Spark란?
Spark는 빅데이터 처리를 위한 오픈소스 병렬 분산 플랫폼이다. 디스크에 저장되어 있는 데이터를 메모리로 읽어와서 처리하기 때문에 디스크 기반의 하둡에 비해 10-100 배 정도 빠르다. 여러개의 메모리를 묶어서 하나인 것처럼 사용할 수 있다.
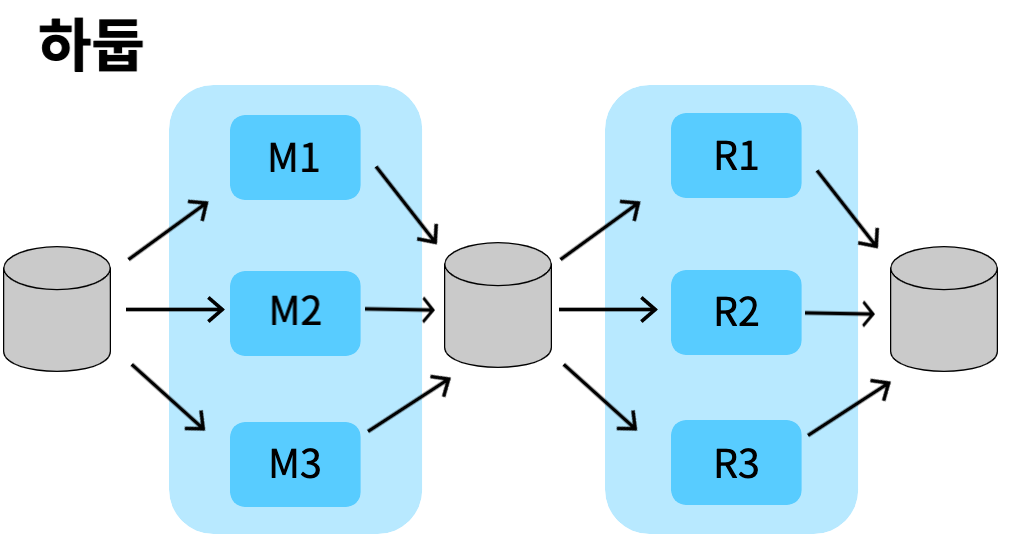
하둡은 디스크에서 데이터를 읽어와서 Mapping해서 디스크에 저장한다. 다시 읽어온 데이터를 Reduce해서 디스크에 저장한다.
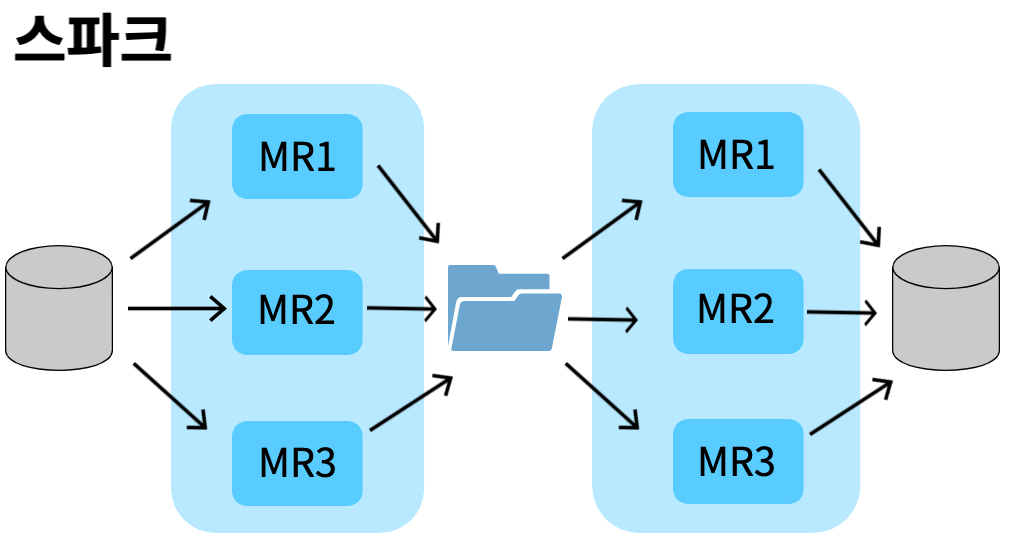
스파크는 Mapping/Reduce해서 메모리에 저장한다. 메모리에서 읽어온 데이터를 Mapping/Reduce해서 최종적으로 디스크에 저장한다. → 처리속도가 빠르다.
Spark 설치

초보 개발자