일히 들어가서 확인하기 어렵다.
-
필터링, 그룹, 검색 등을 이용해서 로그를 활용해서 더 신뢰성 있는 시스템을 만들 수 있다.
로그 수집 아키텍처
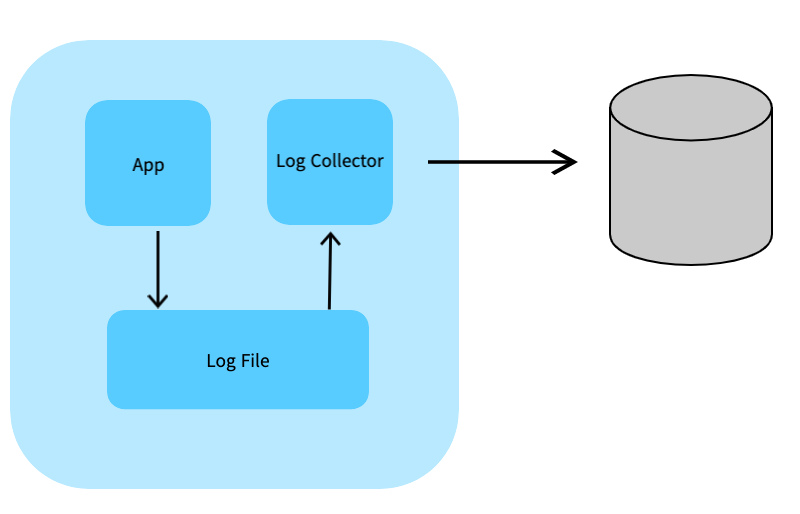
파일을 이용한 수집
애플리케이션에서는 로그를 파일로 남긴다. 로그 수집기는 파일을 모아서 저장소로 보낸다. (기록을 남기는 역할과 수집해서 전송하는 역할을 분리)
-
장점
애플리케이션 개발자는 저장소와 프로토콜 자원할당같은 부분을 고민할 필요가 없음 (관심사의 분리) → 생산성의 향상
컨테이너 환경을 이용해서 애플리케이션과 수집기의 리소스를 분리하면, 수집기 때문에 애플리케이션에 부하를 주지 않는다. -
단점
개발자 입장에서는 개발, 관리해야할 대상이 늘어난다.
에플리케이션은 정상인데, 로그 수집기의 이상으로 어플리케이션의 이상으로 판단될 수도 있다.
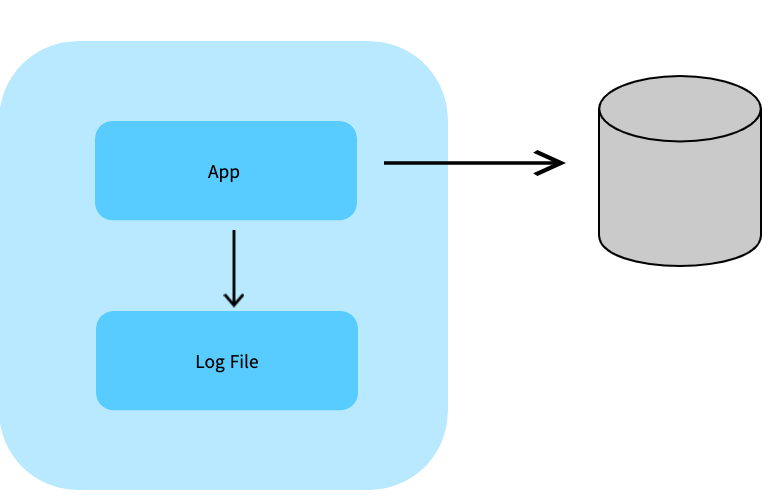
Network를 이용한 Push
애플리케이션에서 직접 로그 수집기로 TCP, HTTP 등의 프로토콜을 이용해서 전송하는 방법.
-
장점
로그 전송의 성공, 실패 여부를 애플리케이션에서 판단할 수 있다. -
단점
애플리케이션의 로직과 로그 전송을 같은 process 에서 수행하므로 서로 영향을 미칠 수 있다.
로그 전송 때문에 애플리케이션의 부하나 bottleneck 이 있을 수 있다.
문제를 디버깅하기 복잡해진다. (관심사의 분리가 안됨)
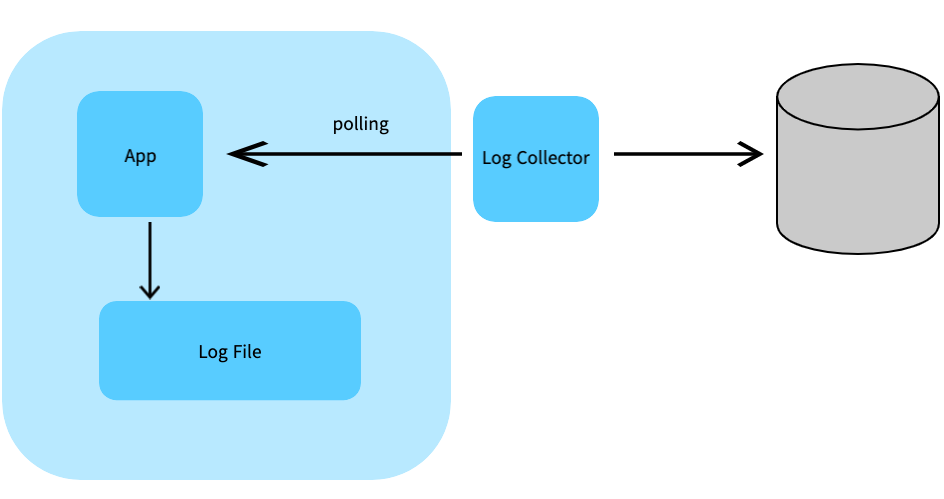
Network를 이용한 Polling
애플리케이션은 시스템의 정보, 로그 정보 등에대해서 scrap 할 수 있는 채널(network port, path)만 열어두고 수집기에서 주기적으로 Polling으로 scrap 하는 방식.
Log 보다는 Metic(통계 정보, 상태정보에 대한 snapshot) 수집에 더 적합하다.
-
장점
애플리케이션과 메트릭에 수집에 대한 관심사의 분리(SoC)가 이루어진다.
애플리케이션에서 개발자가 수집에 대한 관리를 할 필요가 없다.
분산 환경, 컨테이너 환경, 자동화된 인프라 환경에서 사용성이 편하고, 확장성이 높다. -
단점
Polling 주기나 scrap 시점에 따라 값이 바뀌므로 특정 순간의 정확한 정보를 보는데는 적합하지 않다. (건별로 Polling하기는 어려움)
Polling을 위한 추가적인 시스템 개발이나 메모리 할당이 필요함
어떤 경우에 어떤 방식이 좋을까?
-
어차피 파일로 남기는 Warning, Error log 를 수집하고 싶다. 나중에 로그 내용(text)를 찾아서 보고 싶다. →
파일을 이용한 수집 -
즉시 알람이 와야하는 중요한 이벤트(로그)를 보내야 한다. →
Network를 이용한 Push -
얼마나 요청이 많이 왔는지 통계 정보를 보고 싶다. →
Network를 이용한 Polling -
현재 메모리 사용율, 스레드의 수, 어플리케이션의 상태를 보고 싶다. →
Network를 이용한 Push
정리
나중에 특정 순간을 찾아보고싶다 = 파일을 이용한 수집
실시간 상태 = Network를 이용한 Push
통계(실시간이 필요 없음) = Network를 이용한 Polling
EFK(ElasticSearch, Fluentd, Kibana) 로그 수집 아키텍처
Elastic stack 의 유료화 때문에, ElasticSearch 대신 Opensearch를, Kibana 대신 Opendashboard를 사용한다.
Fluentd
로그의 수집, 파싱, 전송을맡는다.
Fluentd 는 어플리케이션의 파일을 읽기 위해 어플리케이션과 같은 호스트에 뜬다.
Fluentd 는 적은 리소스를 사용하면서 로그를 파싱하고 전송하는데 특화되어 있다.
규칙을 태그방식으로 정하기 때문에 사용성이 직관적이다. CRuby로 만들어져 있다.
- Fluentbit 이라는 C기반의 경량화된 버전도 있다. 이것은 forwarder 로서 사용하기에 적합하다.
Opensearch(Elasticsearch)
로그를 저장하는 저장소이다. Opensearch는 텍스트 데이터의 검색에 특화된 인덱싱 방법을 가지고 있기 때문에, 로그의 저장소 겸 검색 시스템으로 사용하기 좋다.
미리 스키마를 선언하지 않더라도 저장된 데이터 형식에 맞게 자동으로 인덱싱할 수 있는 것 또한 장점이다. 로그는 다양한 시스템에서 다양한 목적으로 남기기 때문에 로그 저장소는 데이터 타입과 형식에 대한 유연성을 제공하는 것을 선택해야한다.
Java 로 만들어졌고, JVM 위에서 돌아간다.
Open Dashboard(Kibana)
Opensearch와 연동되고, 사용하기 쉬운 시각화 도구이다. 기본으로 timeline 방식의 로그 시각화를 제공하고, SQL을 모르더라도 UI를 통해서 원하는 로그를 쉽게 찾고 추이를 볼 수 있다. 검색 결과에 대한 link를 생성해서 빠르게 공유할 수 있다. 이미 데이터가 Opensearch에 쌓여있다면, 다양한 그래프를 작성하고 통합된 Dashboard도 구성할 수 있다.
Javascript로 만들어졌고, Nodejs 서버로 동작한다.
Filebeat+Logstash vs Fluentd
구성 언어
Filebeat는 Golang
Logstash는 JRuby
Fluentd는 CRuby
Filebeat도 좋은 로그 수집기이지만, 복잡도 면에서 두 개의 시스템을 다루는 것보다는 하나의 시스템을 다루는 것이 편한 장점이 있다.
JRuby와 CRuby의 차이 때문에 Logstash 가 조금 더 많은 메모리를 사용한다.
아키텍처와 성능
가장 성능에서 큰 차이를 보이는 것은 메모리의 버퍼 큐이다.
Logstash는 메모리 상의 큐에 고정된 크기인 20개의 이벤트를 갖고 있다. 재시작 시 지속성, throughput 대비 높은 유입량에 대비하기 위해 Redis 또는 Kafka와 같은 외부 큐에 의존해야 한다.
Fluentd는 메모리상에 또는 디스크에 끝없는 배열로 구성되어있는 버퍼를 가진다. 따라서 유입량에 대한 관리를 할 수 있고, 재시작시 디스크에서 읽어서 재처리 할 수 있다. 다만 OpenStack Summit 2015에서 둘 다 대부분의 사용 사례에서 잘 수행되고 10,000 개 이상의 이벤트를 잘 처리할 수 있다. (파싱이 복잡하지 않은 경우)
문법
Logstash는 if-else 조건에 기반에 이벤트를 라우팅 한다.
output { if [loglevel] == "ERROR" and [development] == "production" { { ... } }Fluentd는 태그에 기반해 이벤트를 라우팅 한다.
<match logtype.error> type ... </match>Fluentd의 이벤트에 태그를 지정하고 각 이벤트 유형에 대해 if-else를 사용하는 것이 더 직관적이다. 만약 로그에 다른 종류의 타입이 많아진다면 Logstash는 관리하기가 어렵다. 물론 Fluentd도 많아진다면 설정이 복잡하고 성능이 떨어질 수 있다. 이 경우 rsyslog 가 하나의 대안이 된다.(초당 1million 로그의 전송이 가능하다고 한다.) rsyslog → fluentd 로 파싱결과를 보내는 아키텍처도 선택 가능하다.
서버 세팅하기
아키텍처
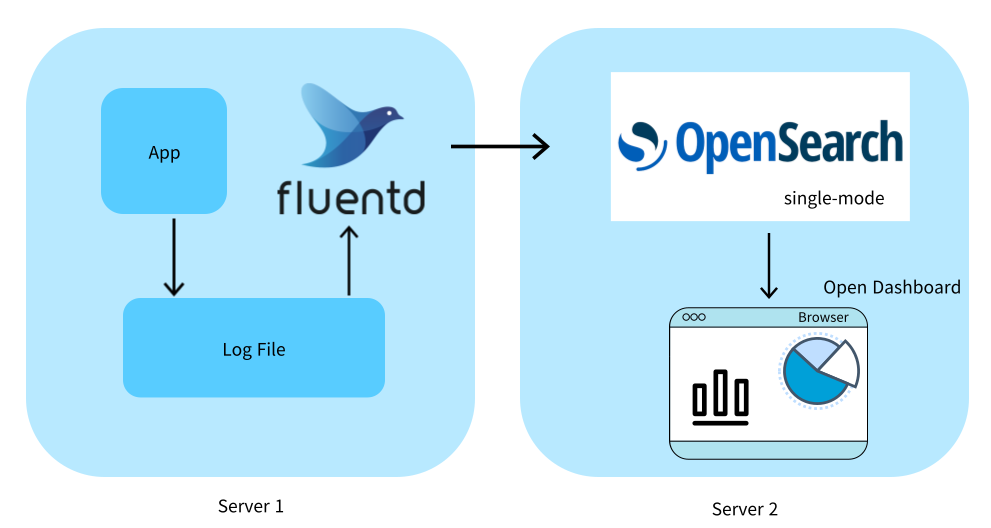
Fluentd 설치
위와 같이 세팅하기 위해 AWS EC2 서버1에 fluentd를 설치한다.
설치하기 이전에 Before Installation에 따라 시스템 설정을 변경한다.
설치 방법 (Ruby gem을 이용한 설치)
sudo apt update
sudo apt install build-essential -yRuby gem 설치
- Ruby에서 패키지 매니저 (node.js의 npm, java의 maven... )
sudo apt install ruby-rubygems -y
sudo apt install ruby-dev -yfluntd 설치
sudo gem install fluentd --no-doc에러 발생
버전 차이때문에 에러가 발생했다. 에러문의 명령어를 입력 후 다시 시도
ERROR: Error installing fluentd:
The last version of bundler (>= 0) to support your Ruby & RubyGems was 2.3.26. Try installing it with `gem install bundler -v 2.3.26` and then running the current command again bundler requires Ruby version >= 2.6.0. The current ruby version is 2.5.0.
sudo gem install bundler -v 2.3.26
// 다음에도 버전 에러문 때문에 아래 명령어도 입력해 주었음
sudo gem install yajl-ruby -v 1.4.1fluentd directory 세팅
fluentd --setup ./fluentfluentd 테스트
// fluentd 백그라운드 실행
fluentd -c ./fluent/fluent.conf -vv &
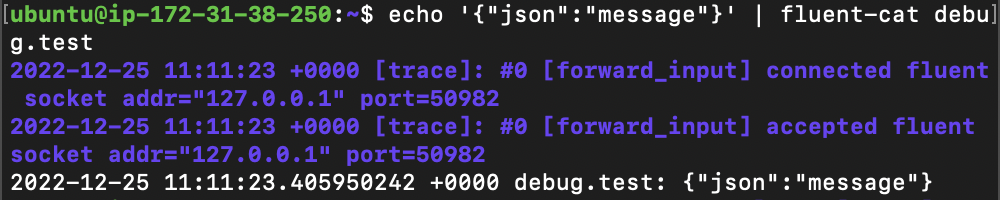
// 에코 메세지를 받는지 확인
echo '{"json":"message"}' | fluent-cat debug.testfluentd 가 메세지를 받아서 로그를 보여준다.
프로젝트용 log generator 설치
// 디렉토리 생성 및 이동
mkdir loggen && cd loggen
// 로그 생성기 다운로드
wget https://github.com/mingrammer/flog/releases/download/v0.4.3/flog_0.4.3_linux_amd64.tar.gz
// 압축 해제
tar -xvf flog_0.4.3_linux_amd64.tar.gz
// 사용법
./flog --helpLog 생성
json. 버전
json이란
JSON(JavaScript Object Notation)은 속성-값 쌍, 배열 자료형 또는 기타 모든 시리얼화 가능한 값 또는 "키-값 쌍"으로 이루어진 데이터 오브젝트를 전달하기 위해 인간이 읽을 수 있는 텍스트를 사용하는 개방형 표준 포맷이다.
// -s 옵션으로 시간간격이 다른 여러 로그를 한번에 생성할 수 있다. (1분 간격)
// -n 1000 개
./flog -f json -t log -s 1m -n 1000 -o [filename] -w &apache 버전
./flog -f apache_common -t log -s 1m -n 1000 -o $filename -w &여러 날짜가 있으면 좋기 때문에 복사 한 후 날짜를 변경해준다.
아래와 같은 방법으로 버전별 총 세개씩 만들어 주었다.
// json 버전 1 파일 복사
cp json-1.log json-2.log
vi json-2.log
// 25/Dec를 24/Dec 로 변경 / g (global 전부다 변경)
:%s/25\/Dec/24\/Dec/gOpensearch 설치하기
Opensearch는 fluentd를 설치한 서버와 다른 서버에 설치한다.
기본설치의 특징 (자세한 설치는 메뉴얼 참고)
- single mode
- 권한이 없다
- tls 사용안함
설치하기 전 확인
sudo apt update
sudo apt install build-essential -yopensearch-2.4.0-linux-x64.tar.gz 다운로드
wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-x64.tar.gz압축 해제
tar -xvf opensearch-2.4.0-linux-x64.tar.gz경로 변수로 저장
cd opensearch-2.4.0
export OPENSEARCH_HOME=$(pwd)
echo $OPENSEARCH_HOME
>> /home/ubuntu/opensearch-2.4.0주요 디렉토리
bin: 실행파일들의 위치config: 설정 파일의 위치. 부팅하기 전에 설정을 완료해야한다.data: opensearch 가 데이터를 저장하는 위치jdk: 내장 JDK. Host 에 JDK가 설치되어있지 않으면 사용한다.logs: log 디렉토리plugins: plugin 의 위치
important system settings
자세한 내용은 메뉴얼 참고
DB종류들은 system 세팅이 필요하다.
- Disable memory paging and swapping performance on the host to improve performance.
sudo swapoff -a- (선택) Increase the number of memory maps available to OpenSearch.
메모리 맵 가능한 수치를 늘리는 과정
# Edit the sysctl config file
sudo vi /etc/sysctl.conf
# Add a line to define the desired value
# or change the value if the key exists,
# and then save your changes.
vm.max_map_count=262144
# Reload the kernel parameters using sysctl
sudo sysctl -p
# Verify that the change was applied by checking the value
cat /proc/sys/vm/max_map_countOpensearch가 사용하는 기본 포트들
| Port number | OpenSearch component |
|---|---|
| 443 | OpenSearch Dashboards in AWS OpenSearch Service with encryption in transit (TLS) |
| 5601 | OpenSearch Dashboards |
| 9200 | OpenSearch REST API |
| 9250 | Cross-cluster search |
| 9300 | Node communication and transport |
| 9600 | Performance Analyzer |
설정
Open opensearch.yml
vi $OPENSEARCH_HOME/config/opensearch.yml다음 라인 추가
-
network.host: 0.0.0.0
네트워크 호스트는 자기 자신 -
discovery.type: single-node
single-node 이다. (클러스터 없음) -
plugins.security 전부 주석처리
# Bind OpenSearch to the correct network interface. Use 0.0.0.0
# to include all available interfaces or specify an IP address
# assigned to a specific interface.
network.host: 0.0.0.0
# Unless you have already configured a cluster, you should set
# discovery.type to single-node, or the bootstrap checks will
# fail when you try to start the service.
discovery.type: single-node
# If you previously disabled the security plugin in opensearch.yml,
# be sure to re-enable it. Otherwise you can skip this setting.
# plugins.security.disabled: trueJVM 힙사이즈 설정(Option)
Open jvm.options
vi $OPENSEARCH_HOME/config/jvm.optionsJVM heap 사이즈의 초기값(Xms)과 max값(Xmx)을 정한다. 특별한 요구사항이 없다면 xms와 xmx는 같은 값을 가지는 것이 모니터링 하고 관리하기 좋다.
AWS EC2 서버의 용량 여건상 128m 로 설정하였다. (자신의 EC2 서버 메모리의 절반을 권장)
-Xms128m
-Xmx128mjdk 경로를 변수로 저장 (OPENSEARCH_JAVA_HOME)
export OPENSEARCH_JAVA_HOME=$OPENSEARCH_HOME/jdkplugin 설치하기(Option)
Opensearch의 다양한 기능들은 plugin 방식으로 개발되어있다. Opensearch 기본은 데이터 저장과 인덱싱 방법을 제공하는 것이고, 그것을 활용하는 로직은 plugin 에 구현되어 있다.
참고
다음 명령어들을 활용한다. sudo 권한이 있어야 한다.
내부적으로 maven 을 이용해서 설치한다.
// 설치된 플러그인 리스트 확인
bin/opensearch-plugin list
// $plugin-name 설치
bin/opensearch-plugin install $plugin-name
// $plugin-name 제거
bin/opensearch-plugin remove $plugin-name설치 경로 : $OPENSEARCH_HOME/plugins
인증 과정에 원활함을 위해 security 플러그인을 모두 제거한다
bin/opensearch-plugin remove opensearch-security
bin/opensearch-plugin remove opensearch-security-analytics실행하기
$OPENSEARCH_HOME 에서 아래 명령어로 실행
./bin/opensearch다른 서버에서 아래 명령어로 확인할 수 있다. ($IP 변경)
curl -X GET http://$IP:9200결과
MacBookPro ~ % curl -X GET http://13.209.3.228:9200
{
"name" : "ip-172-31-38-250",
"cluster_name" : "opensearch",
"cluster_uuid" : "vMCHB8XPQ5yDafhs7QzGeA",
"version" : {
"distribution" : "opensearch",
"number" : "2.4.0",
"build_type" : "tar",
"build_hash" : "744ca260b892d119be8164f48d92b8810bd7801c",
"build_date" : "2022-11-15T04:42:29.671309257Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}systemctl 로 system service 로 등록하기
백그라운드에서 계속 실행할 수 있도록 systemctl로 관리한다.
systemd란
리눅스는 OS이기 때문에 전원을 ON 시킬 경우, 부팅이 되는 과정에서 시스템을 초기화와 환경 설정을 누군가 해줘야된다.
systemd 는 Linux 계열에서 사용하는 시작시스템이자 시스템 매니저 표준이다. daemon 들을 관리를 통일하고 쉽게 만드는 역할을 한다.
systemd 는 PID =1 로서 가장 먼저 시작되는 프로세스이고, 리눅스의 시스템의 나머지 프로세스들을 시작시킨다.
systemctl이란
systemctl 은 init system(systemd)을 관리하는 도구이다.
systemd 서비스를 어떻게 관리할지를 정의하고,상태확인, 상태 변경, 설정파일 관리 기능 등을 제공한다.
대표 명령어
systemctl start/stop $service: 서비스를 시작, 정지 한다. (service 명령어로 대체가능)systemctl status $service: 서비스의 상태를 볼 수 있다. (service 명령어로 대체가능)systemctl daemon-reload: systemd 설정을 적용, 리로드한다.systemctl list-units: systemd unit 들을 모두 표기한다.systemctl list-unit-files: systemd unit이 정의된 파일들의 위치를 알려준다.
설정파일 만들기
sudo vi /etc/systemd/system/opensearch.service내용 붙혀넣기
- $OPENSEARCH_HOME_PATH : 오픈서치 디렉토리 경로 (/home/ubuntu/opensearch-2.4.0)
- $USER : 오픈서치 디렉토리의 소유자 권한이 있는 유저 (ubuntu)
[Unit]
Description=OpenSearch
Wants=network-online.target
After=network-online.target
[Service]
Type=forking
RuntimeDirectory=data
WorkingDirectory=$OPENSEARCH_HOME_PATH
ExecStart=$OPENSEARCH_HOME_PATH/bin/opensearch -d
User=$USER
Group=$USER
StandardOutput=journal
StandardError=inherit
LimitNOFILE=65535
LimitNPROC=4096
LimitAS=infinity
LimitFSIZE=infinity
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SendSIGKILL=no
SuccessExitStatus=143
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target등록
sudo systemctl daemon-reloadsudo systemctl enable opensearch.servicesystemctl로 opensearch 시작
sudo systemctl start opensearch.serviceps -ef | grep opensearch로그 확인
tail -f $OPENSEARCH_HOME/logs/opensearch.logOpen Dashboard 설치하기
다운로드 및 압축 해제
wget https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/2.4.0/opensearch-dashboards-2.4.0-linux-x64.tar.gz
tar -zxf opensearch-dashboards-2.4.0-linux-x64.tar.gz경로를 환경 변수로 저장 ($OPENSEARCH_DASHBOARDS_HOME)
cd opensearch-dashboards-2.4.0
export OPENSEARCH_DASHBOARDS_HOME=$(pwd)설정 변경
설정 파일 열기
vi config/opensearch_dashboards.yml옵션 수정
- server.host: ec2 서버의 퍼블릭 DNS 주소 (브라우저에 입력할 주소 이름을 입력해야 CORS이슈가 발생하지 않는다.)
- server.port: 5601 (default)
- opensearch.hosts 연결. https가 아닌 http 를 사용.
- 아래 다섯줄 주석처리 : 사용하지 않음 (편의를 위해 security 관련 옵션을 사용하지 않는다.)
server.host: $ec2_public_dnsname
server.port: 5601
opensearch.hosts: [http://localhost:9200]
opensearch.ssl.verificationMode: none
opensearch.username: kibanaserver
opensearch.password: kibanaserver
# opensearch.requestHeadersWhitelist: [authorization, securitytenant]
# opensearch_security.multitenancy.enabled: false
# opensearch_security.multitenancy.tenants.preferred: [Private, Global]
# opensearch_security.readonly_mode.roles: [kibana_read_only]
# Use this setting if you are running opensearch-dashboards without https
# opensearch_security.cookie.secure: falsesecurity 플러그인 삭제
./bin/opensearch-dashboards-plugin remove securityAnalyticsDashboards
./bin/opensearch-dashboards-plugin remove securitytDashboards실행
./bin/opensearch-dashboards다음과 같은 화면이 나온다면 성공
{입력한 EC2서버의 DNS:포트번호} 로 접속하면 Open Dashboard를 확인할 수 있다.
첫화면에서 security 문제로 로딩이 계속 된다면, {입력한 EC2서버의 DNS:포트번호}/app/home 경로로 접속한다.
