
1. JOIN 개요
두 개 이상의 테이블 들을 연결 또는 결합하여 데이터를 출력하는 것을 JOIN이라고 하며, 일반적으로 사용되는 SQL 문장의 상당수가 JOIN이라고 생각하면 JOIN의 중요성을 이해하기 쉬울 것이다.
JOIN은 관계형 데이터베이스의 가장 큰 장점이면서 대표적인 핵심 기능이라고 할 수 있다.
일반적인 경우 행들은 PRIMARY KEY(PK)나 FOREIGN KEY(FK) 값의 연관에 의해 JOIN이 성립된다. 하지만 어떤 경우에는 이러한 PK, FK의 관계가 없어도 논리적인 값들의 연관만으로 JOIN이 성립 가능하다.
A, B, C, D 4개의 테이블을 조인하고자 할 경우 옵티마이저는 ( ( (A JOIN D) JOIN C) JOIN B)와 같이 순차적으로 조인을 처리하게 된다.
이때 테이블의 조인 순서는 옵티마이저에 의해서 결정되고 주요 튜닝 포인트가 된다.
2. EQUI JOIN
EQUI(등가) JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하는 경우에 사용되는 방법으로 대부분 PK ↔︎ FK의 관계를 기반으로 한다.
그러나 일반적으로 테이블 설계 시에 나타난 PK ↔︎ FK의 관계를 이용하는 것이지 반드시 PK ↔︎ FK의 관계로만 EQUI JOIN이 성립하는 것은 아니다.
이 기능은 계층형(Hierarchical)이나 망형(Network)데이터베이스와 비교해서 관계형 데이터베이스의 큰 장점이다.
JOIN의 조건은 WHERE 절에 기술하게 되는데 "~" 연산자를 사용해서 표현한다.
-- EQUI JOIN의 대략적인 형태
SELECT 테이블1.칼럼명, 테이블2.칼럼명, …
FROM 테이블1, 테이블2
WHERE 테이블1.칼럼명1 = 테이블2.칼럼명2;
→ WHERE 절에 JOIN 조건을 넣는다.
-- ANSI/ISO SQL 표준 방식
SELECT 테이블1.칼럼명, 테이블2.칼럼명, …
FROM 테이블1 INNER JOIN 테이블2
ON 테이블1.칼럼명1 = 테이블2.컬럼명2;
→ ON 절에 JOIN 조건을 넣는다.SELECT 구문에 단순히 칼럼명이 오지 않고 "테이블명.칼럼명"처럼 테이블명과 칼럼명이 같이 나타난다. 이렇게 특정 칼럼에 접근하기 위해 그 칼럼이 어느 테이블에 존재하는 칼럼인지를 명시하는 것은 두 가지 이유가 있다.
먼저 모든 테이블에 칼럼들이 유일한 이름을 가진다면 상관없지만, JOIN에 사용되는 두 개의 테이블에 같은 칼럼명이 존재하는 경우에는 DBMS의 옵티마이저는 어떤 칼럼을 사용해야 할지 모르기 때문에 파싱 단계에서 에러가 발생한다.
두 번째는 개발자나 사용자가 조회할 데이터가 어느 테이블에 있는 칼럼을 말하는 것인지 쉽게 알 수 있게 하므로 SQL에 대한 가독성이나 유지보수성을 높이는 효과가 있다.
조인 조건에 맞는 데이터만 출력하는 INNER JOIN에 참여하는 대상 테이블이 N개라고 했을 때, N개의 테이블로부터 필요한 데이터를 조회하기 위해 필요한 JOIN 조건은 대상 테이블의 개수에서 하나를 뺀 N-1개 이상이 필요하다.
즉 FROM 절에 테이블이 3개가 표시되어 있다면 JOIN 조건은 3-1=2개 이상이 필요하며, 테이블이 4개가 표시되어 있다면 JOIN 조건은 4-1=3개 이상이 필요하다.
(옵티마이저의 발전으로 옵티마이저가 일부 JOIN 조건을 실행계획 수립 단계에서 추가할 수도 있지만, 예외적인 사항이다.)
JOIN 조건은 WHERE 절에 기술하며, JOIN은 두 개 이상의 테이블에서 필요한 데이터를 출력하기 위한 가장 기본적인 조건이다.
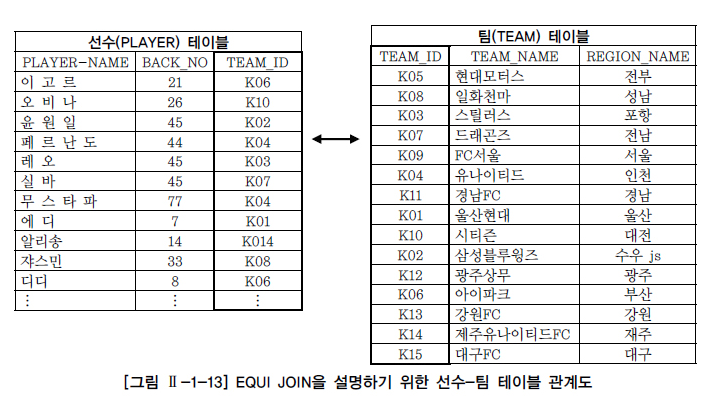
가. 선수-팀 EQUI JOIN 사례
요구사항
선수(PLAYER) 테이블과 팀(TEAM) 테이블에서 K-리그 소속 선수들의 이름, 백넘버와 그 선수가 소속되어 있는 팀명 및 연고지 출력
SELECT
P.PLAYER-NAME 선수명,
P.BACK_NO 백넘버,
T.TEAM_NAME 팀이름,
T.REGION_NAME 연고지
FROM
PLAYER AS P,
TEAM AS T
WHERE P.TEAM_ID = T.TEAM_ID
SELECT
P.PLAYER-NAME 선수명,
P.BACK_NO 백넘버,
T.TEAM_NAME 팀이름,
T.REGION_NAME 연고지
FROM PLAYER AS P
INNER JOIN TEAM
ON P.TEAM_ID = T.TEAM_ID나. 선수-팀 WHERE 절 검색 조건 사례
EQUI JOIN의 최소한의 연관 관계를 위해서 테이블 개수 - 1개의 JOIN 조건을 WHERE 절에 명시하고, 부수적인 제한 조건을 논리 연산자를 통하여 추가로 입력하는 것이 가능하다.
요구사항
위 SQL 문장의 WHERE 절에 포지션이 골기퍼인(골키퍼에 대한 포지션 코드는 'GK'임) 선수들에 대한 데이터만을 백넘버 순으로 출력
SELECT
P.PLAYER-NAME 선수명,
P.BACK_NO 백넘버,
T.TEAM_NAME 팀이름,
T.REGION_NAME 연고지
FROM
PLAYER AS P,
TEAM AS T
WHERE P.TEAM_ID = T.TEAM_ID
AND P.POSITION = 'GK'
ORDER BY P.BACK_NO;
SELECT
P.PLAYER-NAME 선수명,
P.BACK_NO 백넘버,
T.TEAM_NAME 팀이름,
T.REGION_NAME 연고지
FROM PLAYER AS P
INNER JOIN TEAM
ON P.TEAM_ID = T.TEAM_ID
WHERE P.POSITION = 'GK'
ORDER BY P.BACK_NO;JOIN 조건을 기술할 때 주의해야 할 사항이 한 가지 있다.
만약 테이블에 대한 ALIAS를 적용해서 SQL 문장을 작성했을 경우, WHERE 절과 SELECT 절에는 테이블명이 아닌 테이블에 대한 ALIAS를 사용해야 한다는 점이다.
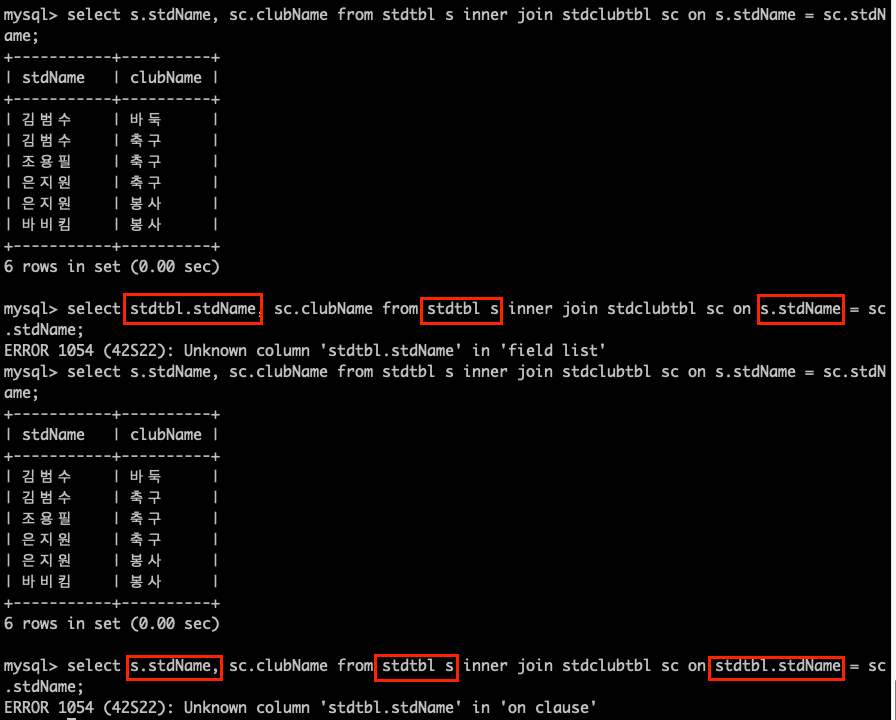

궁금하기
옵티마이저의 작업순서는 일반적으로 FROM -> WHERE -> SELECT 이지만,
위의 사진을 보면 SELECT에서 오류를 먼저 잡는다.
이유는 SQL엔진은 쿼리를 실행하기 전에 전체적인 문법검사를 한다. 그래서 WHERE를 가기도 전에 SELECT의 오류를 발견하기 때문에 SELECT에서 오류를 잡는다.
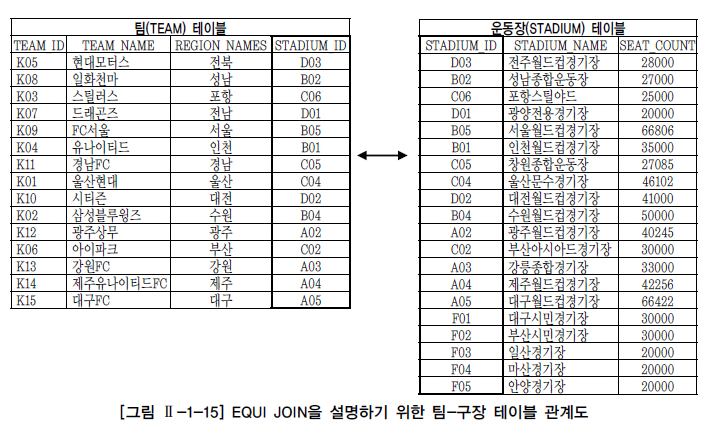
다. 팀-구장 EQUI JOIN 사례
요구사항
팀(TEAM) 테이블과 구장(STADIUM) 테이블의 관계를 이용해서 소속팀이 가지고 있는 전용구장의 정보를 팀의 정보와 함께 출력
SELECT *
FROM
TEAM T,
STADIUM S
WHERE T.STADIUM_ID = S.STADIUM_ID
SELECT *
FROM TEAM T
INNER JOIN STADIUM S
ON T.STADIUM_ID = S.STADIUM_ID3. Non EQUI JOIN
Non EQUI(비등가) JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에 사용된다. Non EQUI JOIN의 경우에는 "=" 연산자가 아닌 다른(Between, >, >=, <, <= 등) 연산자들을 사용하여 JOIN을 수행하는 것이다.
두 개의 테이블이 PK-FK로 연관관계를 가지거나 논리적으로 같은 값이 존재하는 경우에는 "=" 연산자를 이용하여 EQUI JOIN을 사용한다. 그러나 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에는 EQUI JOIN을 사용할 수 없다. 이런 경우 Non EQUI JOIN을 시도할 수 있으나 데이터 모델에 따라서 Non EQUI JOIN이 불가능한 경우도 있다.
SELECT 테이블1.칼럼명, 테이블2.칼럼명, …
FROM 테이블1, 테이블2
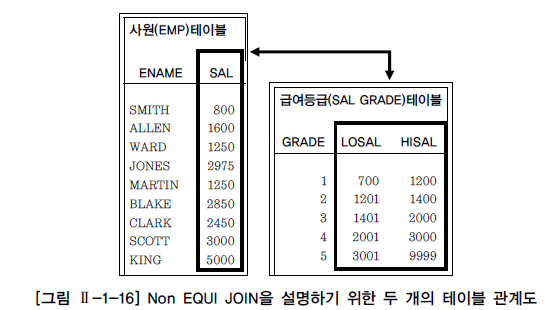
WHERE 테이블1.칼럼명1 BETWEEN 테이블2.칼럼명1 AND 테이블2.칼럼명2;요구사항
어떤 사원이 받고 있는 급여가 어느 등급에 속하는 등급인지 알고 싶다.
SELECT
E.ENAME,
SG.GRADE
FROM
EMP E,
SAL_GRADE SG
WHERE E.SAL BETWEEN SG.LOSAL AND SG.HISAL;
SELECT
E.ENAME,
SG.GRADE
FROM EMP E
INNER JOIN SAL_GRADE SG
ON E.SAL BETWEEN SG.LOSAL AND SG.HISAL;BETWEEN a AND b와 같은 SQL 연산자 뿐만 아니라 "=" 연산자가 아닌 ">"나 "<"와 같은 다른 연산자를 사용했을 경우에도 모두 Non EQUI JOIN에 해당한다. 단지 BETWEEN SQL 연산자가 Non EQUI JOIN을 설명하기 쉽기 때문에 예를 들어 설명한 것에 불과하며, 데이터 모델에 따라서 Non EQUI JOIN이 불가능한 경우도 있다.
4. 3개 이상 TABLE JOIN
요구사항
선수들 별로 홈그라운드 경기장이 어디인지를 출력
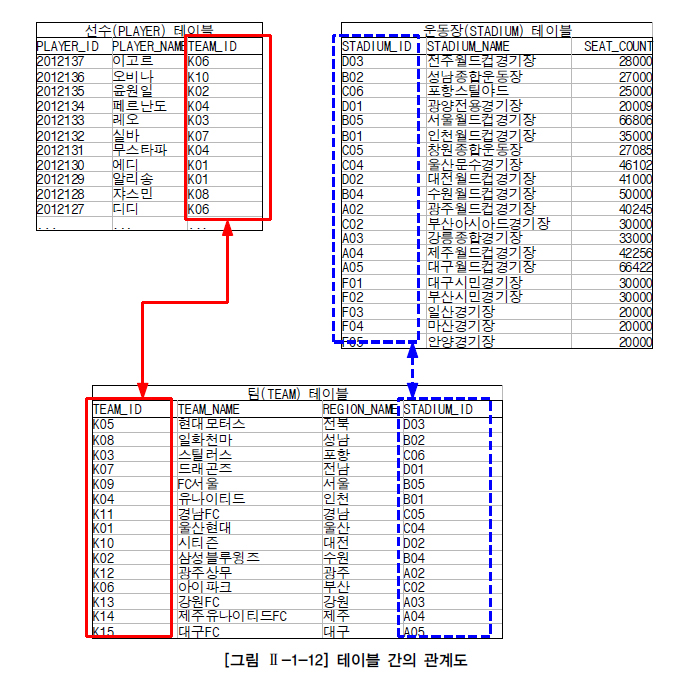
SELECT
P.PLAYER_NAME,
TS.STDIUM_NAME
FROM PLAYER P
INNER JOIN
(SELECT
T.TEAM_ID,
S.STADIUM_NAME
FROM TEAM T
INNER JOIN STADIUM S
ON T.STADIUM_ID = S.STADIUM_ID) AS TS
ON P.TEAM_ID = TS.TEAM_ID;
SELECT
P.PLAYER_NAME,
S.STDIUM_NAME
FROM PLAYER P
INNER JOIN TEAM T
ON P.TEAM_ID = T.TEAM_ID
INNER JOIN STADIUM S
ON T.STADIUM_ID = S.STADIUM_ID
SELECT
P.PLAYER_NAME,
S.STDIUM_NAME
FROM
PLAYER P,
TEAM T,
STADIUM S
WHERE P.TEAM_ID = T.TEAM_ID
AND T.STADIUM_ID = S.STADIUM_ID
JOIN이 필요한 기본적인 이유는 정규화에서부터 출발한다.
정규화
불필요한 데이터의 정합성을 확보하고 이상현상(Anomaly) 발생을 피하기 위해, 테이블을 분할하여 생성하는 것이다.
데이터웨어하우스 모델처럼 하나의 테이블에 모든 데이터를 집중시켜놓고 그 테이블로부터 필요한 데이터를 조회할 수도 있다.
그러나 이렇게 됐을 경우, 가장 중요한 데이터의 정합성에 더 큰 비용을 지불해야 하며, 데이터를 추가, 삭제, 수정하는 작업 역시 상당한 노력이 요구될 것이다.
성능 측면에서도 간단한 데이터를 조회하는 경우에도 규모가 큰 테이블에서 필요한 데이터를 찾아야 하기 때문에 오히려 검색 속도가 떨어질 수도 있다.
테이블을 정규화하여 데이터를 분할하게 되면 위와 같은 문제는 자연스럽게 해결 된다.
그렇지만 특정 요구조건을 만족하는 데이터들을 분할된 테이블로부터 조회하기 위해서는 테이블 간에 논리적인 연관관계가 필요하고 그런 관계성을 통해서 다양한 데이터들을 출력할 수 있는 것이다. 그리고, 이런 논리적인 관계를 구체적으로 표현하는 것이 바로 SQL 문장의 JOIN 조건인 것이다.
관계형 데이터베이스의 큰 장점이면서, SQL 튜닝의 중요 대상이 되는 JOIN을 잘못 기술하게 되면 시스템 자원 부족이나 과다한 응답시간 지연을 발생시키는 중요 원인이 되므로 JOIN 조건은 신중하게 작성해야 한다.
