인터넷과 웹
인터넷은 하드웨어, 웹은 소프트웨어
인터넷이 infra structure 라면 웹은 그 인프라 위에서 제공되는 서비스 이다.
Server-Client
Server - Client 의 의미
-
둘다 서로간의 역할(Role)로서의 정의이다.
-
Client: 요청을 하는 쪽
-
Server: 요청에 응답하는 쪽
Server - Client 의 특징
-
Server 가 있어야, Client 가 요청을 할 수 있다.
-
Server/Client는 서로간의 역할(Role)이다. 즉, 둘 다 존재해야 한다 .하나만 존재할 수
없다. -
Server/Client가 정보를 주고 받기 위해서는 약속(protocol)이 필요하다.
컴퓨터는 한 비트씩 읽으므로, 처음 데이터부터 몇 번째 데이터까지 무슨 의미인지를 미리 알아야 계속해서 들어오는 연속적인(stream) 데이터에서 몇 번째 까지 어떻게 읽을지 해석할 수 있다.
Server - Client 용어
Server/Client는 특정 기술을 의미하지 않는다.
예) 백엔드 서버를 만들었을 때, 그 서버는 Client 입장에서는 API의 서버이지만, 조회하는 데이터베이스와의 관계에서는 Client가 된다.
서버개발자, 클라이언트 개발자란?
통상적으로 JD에서 말하는 서버개발자, 클라이언트 개발자는 기술적으로 정확한 용어
라기 보다는 사용하다보니 굳어진 용어이다. 서버 개발자가 개발하는 서버에서는 HTTP client, DB client 등 많은 클라이언트를 개발하게 된다. 여기서 말하는
서버/Client 는 사용자(고객) 입장에서 눈에 보이지 않는 영역을 서버, 눈에 보이는 영역 (웹페이지, 모바일 앱)을 개발하는 쪽을 클라이언트라고 생각하면 된다. 둘 사이의 관계는 client-server 관계가 맞다.
API
API의 정의
소프트웨어/시스템이 다양한 방식(프로그래밍 가능한)으로 상호작용(데이터를 주고,받고,해석) 하기 위해서 만든 인터페이스(접점)이다. 동시에, 상호작용을 위해서 지켜야 하는 규칙을 말한다.
더 정확하게, 실천적으로는 클라이언트가 요청하고 서버가 응답하는데 필요한, 요청과 응답의 형식에 대한 약속이다.
API의 구현
API는 제공자가 규칙을 정하고, 클라이언트는 규칙을 따른다. API는 주고 받고자하는 데이터(리소스)가 있다. 어떤 데이터를 줄지는 API 제공자가 정한다. 클라이언트는 무엇을 원하는지 요청을 한다.
리소스의 제공자가 규칙을 정하기 때문에 보통 서버 개발자가 정의하지만, API를 사용하고자 하는 쪽의 편의도 중요하기 때문에 클라이언트의 사용성, 의견 등이 반영되어야 한다. API는 기본적으로 컴퓨터 사이의 의사소통을 수월하게 하기 위해서 만들어진 것이지만 API 제공자와 사용자 사이의 의사소통이기도 하기 때문에 만드는 쪽도, 사용하는 쪽도 모두기술과 사람을 이해해야 좋은 API를 만들 수 있고, API를 잘 사용할 수 있다.
API의 활용 예시
-
모바일 앱에서 고객이 쇼핑을 하기 위해서는 상품 리스트를 받아와야 한다. 상품리스트를 조건에 따라서 10개씩 가져오는 API가 필요하다.
-
사내에서 주기적으로 협업을 하는데 매번 엑셀파일로 데이터를 주고 받으니까 일이 지연되고 파일관리의 어려움이 있다. 그때 그때 데이터를 볼 수 있으면 좋겠다. 그때 API 로 만들고 필요할 때마다 조회해서 쓸 수 있다.
-
고객사가 우리 광고시스템에 등록할 광고 이미지를 매번 이미지로 전달했다. 고객사가 1000개가 넘으니까 메일함 관리도 어렵고 실수도 잦아진다. 이 때 API를 이용해서 광고 등록 요청할 수 있다.
대표적인 API 의 종류(REST, SOAP, GraphQL)
REST(Representational State Transfer)
-
자원을 이름으로 구분하고, 자원의 상태를 주고받는 방법의 API
-
HTTP프로토콜을 기반으로 웹의 자원을 다양하게 활용할 수 있다.
-
기본규칙
1. HTTP URI(Uniform Resource Identifier)로 대상이되는 자원(Resource)을 명시한다. 2. HTTP Method(POST, GET, PUT, DELETE, PATCH 등)로 동작을 명시한다. 3. Header와 Body로 구성되어있다. a. Header에는 key-value로 정적인 정보를 전달한다. 주로 body를 처리하기 전에 필요한 약속, 보안과 관련 정보 등이다. b. Body에는 header에서 정의한 방식에 따라서 자유롭게 데이터를 담을 수 있다. -
자유도가 높다.
1. 다양한 데이터 포맷을 사용할 수 있다. 2. 캐시 등 편의나 성능을 위한 기능을 사용할 수 있다. -
자유도가 높다보니, RESTful 한 것이 무엇이냐? 라는 논의가 있다.
(각자 정의한 REST API가 다르므로 기준으로 삼을만한 REST API가 없었다.)
SOAP(Simple Object Access Protocol)
-
SOAP는 그 자체로 프로토콜이다.
-
메시지 전송 포맷, 기능, 보안 등을 표준으로 정했다. 표준이 많다.
-
프로토콜상 실행 로직(성공/실패/반복)이 정의되어 있기 때문에, 처음부터 끝까지 신뢰성을 제공합니다.
-
자유도가 낮다.
-
메세지가 크다.
-
SOAP가 필요한 상황이 아니면 REST 를 이용해서 만드는게 일반적이다.
GraphQL
-
비즈니스 도메인을 그래프 자료구조로 모델링하고 한 번의 요청으로 원하는 정보를 선택적으로 요청하고 전달할 수 있는 API이다.
-
한 개의 Endpoint로 모든 자료와 구조를 표현할 수 있다. 용도나 자원별로 API나 View 등을 만들 필요가 없다.
-
한 번의 요청으로 원하는 모든 데이터를 서버로부터 요청하여 가져올 수 있다.
기존에 REST API 사용할 때 자주 발생하는 Overfetching(원하는 정보 이상을 가져온다.)
Underfetching(원하는 데이터를 위해 여러 요청을 보내는 것) 문제가 발생하지 않는다. -
기존 REST의 API나 리소스 단위로 캐시하던 방법의 적용이 어렵다.
-
필터링, 보안등 다양한 제약사항을 서버에서 구현하기가 어렵다.
-
모든 정보가 그래프 형태로 열려있고 내가 무엇을 할지를 그래프 계층 구조에 맞게 요청하면 서버는 요청에만 응답한다.
-
REST API는 형식이 정해져 있고 데이터를 전부 준다.
OpenAPI
-
누구나 활용할 수 있도록 공개된 API를 말한다. 외부 소프트웨어 개발자가 빠르게 시스템을 통합할 수 있도록 하기위해서 만든다.
-
API의 명세가 공개되어있다.
공개는 되어있지만, 일부 사용의 제약이 있을 수 있다. 요청수, 기간당 요청수 등 사용하는 사람이 많으므로, 설계와 신뢰성이 중요하다.
사례
-
공공데이터포털
-
네이버지도API
-
유튜브API
웹사이트 접속
OSI 7계층
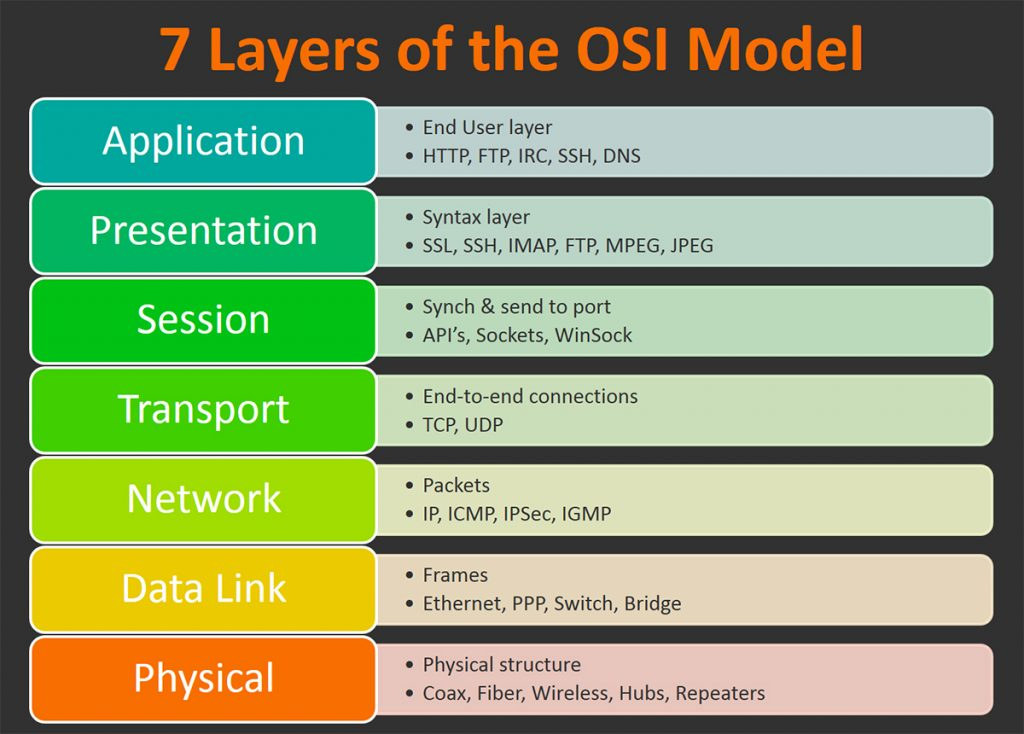
-
Physical : 물리적인 연결, 유선, 무선 포함 (소프트웨어적인 처리 x)
-
Data Link : 하드웨어 + 소프트웨어 영역, 같은 이더넷 안에 연결되어 있는가
-
Network : IP 주소가 위치하는 레이어, IP 주소 정보를 담는 Packet이 존재
-
Transport : 주소에서 데이터를 어떤 식으로 주고 받을지에 대한 정보, 컴퓨터와 컴퓨터가 연결을 맺는 것에 대한 정보
1. TCP : 연결형, 속도 느림, 신뢰성 높음 ( 연결 = 3-way handshaking 과 해제 = 4-way handshaking) 2. UDP : 비연결형, 속도 빠름, 신뢰성 낮음 -
Session : API, Sockets, 포트에다 데이터를 보내거나 싱크
-
Presentation : 문법과 관련된 계층, SSL, SSH ... (네트워크 레이어 수준에서 문법을 정의)
-
Application : 애플리케이션, 코딩 수준에서 해석하는 영역, HTTP, FTP, IRC, DNS ...
과정
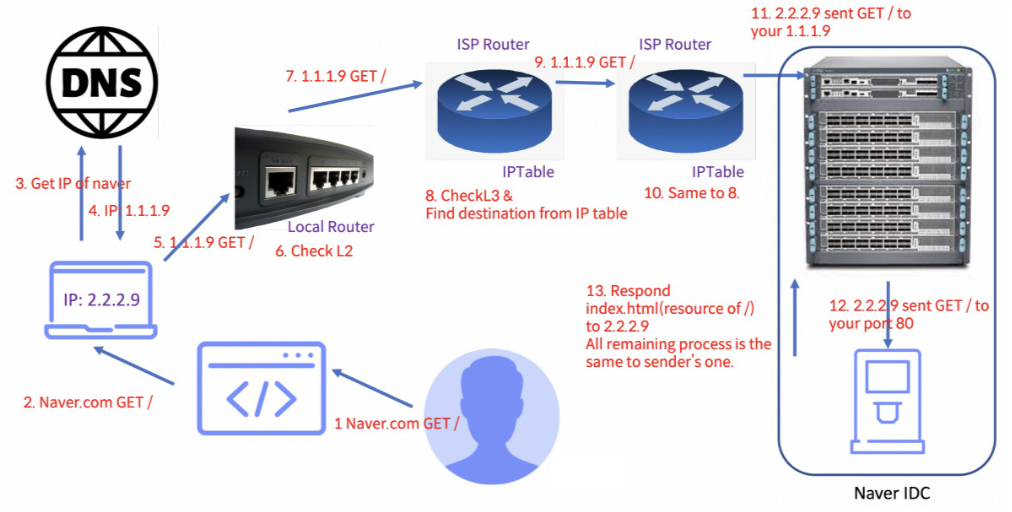
-
브라우저(애플리케이션)에 주소를 입력
-
브라우저는 컴퓨터에 주소를 전달
-
입력한 주소(도메인)를 운영체제가 알고 있는 DNS(Domain Name Service)에 조회한다.
-
주소에 맞는 IP 주소를 얻어온다.
네트워크 통신할 메세지를 만든다. Application 또는 Presentation layer 에 맞는 프로토콜을 선택한다. 7 에서 1 layer로 가면서 데이터를 하나씩 붙인다.
- 응용프로그램 계층(Application, Presentation, Session)에서 프로토콜에 해당하는 패킷을 붙인다.
- Transport Layer 에서 TCP segment를 붙인다.
- Internet 계층에서는 IP datagram을 붙인다.
- Network layer 에서 자신의 IP source-ip 영역에, DNS로 조회했던 대상 서버의 주소를 target-ip 영역에 기록한다.
- Data link 계층에서 Frame을 붙인다.
- Physical 계층에서 Frame을 붙인다.
5 - 7. sender의 host 또는 로컬 라우터에서 Pysical Layer, DataLink 계층의 Frame을 보고서 대상이 같은 영역에 있는 대상인지 확인하고 그렇지 않으면 인접한 ISP 라우터에 메시지를 보낸다.
8 - 11. ISP 라우터에서는 Physical, DataLink, Network 까지 데이터를 확인해서 target IP 주소까지 얻는다. 라우터 자신이 가진 IP table을 확인하고 target IP를 찾을 것으로 기대하는 적절한 GW 또는 로컬 라우터로 메시지를 넘긴다.
- target IP를 가지고 있는 로컬 라우터에서 IP에 해당하는 서버 컴퓨터를 찾아서 메시지를 전송한다.
해당 컴퓨터의 운영체제에서는 Layer1,2의 프레임부터 차례대로 해석하면서 자신의 포트에 해당하는 프로세스에게 메시지를 전송하고, 프로세스는 application layer 정보를 보고서 메세지를 해석한다.
- 해석한 뒤 응답을 보내줘야한다면, 같은 과정으로 서버가 클라이언트에게 메세지를 보낸다.
웹 서비스에서 발생하는 데이터의 종류와 특징
서버 엔지니어와 데이터 엔지니어의 구분
데이터 엔지니어링의 특수성이 어디서 나오는지 구분하기 위해서 데이터의 성격을 구분한 것이다. 꼭 서버 엔지니어는 이런 데이터만 다루고, 데이터 엔지니어는 어떤 데이터만 다룬다는 의미는 아니다. 비즈니스나 데이터가 커지다보면, 데이터의 성격에 따라 기술 스택도 다른 것이 필요하게 된다. 그 과정에서 역할이 나뉘다 보면 자연스럽게 이런 식으로 서버 엔지니어와 데이터 엔지니어의 역할이 나뉘게 된다.
서버 엔지니어
Transaction (거래 데이터)
거래 요청이 있고 요청에 대한 처리의 결과가 있는 데이터. 비즈니스나 시스템에서 빈번하게
생성되고 업데이트 되는 데이터를 의미한다.
전자 상거래 시스템을 생각한다면, 다음과 같은 데이터가 Transaction Data이다.
1. 상품 주문
2. 결제
3. 환불 요청
4. 기술적으로 시스템의 여러 동작/기능이 하나로 연결되어야 하고, 완결될 때 모두 같이 상태가 결정되는 경우.(all or nothing)Metadata (메타 데이터)
비즈니스나 도메인을 구성하는 추상화된 정보. 시스템을 다루는 이해관계자(stakeholders)나 제품에 대한 상태 정보 등이 여기에 속한다. 메타데이터는 업데이트가 될 수 있다. 하지만 자주 업데이트 되지는 않는다.
전자 상거래 시스템을 생각한다면, 다음과 같은 데이터가 Metadata이다.
1. 회원의 기본 정보
2. 판매자의 기본 정보
3. 판매자가 등록한 상품 정보
4. 광고주가 설정한 광고 요청 설정
5. 시스템의 설정 정보데이터 엔지니어
데이터 엔지니어가 다루는 데이터는 다음과 같은 특징이 있다.
1. 하나의 메시지가 그 자체로 완결성을 가진다.
2. 하나의 메시지는 Immutable 하다.
a. 메시지 발생 이후에 메시지 안의 값을 변경하지 않는다.
b. 요구사항에 따라 파이프라인에서 특정 데이터를 추가/삭제 정도만 한다.
3. 메시지 안에 메시지의 고유 값(다른 메시지들과 비교해서 unique함을 판단할 수 있는)을 구분할 수 있다.
4. 시간 정보가 항상 있다.Event
하나의 독립된 사건을 알리는 데이터. 데이터의 발생만 있고, 응답은 필요 없는 데이터. 발생한 데이터를 추후 활용해야 비즈니스/도메인의 의미가 부여된다.
언제나 발생 시간(timestamp) 정보를 가지고 있다.
다음과 같을 때 Event 데이터를 남긴다.
1. 거래 데이터가 아니지만, 비즈니스에 필요한 데이터인 경우
2. 하나의 사건 이후에 여러 거래들이 후처리 되어야 하는 경우
3. Transaction으로 처리할 수도 있지만 꼭 하나로 연결될 필요가 없어서 독립된 여러 이벤트로 정의/발생 시킨 뒤, 추후에 분석단계에서 엮어서 활용하고 싶은 경우.Log
어떤 시스템이나 거래의 중간에 순간의 주요 정보를 기록한 데이터.
Event와 의미가 거의 같거나 비슷하다. (구분하는 것의 의미 없을 수도 있다.)
프로그래머의 관행상 파일로 남기는 event data를 로그라고 한다.
Event 와 Log의 처리에서는 다음과 같은 기술적 주제를 다룬다.
1. 하나의 사건 이후에 여러 거래들이 후처리 되어야 하는 경우
a. Message Queue를 이용한 Pub-Sub model
2. 실시간 Event 전송
a. Streaming, CDC
3. Event, Log 의 Visualization
a. ES(OS) - Kibana
4. Event, Log 의 Data Cleansing
a. Streaming, BatchAggregation
Raw-Data(원본/원천 데이터)로부터 비즈니스에 필요한 데이터를 얻기 위해서 집계, 통계를 이용해서 데이터를 만든다. 주로 합계, 평균, 추이를 나타내는 데이터를 만든다. 시간 또는 범위가 있는 시간 정보가 항상 있다.
Aggregation은 데이터 분석을 맡은 사람이 ad-hoc 하게 하기도 한다. 다음의 경우에는 데이터 엔지니어링 기술이 좀 더 본격적으로 필요하다.
1. 비즈니스를 위해서 지속적으로 집계 데이터가 필요한 경우.
a. Batch(ETL), Streaming 시스템
b. 안정성과 신뢰성을 갖춘 시스템
2. 집계 대상이되는 데이터 사이즈가 큰 경우
a. DB, OLAP 시스템
b. Backup, Merge, Partitioning, Sharding
3. 집계 대상이 되는 데이터(데이터소스 또는 테이블)가 많은 경우
a. Denormalize, Star-Schema
b. OLAP Cube
4. 도메인의 특수성이 있는 경우Aggregation을 잘하기 위해서는 idempotent(멱등성)을 보장하는 시스템을 만들어야 한다.
Idempotent 하다는 것(멱등성이 있다)은 같은 대상(Raw-Data)에 대해서 재처리를 하면 언제나 똑같은 결과가 보장되어야 한다는 의미이다.
