
1. 데이터 분석 개요
ANSI/ISO SQL 표준은 데이터 분석을 위해서 다음 세 가지 함수를 정의하고 있다.
- AGGERGATE FUNCTION
- GROUP FUNCTION
- WINDOW FUNCTION
AGGERGATE FUNCTION
GROUP AGGREGATE FUNCTION이라고도 부르며, GROUP FUNCTION의 한 부분으로 분류할 수 있다.
COUNT, SUM, AVG, MAX, MIN 외 각종 집계 함수들이 포함되어 있다.
GROUP FUNCTION
결산 개념의 업무를 가지는 원가나 판매 시스템의 경우는 소계, 중계, 합계, 총 합계 등 여러 레벨의 결산 보고서를 만드는 것이 중요 업무 중의 하나이다.
개발자들이 이런 보고서를 작성하기 위해서는 SQL이 포함된 3GL으로 배치 프로그램을 작성하거나, 레벨별 집계를 위한 여러 단계의 SQL을 UNION, UNION ALL로 묶은 후 하나의 테이블을 여러 번 읽어 다시 재정렬하는 복잡한 단계를 거쳐야 했다.
그러나 그룹 함수를 사용한다면 하나의 SQL로 테이블을 한 번만 읽어서 빠르게 원하는 리포트를 작성할 수 있다.
추가로, 소계/합계를 표시하기 위해 GROUPING 함수와 CASE 함수를 이용하면 쉽게 원하는 포맷의 보고서 작성도 가능하다.
그룹 함수로는 집계 함수를 제외하고
소그룹 간의 소계를 계산하는 ROLLUP 함수,
GROUP BY 항목들 간 다차원적인 소계를 계산 할 수 있는 CUBE 함수,
특정 항목에 대한 소계를 계산하는 GROUPING SETS 함수가 있다.
ROLLUP은 GROUP BY의 확장된 형태로 사용하기가 쉬우며 병렬로 수행이 가능하기 때문에 매우 효과적일 뿐 아니라 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하도록 되어 있다.
CUBE는 결합 가능한 모든 값에 대하여 다차원적인 집계를 생성하게 되므로 ROLLUP에 비해 다양한 데이터를 얻는 장점이 있는 반면에, 시스템에 부하를 많이 주는 단점이 있다.
GROUPING SETS는 원하는 부분의 소계만 손쉽게 추출할 수 있는 장점이 있다.
ROLLUP, CUBE, GROUPING SETS 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 정렬 칼럼을 명시해야 한다.
WINDOW FUNCTION
분석 함수(ANALYTIC FUNCTION)나 순위 함수(RANK FUNCTION)로도 알려져 있는 윈도우 함수는 데이터웨어하우스에서 발전한 기능이다.
2. ROLLUP 함수
ROLLUP에 지정된 Grouping Columns의 List는 Subtotal을 생성하기 위해 사용되어지며, Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성된다. 중요한 것은, ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 되므로 인수의 순서에도 주의해야 한다.
ROLLUP과 CUBE의 효과를 알아보기 위해 단계별로 알아보자.
STEP 1. 일반적인 GROUP BY 절 사용
-- 부서명과 업무명을 기준으로 사원수와 급여 합을 집계한
-- 일반적인 GROUP BY SQL 문장을 수행한다.
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB;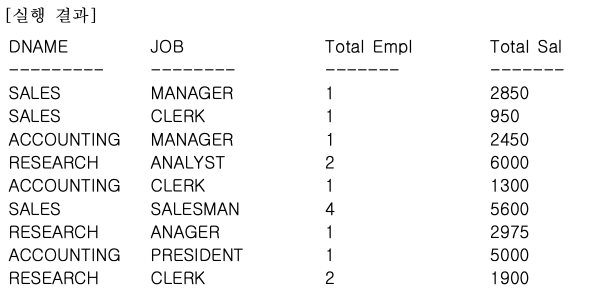
STEP 1-2. GROUP BY 절 + ORDER BY 절 사용
-- 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에
-- ORDER BY 절을 사용함으로써 부서, 업무별로 정렬이 이루어진다.
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
ORDER BY DNAME, JOB;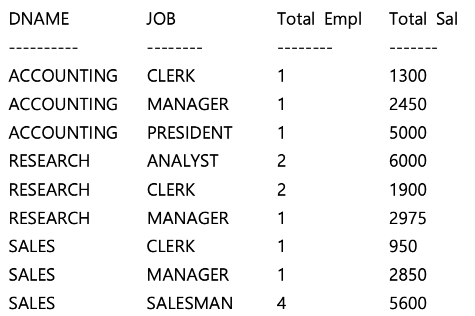
STEP 2. ROLLUP 함수 사용
-- 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에
-- ROLLUP 함수를 사용한다.
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);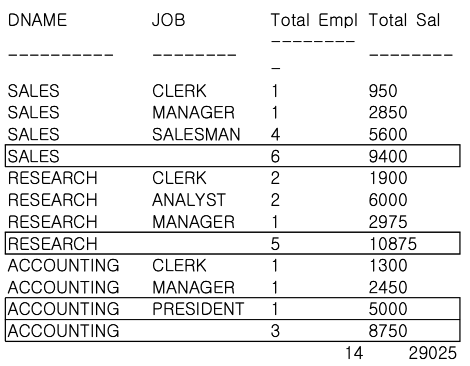
SQL 문장에 의하여 다음과 같은 추가 LEVEL의 집계가 생성된다.
- L1 - GROUP BY 수행시 생성되는 표준 집계
- L2 - DNAME 별 모든 JOB의 SUBTOTAL
- L3 - GRAND TOTAL
추가로 ROLLUP의 경우 계층 간 집계에 대해서는 LEVEL 별 순서(L1->L2->L3)를 정렬하지만,
계층 내 GROUP BY 수행시 생성되는 표준 집계에는 별도의 정렬을 지원하지 않는다.
L1, L2, L3 계층 내 정렬을 위해서는 별도의 ORDER BY 절을 사용해야 한다.
STEP 2-2. ROLLUP 함수 + ORDER BY 절 사용
-- 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에
-- ROLLUP 함수를 사용한다.
-- 추가로 ORDER BY 절을 사용해서 부서, 업무별로 정렬한다.
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
ORDER BY DNAME, JOB;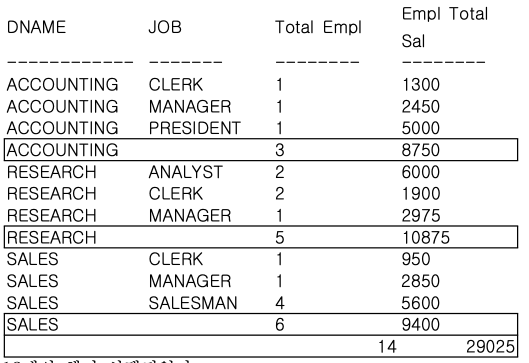
STEP 3. GROUPING 함수 사용
ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가되었다.
ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1 이 표시그 외의 결과에는 GROUPING(EXPR) = 0 이 표시- 특정 칼럼이 그룹화에 포함된 결과에는 GROUPING(EXPR) = 0이 표시됩니다.
- 특정 칼럼이 그룹화에서 제외된 결과에는 GROUPING(EXPR) = 1이 표시됩니다.
GROUPING 함수와 CASE/DECODE를 이용해, 소계를 나타내는 필드에 원하는 문자열을 지정할 수 있어, 보고서 작성시 유용하게 사용할 수 있다.
-- ROLLUP 함수를 추가한 집계 보고서에서
-- 집계 레코드를 구분할 수 있는 GROUPING 함수가 추가된 SQL 문장이다.
SELECT
DNAME,
GROUPING(DNAME),
JOB,
GROUPING(JOB),
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);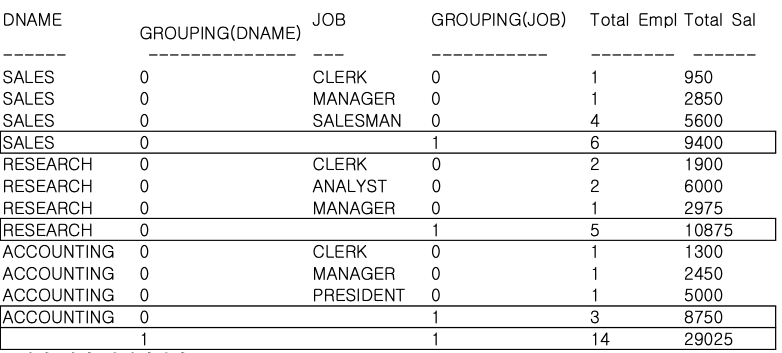
부서별, 업무별과 전체 집계를 표시한 레코드에서는 GROUPING 함수가 1을 리턴한 것을 확인할 수 있다.
그리고 전체 합계를 나타내는 결과 라인에서는 부서별 GROUPING 함수와 업무별 GROUPING 함수가 둘 다 1인 것을 알 수 있다.
STEP 4. GROUPING 함수 + CASE 사용
-- ROLLUP 함수를 추가한 집계 보고서에 집계 레코드를 구분할 수 있는
-- GROUPING 함수와 CASE 함수를 함계 사용한 SQL 문장을 작성한다.
SELECT
CASE GROUPING(DNAME)
WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
-- Oracle - DECODE 사용
SELECT
DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);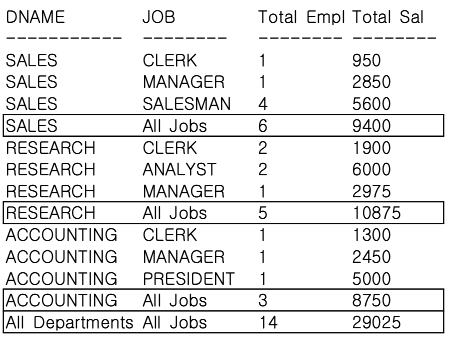
STEP 4-2. ROLLUP 함수 일부 사용
-- GROUP BY ROLLUP (DNAME, JOB) 조건에서 GROUP BY DNAME, ROLLUP(JOB) 조건으로 변경한 경우이다.
SELECT
CASE GROUPING(DNAME)
WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY DNAME ROLLUP (JOB);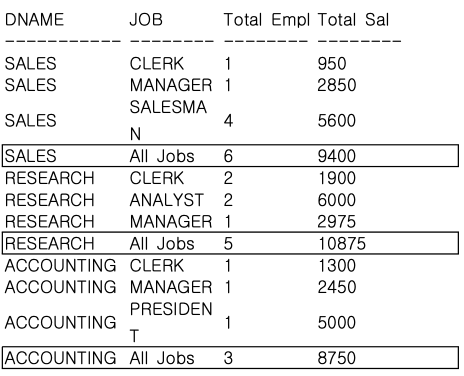
결과는 마지막 ALL DEPARTMENTS & ALL JOBS 줄만 계산이 되지 않았다. ROLLUP이 JOB 칼럼에만 사용되었기 때문에 DNAME에 대한 집계는 필요하지 않기 때문이다.
STEP 4-3. ROLLUP 함수 결합 칼럼 사용
-- JOB과 MGR는 하나의 집합으로 간주하고,
-- 부서별, JOB & MGR에 대한 ROLLUP 결과를 출력한다.
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, (JOB, MGR));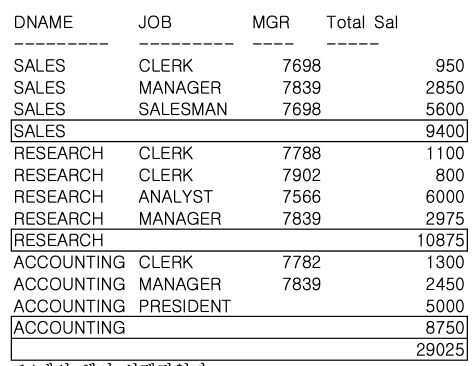
ROLLUP 함수 사용시 괄호로 묶은 JOB과 MGR의 경우 하나의 집합(JOB+MGR) 칼럼으로 간주하여 괄호 내 각 칼럼별 집계를 구하지 않는다.
3. CUBE 함수
ROLLUP에서는 단지 가능한 Subtotal만을 생성하였지만
CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
CUBE를 사용할 경우에는 내부적으로 Grouping Columns의 순서를 바꾸어서 또 한번의 Query를 추가 수행해야 한다. 뿐만 아니라 Grand Total은 양쪽의 Query 에서 모두 생성이 되므로 한 번의 Query에서는 제거되어야만 하므로 ROLLUP에 비해 시스템의 연산 대상이 많다.
이처럼 Grouping Columns이 가질 수 있는 모든 경우에 대하여 Subtotal을 생성해야 하는 경우에는 CUBE를 사용하는 것이 바람직하나, ROLLUP에 비해 시스템에 많은 부담을 주므로 사용에 주의해야 한다.
CUBE 함수의 경우 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔 수 있어도 데이터 결과는 같다.
그리고 CUBE도 결과에 대한 정렬이 필요한 경우에는 ORDER BY 절에 명시적으로 정렬 칼럼이 표시가 되어야 한다.
STEP 5. CUBE 함수 이용
-- GROUP BY ROLLUP (DNAME, JOB) 조건에서 GROUP BY CUBE (DNAME, JOB) 조건으로 변경해서 수행한다.
SELECT
CASE GROUPING(DNAME)
WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB);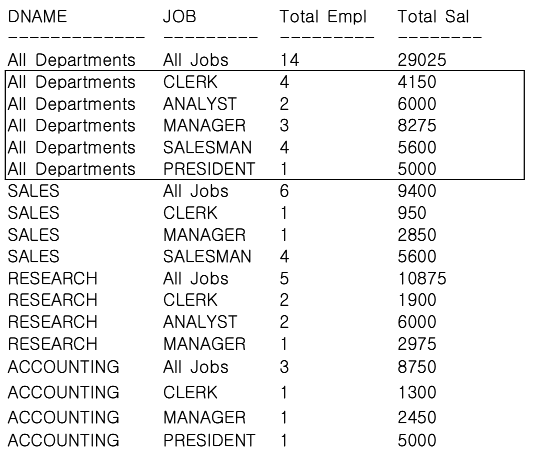
CUBE는 GROUPING COLUMNS이 가질 수 있는 모든 경우의 수에 대하여 Subtotal을 생성하므로 GROUPING COLUMS의 수가 N이라고 가정하면, 2의 N승 LEVEL의 Subtotal을 생성하게 된다.
실행 결과에서 CUBE 함수 사용으로 ROLLUP 함수의 결과에다 업무별 집계까지 추가해서 출력할 수 있는데, ROLLUP 함수에 비해 업무별 집계를 표시한 5건의 레코드가 추가된 것을 확인할 수 있다.
5-2. UNION ALL 사용 SQL
UNION ALL은 Set Operation 내용으로, 여러 SQL 문장을 연결하는 역할을 할 수 있다.
다음 SQL은 첫 번째 SQL 모듈로부터 차례대로 결과가 나오므로 위 CUBE SQL과 결과 데이터는 같으나 행들의 정렬은 다를 수 있다.
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT
DNAME,
'All Jobs',
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT
'All Departments',
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO
GROUP BY JOB
UNION ALL
SELECT
'All Departments',
'All Jobs',
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE DEPT. DEPTNO = EMP.DEPTNO;CUBE 함수를 사용하면서 가장 크게 개선되는 부분은 CUBE 사용 전 SQL에서 EMP, DEPT 테이블을 네 번이나 반복 엑세스하는 부분을 CUBE 사용 SQL에서는 한 번으로 줄일 수 있는 부분이다.
기존에 같은 테이블을 네 번 엑세스하는 이유가 되었던 부서와 업무별 소계와 총계 부분을 CUBE 함수를 사용함으로써 한 번의 엑세스만으로 구현한다.
결과적으로 수행속도 및 자원 사용율을 개선할 수 있으며, SQL 문장도 더 짧아졌으므로 가독성도 높아졌다.
4. GROUPING SETS 함수
GROUPING SETS를 이용해 더욱 다양한 소계 집합을 만들 수 있는데, GROUP BY SQL 문장을 여러 번 반복하지 않아도 원하는 결과를 쉽게 얻을 수 있게 되었다.
GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
그리고 GROUPING SETS 함수도 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬 칼럼이 표시가 되어야 한다.
일반 그룹함수를 이용한 SQL
-- 일반 그룹함수를 이용하여 부서별, JOB별 인원수와 급여 합을 구하라.
SELECT
DNAME,
'ALL JOBS' JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT
'All Departments' DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY JOB;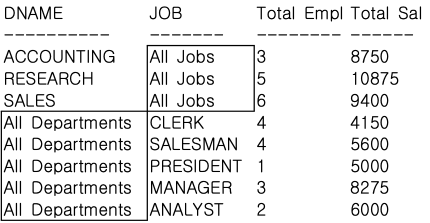
실행 결과는 별도의 ORDER BY 조건을 명시하지 않았기 때문에 DNAME이나 JOB에 대해서 정렬이 되어 있지 않다.
GROUPING SETS 사용 SQL
-- 일반 그룹함수를 GROUPING SETS 함수로 변경하여
-- 부서별, JOB별 인원수와 급여합을 구하라.
SELECT
CASE GROUPING(DNAME)
WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);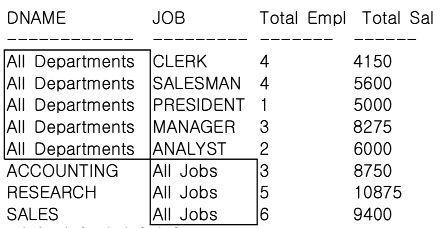
GROUPING SETS 함수 사용시 UNION ALL을 사용한 일반 그룹함수를 사용한 SQL과 같은 결과를 얻을 수 있으며, 괄호로 묶은 집합 별로(괄호 내는 계층 구조가 아닌 하나의 데이터로 간주) 집계를 구할 수 있다. GROUPING SETS의 경우 일반 그룹함수를 이용한 SQL과 결과 데이터는 같으나 행들의 정렬 순서는 다를 수 있다.
GROUPING SETS 사용 SQL - 순서변경
-- 일반 그룹함수를 GROUPING SETS 함수로 변경하여
-- 부서별, JOB별 인원수와 급여합을 구하는데
-- GROUPING SETS의 인수들의 순서를 바꾸어 본다.
SELECT
CASE GROUPING(DNAME)
WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY GROUPING SETS (JOB, DNAME);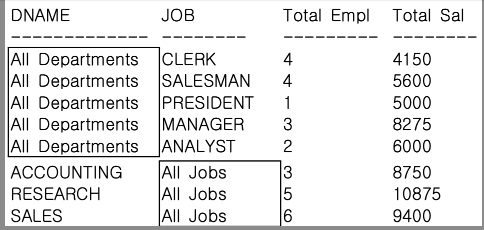
GROUPING SERTS 인수들은 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
3개의 인수를 이용한 GROUPING SETS 이용
-- 부서-JOB-매니저 별 집계와
-- 부서-JOB 별 집계와,
-- JOB-매니저 별 집계를
-- GROUPING SETS 함수를 이용해서 구해본다.
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM
EMP,
DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY GROUPING SETS (
(DNAME, JOB, MGR),
(DNAME, JOB),
(JOB, MGR)
);GROUPING SETS 함수 사용시 괄호로 묶은 집합별로(괄호 내는 계층구조가 아닌 하나의 데이터로 간주함) 집계를 구할 수 있다.
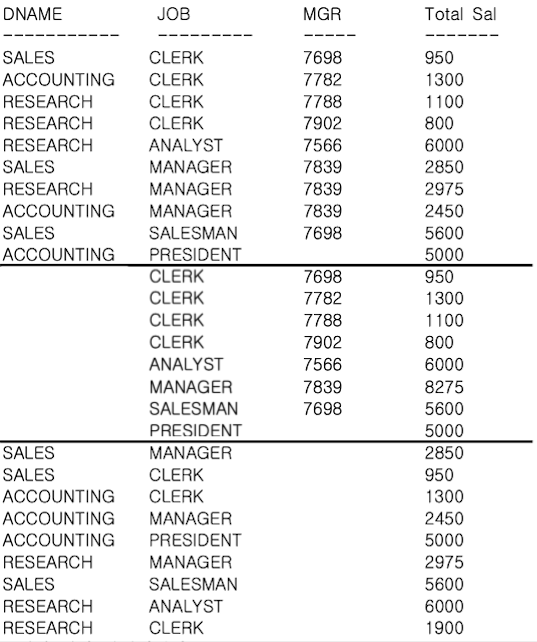
실행 결과에서 첫 번째 10건의 데이터는 (DNAME + JOB + MGR) 기준의 집계이며, 두 번째 8건의 데이터는 (JOB + MGR) 기준의 집계이며, 세 번째 9건의 데이터는 (DNAME + JOB) 기준의 집계이다.
