개인 공부를 위한 글이기에 설명이 장황할 수 있습니다. 코드만 필요하신 분은 맨 아래에 전체 코드를 올려놓았으니 긁어가시면 됩니다.
피드백은 언제나 환영입니다.
크롤링은 웹 사이트에서 제한하는 경우가 있습니다. 그래서 웹 사이트마다 제공하고 있는 robots.txt를 확인하거나, 이용약관 등을 꼭 확인한 후 크롤링을 수행해야 합니다.
0.1 실습 목표
파이썬의 selenium 모듈을 사용하여 스타벅스의 매장 정보를 가져와 엑셀에 저장하는 것입니다.
0.2 목차
- 모듈 설치
- 크롬 드라이버 다운로드
- 크롤링
- 정보 가져오기
- 엑셀에 정보 저장
1. 모듈 설치
1.1 pip upgrade
우선 selenium을 포함한 관련 python 모듈들을 다운로드 받기 위해 pip를 업그레이드 해줍니다.

1.2 모듈 설치
---------크롤링---------
!pip install selenium==3.0 //브라우저 제어
!pip install bs4 //HTML, XML 파싱
------데이터 분석------
!pip install pandas //데이터 분석
-------Excel 관련-------
!pip install xlrd //xls 파일 읽기
!pip install xlwt //xls 파일 쓰기
!pip install xlsxwriter //Excel 생성, 형식화
!pip install openpyxl //xlsx 읽고, 쓰기1.3 모듈 버전 정보
selenium : 3.0.0
bs4 : 0.0.2
pandas : 2.2.2
xlrd : 2.0.1
xlwt : 1.3.0
xlsxwriter : 3.2.0
openpyxl : 3.1.52. 크롬 드라이버 다운로드
2.1 크롬 버전 정보 확인
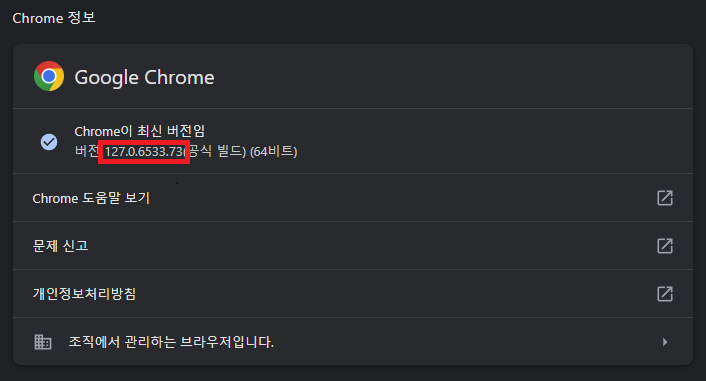
크롬에서 오른쪽 위 점 세개 아이콘을 클릭 > 도움말 Chrome 정보에 들어가서 Chrome 버전 정보를 확인합니다.
2.2 크롬 드라이버 다운로드
이후 아래 링크를 클릭해 자신의 버전과, 시스템에 맞는 드라이버를 다운로드 합니다.
다운로드한 압축 파일을 열어보면 chromedriver.exe 파일이 있습니다. 이 파일을 python을 작업할, 또는 실행할 폴더로 이동시킵니다.(혹은 python 코드에서 절대 경로로 지정해주어도 됩니다.)
3. 크롤링
3.1 모듈 Import
우선 사용하고자 하는 모듈을 import 해줍니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import time
import warnings
import pandas as pd
from PIL import Image3.2 드라이버 입력
// 모든 경고 메시지 무시
warnings.filterwarnings(action='ignore')
// 웹 드라이버 지정
driver = webdriver.Chrome(chromedriver.exe)🎯 Trouble shooting
만약 Chrome() 메서드의 인자가 올바르지 않다는 에러가 발생할 경우 다음과 같이 작성하면 됩니다.
service = Service('chromedriver.exe')
driver = webdriver.Chrome(service=service)
3.3 제어할 웹 사이트 지정
url = 'https://www.starbucks.co.kr/index.do'
driver.maximize_window()
driver.get(url)url 변수에 크롤링하고자 하는 웹사이트의 주소를 담습니다.
저는 스타벅스 코리아의 홈페이지 주소를 입력했습니다.
3.5 STORE 드롭다운 메뉴
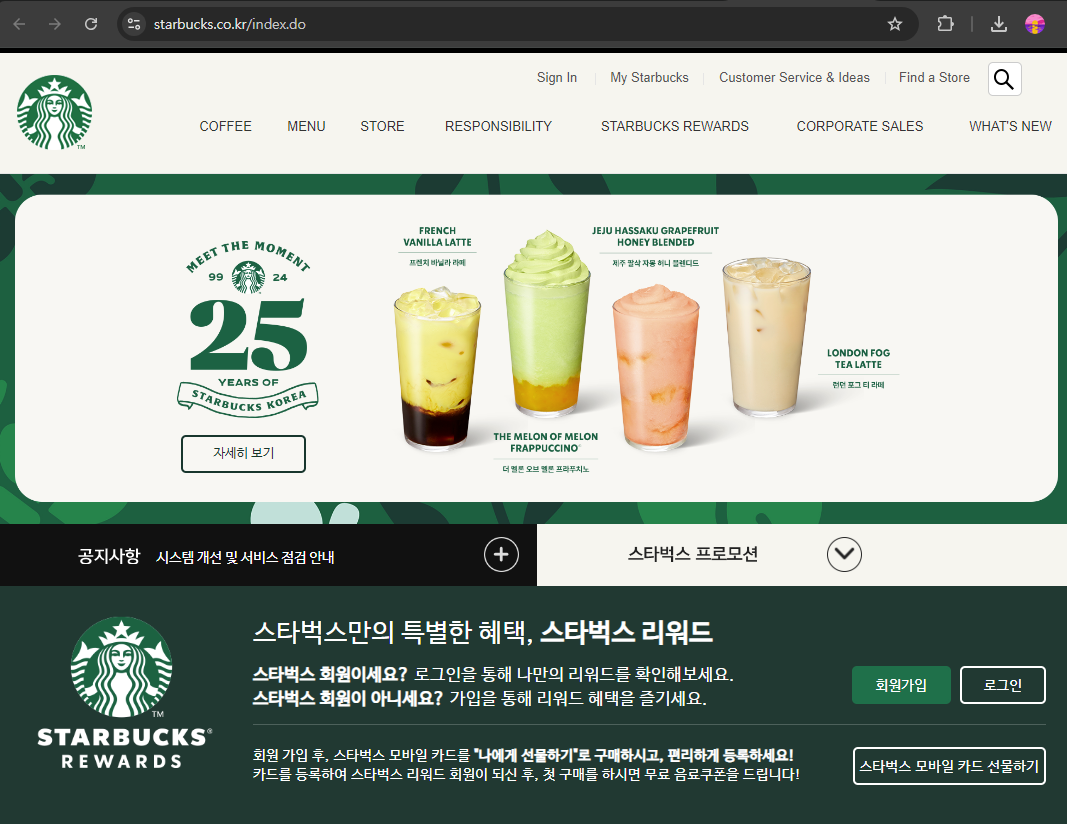
첫 번째로 매장 정보를 확인하기 위해서는 홈페이지 상단의 네비게이션에서 STORE > 지역 검색을 클릭해야 합니다.
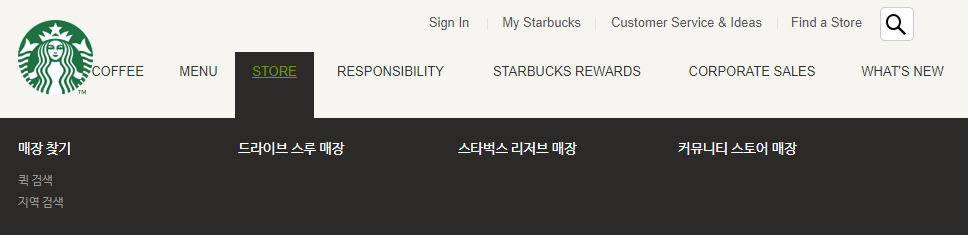
마우스로 STORE에 갖다대면 드롭다운 메뉴가 나타나고 거기에 지역 검색 요소가 존재합니다.
요소들의 정보를 확인하기 위해 크롬의 검사 도구를 사용합니다. F12를 누르면 검사 도구가 나타나는데 왼쪽 위 화살표 이미지를 누르고
웹 사이트 요소를 클릭하면 아래와 같이 검사 도구에서 해당 요소의 HTML 코드를 확인할 수 있습니다.
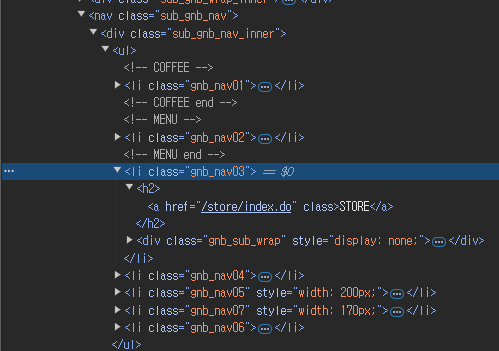
여기서 STORE가 적힌 박스를 의미하는 태그는 <li class="gnb_nav03"> 입니다.
해당 태그의 클래스를 요소 지정 메서드에 입력합니다.
//요소 조작을 위한 메서드
action = ActionChains(driver)
//클래스로 요소 지정
parent_level_menu = driver.find_element(By.CLASS_NAME, "gnb_nav03")
//요소로 마우스 이동 하기.
action.move_to_element(parent_level_menu).perform()
time.sleep(0.5)ActionChains() 객체는 일련의 작업들을 큐에 저장한 후 perform()이 호출되었을 때 저장된 모든 작업을 차례로 수행합니다. 만약 ActionChains() 객체로 작업들을 생성했다면 작업을 수행하기 위해 마지막에 perform() 메서드를 꼭 작성해주어야 합니다.
그리고 time.sleep()을 사용하는 이유는 요소에 마우스를 갖다 대었을 때 드롭다운 메뉴가 펼쳐지는 데에 시간이 어느정도 소요되기 때문입니다.
time.sleep()을 사용하지 않으면 메뉴가 열리기도 전에 다음 구문을 실행해 에러가 발생합니다.
3.6 지역 검색 클릭
다음으로는 지역 검색을 클릭하는 코드를 작성하겠습니다.
아까 확인한 HTML 코드에서 하위 태그를 확인해 보면 지역 검색이 적힌 태그를 확인할 수 있습니다.
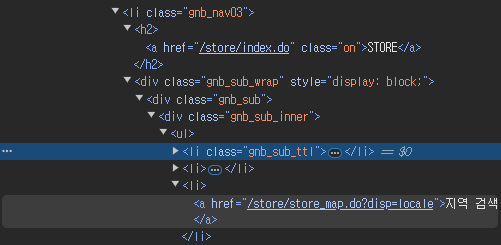
해당 태그를 우클릭 copy > copy XPath를 클릭해 XPath를 복사합니다.
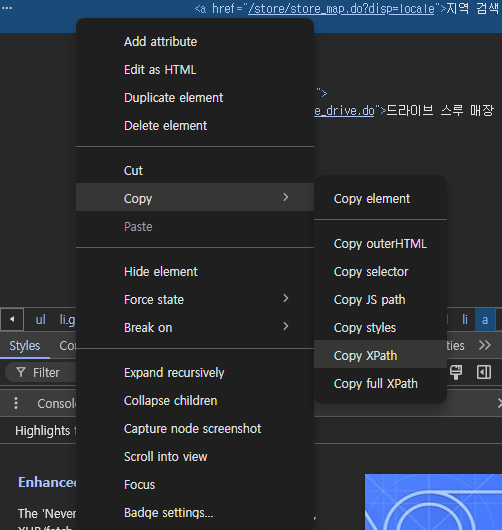
💡 XPath란?
HTML 또는 XML 문서의 구조를 통해 경로를 지정하여 특정 요소나 속성을 선택하기 위한 언어.
보통 다음과 같은 형식으로 사용합니다.
//div[@class='example']
(문서 내의 모든 경로에서 div 태그 중 class가 example인 요소)
// 지역 검색 요소를 찾아서 클릭
xpath = '//*[@id="gnb"]/div/nav/div/ul/li[3]/div/div/div/ul[1]/li[3]/a'
child_level_menu = driver.find_element(By.XPATH, xpath)
child_level_menu.click()
time.sleep(0.5)복사한 XPath를 find_element()의 인자로 입력하고 click() 메서드로 해당 요소를 클릭합니다.
3.7 코드 테스트
여기까지 작성한 후 코드를 실행해보겠습니다.

웹 사이트가 열리고

STORE 요소에 마우스를 갖다 댄 후 아래에 지역 검색 요소를 클릭
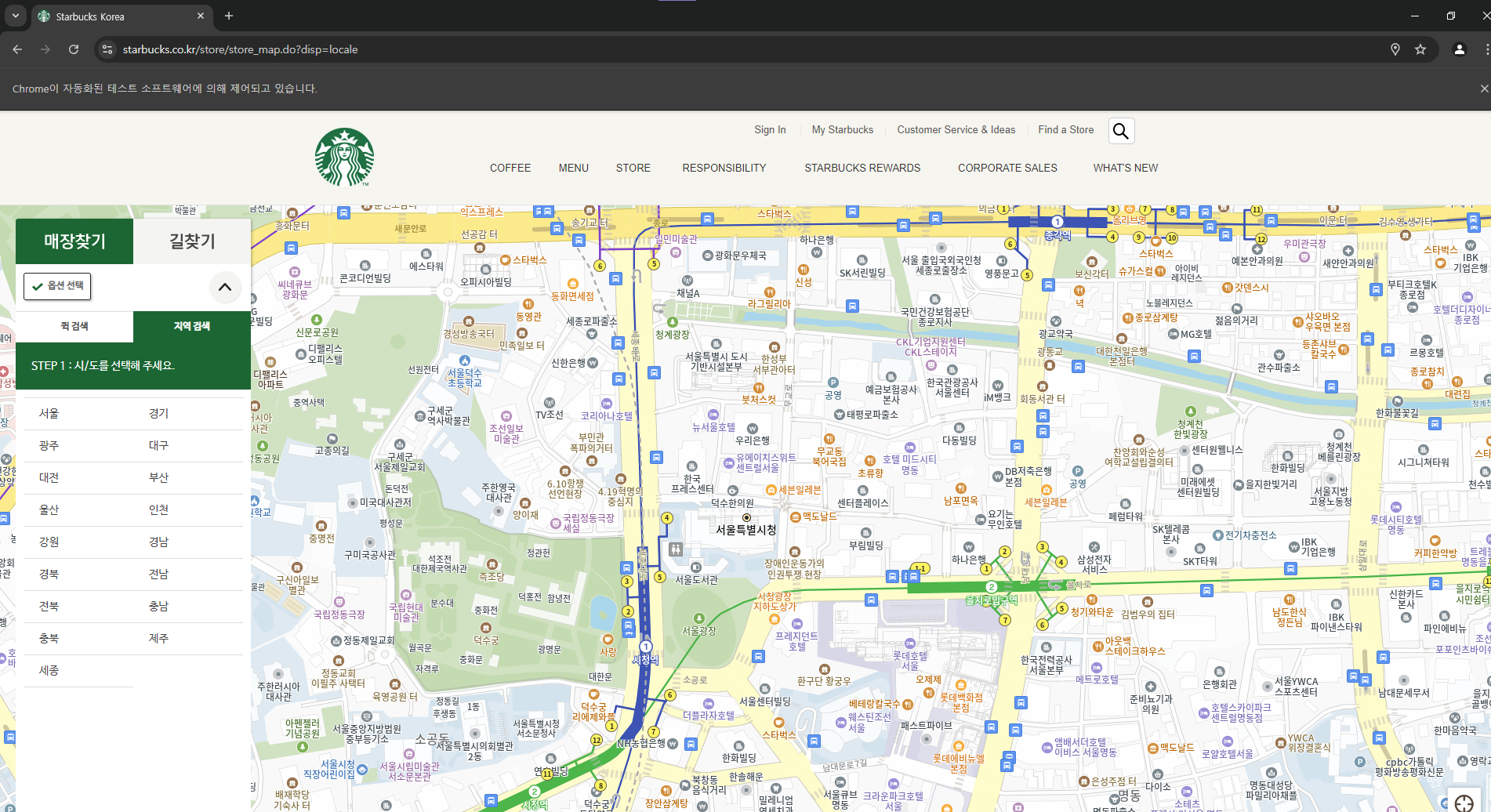
짠!
3.8 지역 지정
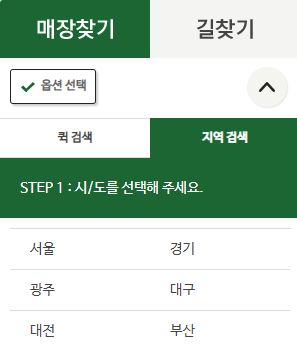
아까와 같은 방법으로 화면 왼쪽에 있는 서울 -> 전체 요소를 클릭하는 코드를 작성합니다.
//서울 버튼 클릭
xpath = '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'
seoul_btn = driver.find_element(By.XPATH, xpath)
seoul_btn.click()
time.sleep(0.5)
//전체 버튼 클릭
xpath = '//*[@id="mCSB_2_container"]/ul/li[1]/a'
all_btn = driver.find_element(By.XPATH, xpath)
all_btn.click()코드를 실행하면 아래와 같이 지점 정보를 확인할 수 있습니다.
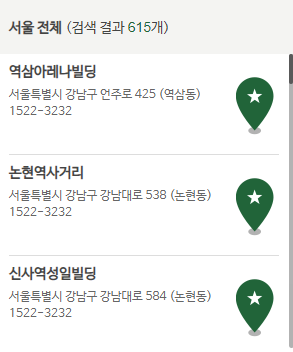
4. 정보 가져오기
4.1 HTML 파싱

전체 지점 중 첫 번째로 출력된 지점인 역삼아레나빌딩 지점을 가지고 정보를 가져오는 코드를 작성해보겠습니다.
우선 "전체" 버튼을 클릭했을 때 지점 정보가 로드되는데에 시간이 조금 소요가 되기 때문에 time.sleep()으로 2초 정도 딜레이를 주겠습니다.
그리고 현재 페이지의 HTML 소스를 불러와 BeautifulSoup() 함수로 HTML 구문을 파싱합니다.
time.sleep(2)
//현재 페이지의 HTML 전체 소스를 불러온다.
html = driver.page_source
//HTML, XML 구문 분석.
soup = BeautifulSoup(html, 'html.parser')
print(soup)soup을 출력해보면 HTML 요소들이 파싱되어 있는 것을 확인할 수 있습니다.
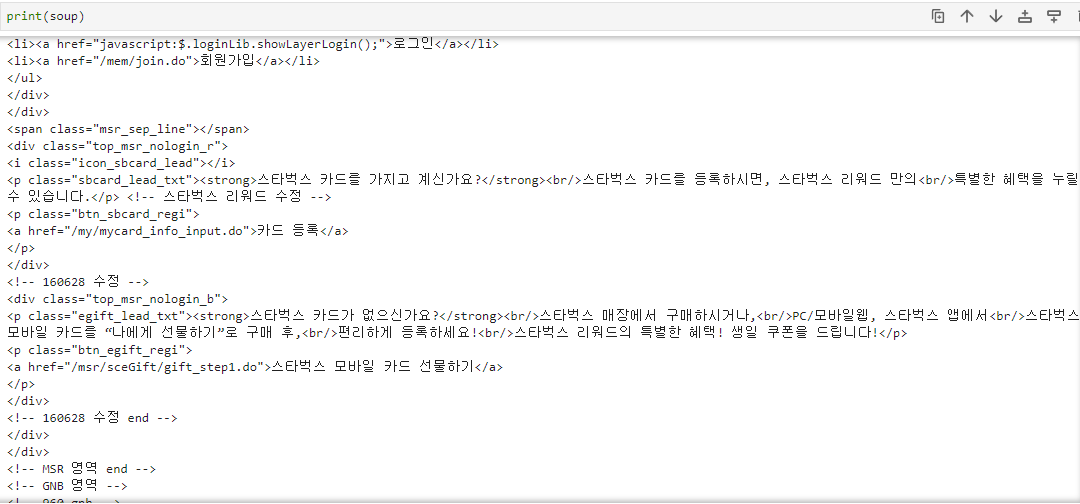
다시 검사 도구를 열고 지점 정보가 적힌 박스를 클릭해 보면 모든 지점들의 정보가 "quickResultLstCon"이라는 클래스로 묶여있습니다.

4.2 지점 정보 가져오기
BeautifulSoup의 select() 메서드를 사용해 클래스로 모든 지점 정보를 가져오겠습니다.
//서울지역 스타벅스 매장리스트를 저장한다.
starbucks_store_list = soup.select('li.quickResultLstCon')
print(starbucks_store_list)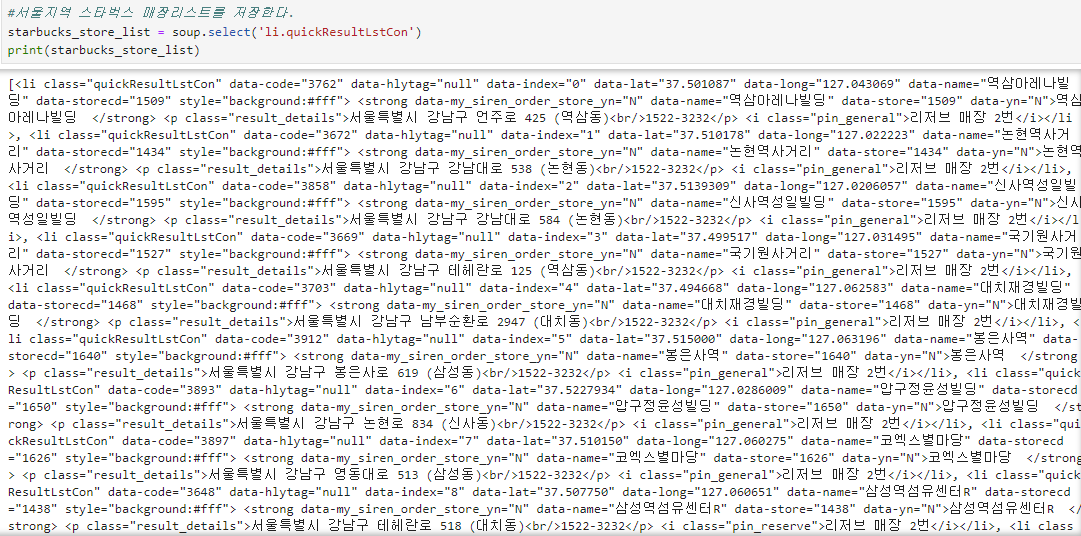
이 중에서 첫 번째 요소인 역삼아레나빌딩 지점만 선택.
#서울지역 스타벅스 매장리스트를 저장한다.
starbucks_store_list = soup.select('li.quickResultLstCon')
star_0 = starbucks_store_list[0]
print(star_0)
4.3 정보 추출
이제 총 6가지 정보를 추출해오겠습니다.
- 매장 이름
- 위도 정보
- 경도 정보
- 매장 타입
- 매장 주소
- 매장 전화
4.3.1 매장 이름
매장 이름은 <strong></strong> 태그로 감싸져 있습니다. select() 메서드에 태그 이름을 입력하면 해당 태그를 가져올 수 있습니다.
star_0.select('strong')
리스트 형식으로 반환되었으며 strong 태그는 하나 뿐입니다. 그래서 인덱스[0]으로 리스트에서 추출합니다.
star_0.select('strong')[0]
여기서 가져오고자 하는 '매장 이름'은 해당 태그의 Text 입니다. Text는 .text 메서드로 쉽게 가져올 수 있습니다.
star_0.select('strong')[0].text
출력된 결과를 보니 오른쪽에 공백이 포함되어 있습니다. 공백을 제거하는 strip()까지 붙여주면 끝.
star_0.select('strong')[0].text.strip()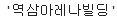
4.3.2 위도, 경도 추출
BeautifulSoup 객체는 데이터를 딕셔너리 형태로 저장하기 때문에 태그의 속성들은 data-lat : 37.501087과 같은 형태로 저장됩니다. 그래서 key 값으로 해당 속성의 값을 가져올 수 있습니다.
위도의 정보는 data-lat, 경도는 data-long 입니다.
//위도, 경도 정보 추출
print(star_0['data-lat'])
print(star_0['data-long'])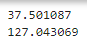
4.3.3 매장 타입
이제 나머지 정보들도 위에서 했던 것과 같은 방법으로 가져오겠습니다.
//매장 타입
print(star_0.select('i')[0]['class'][0][4:])매장 타입은 prn-xxx 형식이기 때문에 앞에서 5번째부터 가져옵니다.
4.3.4 매장 주소, 전화
매장 주소와 매장 전화는 p 태그의 텍스트로 함께 작성되어 있습니다. 그런데 자세히 보면 중간에 <br/> 태그가 포함된 것이 보입니다. 이 점을 이용해 <br/> 태그를 중심으로 split을 하면 가변적인 주소와 전화를 쉽게 가져올 수 있습니다.
하지만 지금까지 사용하던 .text 메서드는 중간에 있는 <br/> 태그를 생략하고 텍스트만 가져옵니다. 그래서 .text가 아닌 내부 HTML 태그를 문자열로 그대로 가져오는 .decode_contents() 메서드를 사용합니다.
print(star_0.select('p.result_details')[0].decode_contents())
이제 <br/> 태그를 기준으로 분리해 주소와 전화를 따로 가져옵니다.
Addr_And_CallNum = star_0.select('p.result_details')[0].decode_contents().split('<br/>')
//매장 주소
print(Addr_And_CallNum[0])
//매장 전화
print(Addr_And_CallNum[1])
4.4 전체 매장 정보 가져오기
이제 반복문을 사용해 모든 매장의 정보를 가져오도록 하겠습니다.
지금까지 작성한 코드를 보면


starbucks_store_list 변수에 모든 지점 정보를 담고, 그 중 첫 번째 요소인 역삼아레나빌딩 지점의 정보를 star_0 변수에 담아 데이터를 추출하였습니다. 그럼 간단하게 반복문을 통해서 starbucks_store_list의 요소를 순서대로 가져와 store 변수에 담고, 이전까지 사용한 star_0 대신에 store 변수로 대체해주면 끝이 납니다.
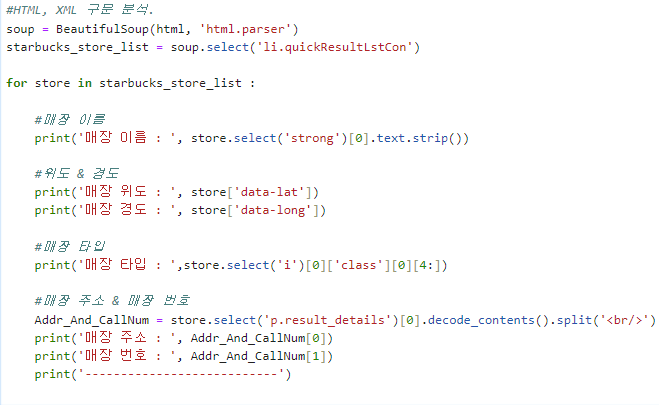

각 데이터를 정확하게 가져오는 것을 볼 수 있습니다.
5. 엑셀에 정보 저장하기
5.1 리스트에 정보 저장
우선 위에서 작성한 반복문 코드를 print()로 출력하는 것이 아닌 변수에 담고 모든 변수를 하나의 리스트에 저장합니다.
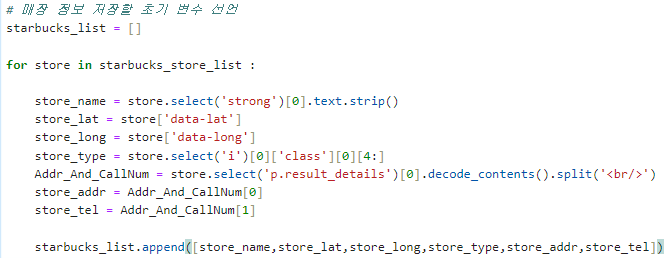
5.2 column 이름 지정
pandas 모듈을 import하고 columns 변수에 사용할column들의 이름을 지정해줍니다.
💡 pandas의 데이터 유형
- Series() : 1차원 데이터(배열)
- DataFrame() : 2차원 이상의 데이터(배열)

5.3생성된 파일 정보 확인
seoul_store_list_df.info()info() 메서드를 사용하면 생성된 파일의 정보를 확인할 수 있습니다.
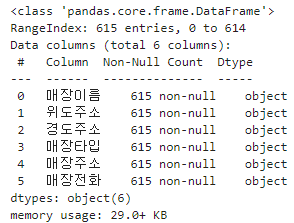
RangeIndex : 총 열의 개수
Column : column 이름
Data columns : column 개수
Non-Null Count : 각 열에 있는 유효한 값의 개수
Dtype : 각 column의 data type
💡 pandas 자료형(Data type)
- int : 정수
- float : 실수
- date : 날짜
- object : 문자열
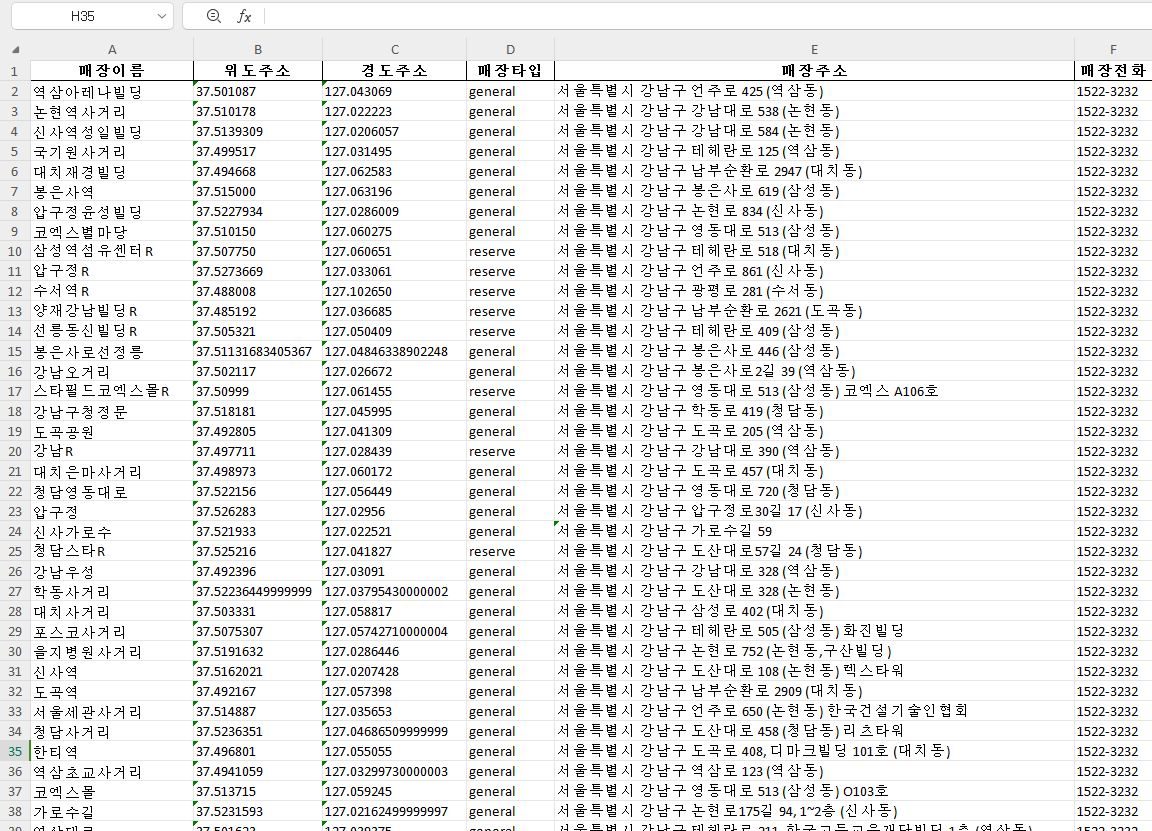
seoul_store_list_df.to_excel('스타벅스_서울_매장리스트.xlsx', index=False)to_excel() 메서드를 사용하면 가져온 데이터를 excel 파일로 저장할 수 있습니다.
파일이 생성된 후 코드를 한 번 더 실행하면 새로운 데이터가 똑같은 파일에 덮어쓰기 됩니다. 데이터가 추가되거나 갱신되었을 경우 코드만 한 번더 실행하면 됩니다.
excel이외에도 HTML, SQL, CSV 등 다양한 형식으로 저장이 가능합니다.
마지막으로 데이터를 전부 가져오면 웹 사이트를 종료하기 위해 코드를 한 줄 추가합니다.
driver.close()최종으로 완성된 코드는 다음과 같습니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import pandas as pd
import time
import warnings
#모든 경고 메시지 무시
warnings.filterwarnings(action='ignore')
#chrome 드라이버 등록 및 홈페이지 URL 지정
driver = webdriver.Chrome('chromedriver.exe')
url = 'https://www.starbucks.co.kr/index.do'
driver.maximize_window()
driver.get(url)
action = ActionChains(driver)
#요소 지정
parent_level_menu = driver.find_element(By.CLASS_NAME, "gnb_nav03")
#요소에 마우스 갖다 대기
action.move_to_element(parent_level_menu).perform()
time.sleep(0.5)
# 특정 요소를 찾아서 클릭
xpath = '//*[@id="gnb"]/div/nav/div/ul/li[3]/div/div/div/ul[1]/li[3]/a'
child_level_menu = driver.find_element(By.XPATH, xpath)
child_level_menu.click()
time.sleep(0.5)
xpath = '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'
seoul_btn = driver.find_element(By.XPATH, xpath)
seoul_btn.click()
time.sleep(0.5)
xpath = '//*[@id="mCSB_2_container"]/ul/li[1]/a'
all_btn = driver.find_element(By.XPATH, xpath)
all_btn.click()
time.sleep(2)
#현재 페이지의 HTML 전체 소스를 불러온다.
html = driver.page_source
#HTML, XML 구문 분석.
soup = BeautifulSoup(html, 'html.parser')
starbucks_store_list = soup.select('li.quickResultLstCon')
# 매장 정보 저장할 초기 변수 선언
starbucks_list = []
for store in starbucks_store_list :
store_name = store.select('strong')[0].text.strip()
store_lat = store['data-lat']
store_long = store['data-long']
store_type = store.select('i')[0]['class'][0][4:]
Addr_And_CallNum = store.select('p.result_details')[0].decode_contents().split('<br/>')
store_addr = Addr_And_CallNum[0]
store_tel = Addr_And_CallNum[1]
starbucks_list.append([store_name,store_lat,store_long,store_type,store_addr,store_tel])
## 엑셀 컬럼의 이름 지정
columns = ['매장이름','위도주소','경도주소','매장타입','매장주소','매장전화']
seoul_store_list_df = pd.DataFrame(starbucks_list, columns = columns)
#데이터를 엑셀파일로 저장
#파일 저장 시 인덱스 번호가 자동 삽입되므로 index=False를 사용해 인덱스를 삽입하지 않는다.
seoul_store_list_df.to_excel('스타벅스_서울_매장리스트.xlsx', index=False)
#웹 사이트 닫기
driver.close()이제 py 파일을 클릭하기만하면 스타벅스 서울 전체 매장 정보가 Excel 파일로 저장됩니다.
